

Mehr besondere Freunde mit std::map und std::unordered_map
Modernes C++ besitzt acht assoziative Container, aber die zwei Container std::map und std::unordered_map sind besonders. Warum? Genau diese Frage beantwortet dieser Artikel.
- Rainer Grimm
Modernes C++ besitzt acht assoziative Container, aber die zwei Container std::map und std::unordered_map sind besonders. Warum? Genau diese Frage beantwortet dieser Artikel.
In meinem letzten Artikel "C++ Core Guidelines: std::array und std::vector sind die erste Wahl" behaupte ich, dass in 99 Prozent aller Anwendungsfälle std::array oder std::vector die beste Wahl ist. Eine ähnliche Aussage lässt sich auch für assoziative Container aufstellen: In 95 Prozent aller Anwendungsfälle sind std::map oder std::unordered_map die best Wahl. Gelegentlich ist der Wert nicht notwendig, der dem Schlüssel assoziiert ist. Dies sind die verbleibenden 5 Prozent. Bevor ich nun den Artikel beginne und einen Überblick und Zahlen zu den beiden assoziativen Containern präsentiere, ist hier meine Daumenregel: Wenn du einen Container mit einer Schlüssel/Wert-Assoziation benötigst und die Schlüssel sortiert sein sollen, verwende eine std::map; falls nicht, verwende eine std::unordered_map.
Mehr Details zu den assoziativen Container gibt es in meinen früheren Artikeln zu assoziativen Containern.
Die acht Variationen
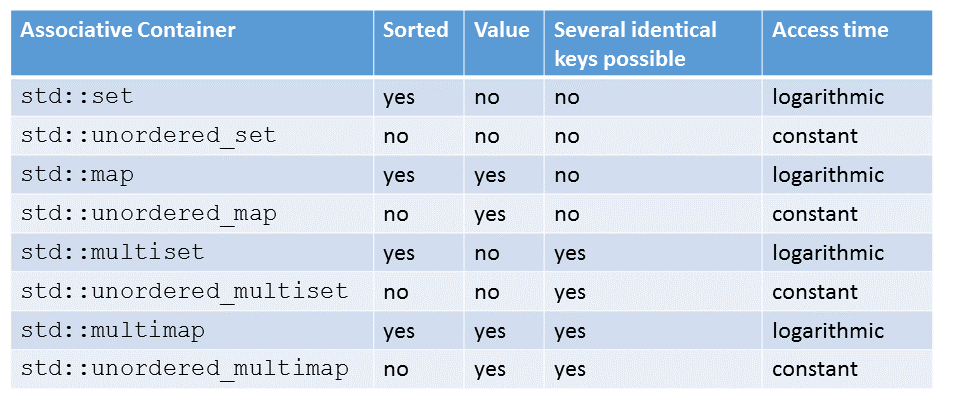
Um Ordnung in dieser Tabelle aus acht assoziativen Containern zu schaffen, musst du drei Fragen beantworten. Jede Frage kann mit ja oder nein beantwortetet werden. 2 ^ 3 == 8. Hier sind die drei Fragen.
- Ist der Container geordnet?
- Besitzt der Schüssel einen assoziierten Wert?
- Sind mehrere identische Schlüssel möglich?
Hier sind die Antworten:
- Wenn der Container nicht geordnet ist, wird er unordered genannt.
- Wenn der Schlüssel einen Wert assoziiert hat, wird er map genannt; sonst set.
- Wenn der Container mehr als einen identischen Schlüssel besitzt, wird er multi genannt.
Wenn ich von einem geordneten Container spreche, meine ich die Ordnung auf den Schlüsseln.
Falls diese Begrifflichkeit zu kompliziert war, dann gebe ich dir ein anschaulicheres Bild.
Ein Telefonbuch
Die acht Variationen assoziativer Container stehen für verschiedene Versionen eines Telefonbuchs. Was ist ein Telefonbuch? Ein Telefonbuch ist eine Sequenz von Schlüssel/Wert-Paaren. Du verwendest den Schlüssel (Familienname), um auf den Wert (Telefonnummer) zuzugreifen.
Die Familiennamen können nun in einem Telefonbuch geordnet oder nicht geordnet sein. Das Telefonbuch kann jedem Familiennamen eine Telefonnummer zugeordnet haben oder auch nicht. Darüber hinaus kann ein Telefonbuch mehrere identische Familiennamen erlauben oder nicht. Dies ist sehr praktisch, denn dank mehrerer identischer Familiennamen ist es möglich, sowohl die Handy- als auch die Festnetznummer im Telefonbuch zu hinterlegen.
Der Grund für diesen Artikel ist es nicht, die Unterschiede assoziativer Container zu erklären. Der Grund ist ein anderer: Die Zugriffszeit auf einen geordneten assoziativen Container ist logarithmisch, aber die Zugriffszeit auf einen ungeordneten assoziativen Container ist amortisiert konstant.
Performanz einer std::map und einer std::unordered_map
Was heißt amortisiert konstante Zugriffszeit für einen ungeordneten assoziativen Container wie std::unordered_map? Deine Abfrage einer Telefonnummer ist unabhängig von der Größe des Telefonbuchs. Du glaubst mir nicht? Hier ist ein kleiner Performanztest.
Ich besitze ein Telefonbuch mit circa 89.000 Einträgen. In Laufe des Tests werde ich das Telefonbuch in 10er-Schritten bis auf 89.000.000 Einträge erweitern. Nach jedem Schritt frage ich nach allen Telefonnummern. Das heißt, dass ich die Familiennamen in einer beliebigen Reihenfolge verwende.
Der folgende Auszug zeigt einen Teil der ersten Version des Telefonbuchs. Die Name/Nummer-Paare sind durch Doppelpunkte und der Name ist von der Nummer durch ein Komma getrennt.

Das Programm sollte nicht so schwer zu lesen sein:
// telephoneBook.cpp
#include <chrono>
#include <fstream>
#include <iostream>
#include <map>
#include <random>
#include <regex>
#include <sstream>
#include <string>
#include <unordered_map>
#include <vector>
using map = std::unordered_map<std::string, int>; // (1)
std::ifstream openFile(const std::string& myFile){
std::ifstream file(myFile, std::ios::in);
if ( !file ){
std::cerr << "Can't open file "+ myFile + "!" << std::endl;
exit(EXIT_FAILURE);
}
return file;
}
std::string readFile(std::ifstream file){
std::stringstream buffer;
buffer << file.rdbuf();
return buffer.str();
}
map createTeleBook(const std::string& fileCont){
map teleBook;
std::regex regColon(":");
std::sregex_token_iterator fileContIt(fileCont.begin(), fileCont.end(), regColon, -1);
const std::sregex_token_iterator fileContEndIt;
std::string entry;
std::string key;
int value;
while (fileContIt != fileContEndIt){
entry = *fileContIt++;
auto comma = entry.find(",");
key = entry.substr(0, comma);
value = std::stoi(entry.substr(comma + 1, entry.length() -1));
teleBook[key] = value;
}
return teleBook;
}
std::vector<std::string> getRandomNames(const map& teleBook){
std::vector<std::string> allNames;
for (const auto& pair: teleBook) allNames.push_back(pair.first);
std::random_device randDev;
std::mt19937 generator(randDev());
std::shuffle(allNames.begin(), allNames.end(), generator);
return allNames;
}
void measurePerformance(const std::vector<std::string>& names, map& m){
auto start = std::chrono::steady_clock::now();
for (const auto& name: names) m[name];
std::chrono::duration<double> dur= std::chrono::steady_clock::now() - start;
std::cout << "Access time: " << dur.count() << " seconds" << std::endl;
}
int main(int argc, char* argv[]){
std::cout << std::endl;
// get the filename
std::string myFile;
if ( argc == 2 ){
myFile= {argv[1]};
}
else{
std::cerr << "Filename missing !" << std::endl;
exit(EXIT_FAILURE);
}
std::ifstream file = openFile(myFile);
std::string fileContent = readFile(std::move(file));
map teleBook = createTeleBook(fileContent);
std::cout << "teleBook.size(): " << teleBook.size() << std::endl;
std::vector<std::string> randomNames = getRandomNames(teleBook);
measurePerformance(randomNames, teleBook);
std::cout << std::endl;
}
Meine Erläuterung beginnt mit dem main-Programm. Zuerst öffne ich die Datei, lese den Inhalt ein, erzeuge das Telefonbuch (std::map oder std::unordered_map), erhalte eine zufällige Permutation der Familiennamen und mache letztlich den Performanztest. Okay, das war zu kurz.
Die Zeile 1 ist die interessanteste Zeile. Eine std::unordered_map unterstützt eine Obermenge des Interfaces einer std::map. Dadurch wird mein Performanztest sehr gemütlich. Zuerst verwendete ich eine Map (using map = std::map<std::string, int>;) und dann änderte ich die Zeile zu using map = std::unordered_map<std::string, int>;. Die entsprechenden Beziehungen gelten natürlich für die Paare (std::set/std::unordered_set), (std::mutliset, std::unordered_multiset) und (std::multimap, std::unordered_multimap). Ich denke, die folgenden Funktion sind ziemlich interessant.
- createTeleBook
- die while-Schleife iteriert über alle Name/Number-Tokens, erzeugt durch den regulären Ausdruck regColon (Zeile 2)
- jedes Token wird durch ein Komma separiert (Zeile 3)
- am Ende wird das Name/Number-Paar zu dem Telefonbuch hinzugefügt (Zeile 4)
- getRandomNames
- schiebt alle Namen auf den Vektor (Zeile 5)
- erzeugt eine Permutation der Namen (Zeile 6)
- measurePerformance
- fragt nach dem Namen im Telefonbuch (Zeile 7)
Jetzt kommen endlich die Performanzzahlen für die std::map und die std::unordered_map.
std::map

std::unordered_map
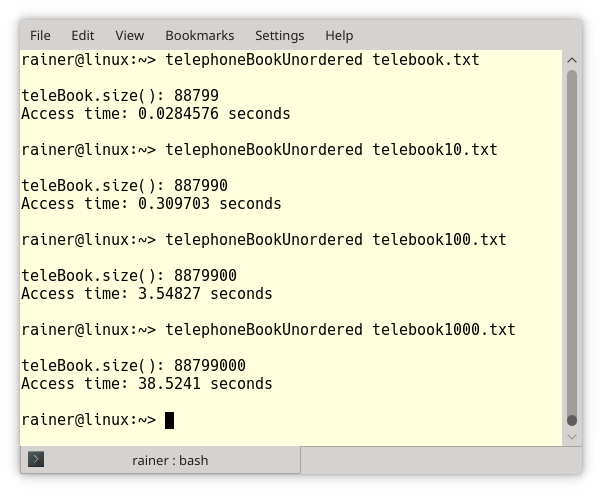
Die Screenshots stellen exakt dar, wie groß die Telefonbücher sind. Die Zahlen bestätigen die Zahlen, die ich in der ersten Tabelle bereits präsentierte: Die Zugriffszeit auf ein std::map hängt logarithmisch von der Anzahl seiner Elemente ab und die Zugriffszeit auf eine std::unordered_map ist amortisiert konstant. Der folgende Plot stellt die Performanzzahlen der std::map der der std::unordered_map gegenüber.

Für 100.000 Einträge ist die std::map dreimal langsamer als die std::unordered_map und für 100.000.000 Einträge ist sie 7,5-mal langsamer.
Wie geht's weiter?
Nach diesem kleinen Ausflug von den C++ Core Guidlines geht es in meinem nächsten Artikel um Verletzungen der Containergrenzen und wie sich diese vermeiden lassen.
C++-Schulungen im Großraum Stuttgart
Ich freue mich darauf, weitere C++-Schulungen halten zu dürfen.
- C++11 und C++14: 25. bis 27 Juni 2019
- Generische Programmierung (Templates) mit C++: 13. bis 15. August 2019
- Embedded-Programmierung mit modernem C++: 5. bis 7. November 2019
Die Details zu meinen C++- und Python-Schulungen gibt es auf www.ModernesCpp.de. ()
