

Maschine knackt den Zauberwürfel
Mittels Deep Learning hat sich ein Algorithmus selbst beigebracht, wie man den Rubik's Cube bezwingt.
- TR Online
Eine weitere Bastion menschlicher Fähigkeiten und Intelligenz wurde von Maschinen eingenommen: Algorithmen aus dem Bereich des maschinellen Lernens haben sich selbständig beigebracht, den Zauberwürfel (Rubik's Cube) zu lösen – und zwar ohne menschliche Mithilfe.
So merkwürdig das klingt, handelt es sich durchaus um einen Meilenstein. Das Verfahren ist ein neuer Ansatz, wichtige Probleme in den Computerwissenschaften zu lösen – dann nämlich, wenn es nur minimale Unterstützung gibt.
Der Zauberwürfel ist ein dreidimensionales Puzzle-Spielzeug, das bereits 1974 vom ungarischen Erfinder Erno Rubik entwickelt wurde. Ziel ist es, dass alle Seiten des Würfels die jeweils gleiche Farbe zeigen. Er entwickelte sich zum Bestseller mit über 350 Millionen verkauften Einheiten.
In 26 Schritten zur Lösung
Das Spielzeug interessiert seit Jahren auch Computerwissenschaftler und Mathematiker. Eine der Fragestellungen war, was die kleinste Anzahl der Schritte ist, die notwendig sind, um den Würfel aus einer zufälligen Position zu lösen. Die Antwort, bewiesen im Jahr 2014, ist 26.
Eine weitere bekannte Herausforderung ist die Entwicklung eines Algorithmus, der den Zauberwürfel aus jeder Position lösen kann. Rubik selbst gelang dies einen Monat nach der Erfindung. Versuche, den Prozess zu automatisieren, basieren seit dieser Zeit auf Algorithmen, die der Mensch geschaffen hat.
In jüngster Zeit wird jedoch nach Wegen gesucht, dass Maschinen das Problem selbst lösen. Eine Idee dabei ist, einen Ansatz zu verwenden, der bereits erfolgreich bei Schach oder Go verwendet wurde.
Die Regeln des Spiels
In diesen Szenarien wurden einer Deep-Learning-Maschine die Regeln des Spiels erklärt und diese dann beauftragt, gegen sich selbst anzutreten. Wichtig dabei: Das System wird "belohnt" – für jeden Schritt und je nach Performance. Dieser Belohnungsprozess ist enorm wichtig, weil er der Maschine hilft, schlechtes von gutem Spiel zu trennen. Es hilft der Maschine beim Lernen.
Für viele Echtweltsituationen ist dies allerdings wenig hilfreich, weil die Belohnungen sich nur schlecht bestimmen lassen. Beispielsweise kann eine zufällige Drehung des Zauberwürfels gut oder schlecht sein, es lässt sich nur schwer feststellen, ob die neue Konfiguration des Rubik's Cube den Spieler schneller zur Lösung bringt. Zudem kann eine Sequenz aus zufälligen Drehungen lange Zeit ohne Lösung bleiben, entsprechend gibt es die ultimative Belohnung nur selten.
Bei Schach gibt es hingegen einen relativ großen Suchraum, doch jeder Schritt lässt sich evaluieren und belohnen. Beim Zauberwürfel ist das nicht so.
Computer als Autodidakt
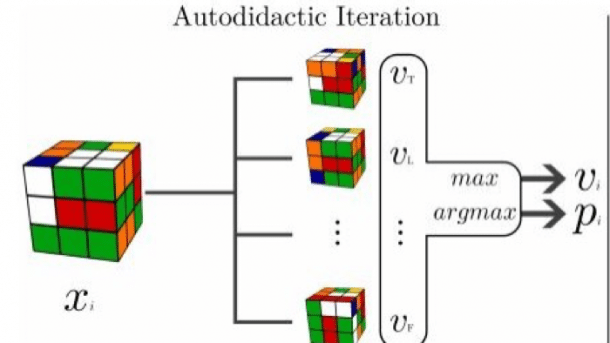
Stephen McAleer und seine Kollegen von der University of California in Irvine haben hier nun einen neuen Ansatz gefunden. Ihre neue Deep-Learning-Technik nennt sich "autodidaktische Iteration". Sie kann sich selbst beibringen, den Zauberwürfel zu lösen, ohne dass der Mensch helfen muss. Der Trick dabei ist, dass das Team eine Methode gefunden hat, wie sich die Maschine ihr eigenes Belohnungssystem schaffen kann.
Aus der Position eines ungelösten Würfels muss die Maschine dazu entscheiden, ob ein spezifischer Schritt eine Verbesserung der bestehenden Konfiguration ist. Dazu muss sich der Schritt evaluieren lassen.
Die autodidaktische Iteration tut dies, indem sie von einem gelösten Würfel ausgeht und dann schrittweise zurückgeht, um zu schauen, ob es eine Konfiguration gibt, die ähnlich ist wie der vorgeschlagene Schritt. Der Prozess ist nicht perfekt, doch Deep Learning hilft dem System dabei, herauszufinden, welche Schritte grundsätzlich besser sind als andere.
Komplexe Probleme
Nach dem Training nutzt das Netzwerk dann einen Standardsuchbaum um die besten Schritte für jede Konfiguration des Würfels zu finden. Im Ergebnis kommt es zu einem Algorithmus, der erstaunlich gut funktioniert. "Er kann jeden zufällig eingestellten Würfel zu 100 Prozent lösen und erreicht dabei eine mittlere Schrittzahl von 30", so die Forscher. Das ist genauso viel oder weniger als bei menschlichen Experten.
Das Verfahren könnte sich auch für andere Aufgaben eignen, bei denen Deep Learning derzeit noch Probleme hat. Dazu gehören Puzzle wie Sokoban, Probleme wie Montezumas Rache oder Faktorisierungsverfahren. McAleer und sein Team haben hier bereits klare Ziele: "Wir arbeiten daran, die Methode zu erweitern, um sie für die Vorhersage von Proteinstrukturen zu verwenden."
Ob das klappt, ist noch unklar. Die geringe Anzahl von Schritten wie beim Zauberwürfel ist kein Vorteil. Dennoch ist ihr Algorithmus, den sie DeepCube getauft haben, hilfreich, um über die einfache Mustererkennung hinaus zu gehen. "Er kann sich selbst beibringen, komplexe Probleme zu lösen – und das mit nur einem Belohnungsstatus mittels reinem bestärkenden Lernen." Nun muss die Technik zeigen, ob sie das auch bei schwierigeren Dingen als dem Zauberwürfel kann.
()
