

Google-KI beherrscht selektives Hören
Softwareentwickler bei Google haben ein Verfahren entwickelt, das aus der Tonspur eines Videos die Worte eines bestimmten Sprechers extrahiert. So lassen sich andere Redner oder Hintergrundgeräusche ausblenden.
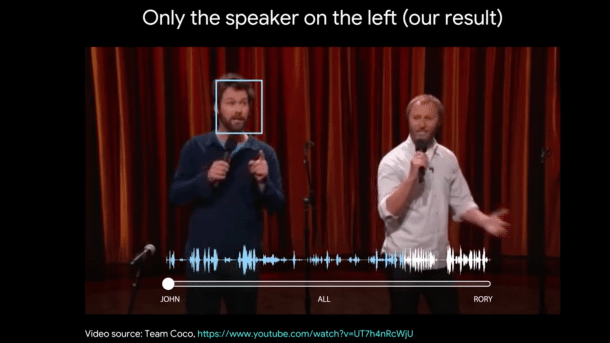
(Bild: Miki Rubinstein (Screenshot aus Video "Looking to Listen: Stand-up"))
Softwareentwickler bei Google haben ein Deep-Learning-Modell entwickelt, das aus Videos einzelne Sprecher isolieren kann. Dazu beobachtet das System die Mundbewegungen der gewünschten Person und extrahiert aus den Audiodaten nur deren Worte, während andere Geräusche und Sprecher ausgeblendet sind – vergleichbar dem sogenannten Cocktail-Party-Effekt (auch selektives Hören), bei dem das menschliche Gehirn durch Konzentration auf einen Sprecher einer Unterhaltung auch in einer relativ lauten Umgebung folgen kann. Darüber berichten die Forscher in einem Google-Research-Blogbeitrag.

(Bild: looking-to-listen.github.io)
Mundbewegungen und Worte zusammenbringen
Die insgesamt acht Autoren stellen in ihrem Paper "Look to Listen at the Cocktail Party" einen neuen Ansatz vor, Sprache eines Sprechers von anderer Sprache und Hintergrundgeräuschen zu isolieren (dort finden sich auch mehr Details dazu, wie Audio- und Videostreams zerlegt und verbunden werden). Geräuschunterdrückung etwa bei Kopfhörern und Headsets ist bereits praxistauglich und teilweise auch in Smartphones zu finden. Googles Ansatz kombiniert das Verfahren jedoch mit Videodaten, analysiert die Mundbewegungen eines Sprechers und bringt sie mit den dazu passenden Teilen des Audiotracks in Verbindung.
Für das Anlernen ihres Modells sichteten die Autoren zunächst etwa 100 000 Videos mit Vorträgen und Gesprächen, aus denen sie 2000 Stunden mit klar vernehmbarer Sprache ohne Störgeräusche auswählten. Diese Ausschnitte wiederum reicherten sie mit Gesichtern und zugehöriger Sprache aus anderen Quellen an und kreierten so eine "künstliche Cocktailparty". Damit trainierten sie ihre KI auf Basis eines Convolutional Neural Networks, so dass das System die Audio-Streams anhand ihrer Sprecher separieren konnte. Das zugehörige Framework AVSpeech soll später veröffentlicht werden.
Mehrere Sprecher trennen, Hintergrundgeräusche ausschalten
Anwendungsbereiche für diese Technik sehen die Entwickler mehrere: Verbesserung und Erkennung von Sprache in einem Video, Unterstützung für Gehörgeschädigte oder verbesserte Video-Konferenzen. Ihre Arbeit führen die Entwickler in mehreren Videos vor: unter anderem anhand zweier Comedians, die auf einer Bühne lautstark "aneinander vorbei" reden; am Beispiel eines Videochats, bei dem eine zweite Person im Bildhintergrund telefoniert; und an einer Person in einer Kantine mit zahlreichen Hintergrundgeräuschen.
(tiw)
