

C++ Core Guidelines: Wenn RAII versagt
Bevor das sehr beliebte RAII-Idiom in C++ zur Sprache kommt, geht es nun um einen Trick, der oft praktisch zur Hand ist, wenn mehrmals nach einem Text gesucht wird: Verwende negative Suche.
- Rainer Grimm
Bevor ich über das sehr beliebte RAII-Idiom in C++ schreibe, möchte ich einen Trick vorstellen, der oft praktisch zur Hand ist, wenn mehrmals nach einem Text gesucht wird: Verwende negative Suche.
Häufig folgen die Textpatterns (Tokens), nach denen du suchst, einem sich immer wiederholenden Muster. Genau hier kommt die negative Suche ins Spiel
Verwende negative Suche, falls es möglich ist
Die zentrale Idee der negativen Suche lässt sich einfach erklären. Du definierst einen komplizierten regulären Ausdruck, um deine Tokens zu finden. Häufig sind die Tokens durch Trenner wie Kommas, Doppelpunkte oder auch Leerzeichen separiert. In diesem Fall ist es oft einfacher, die Trenner zu suchen, da die Tokens genau der Text zwischen den Trennern sind. Das folgende Beispiel bringt meine Idee auf den Punkt.
// regexTokenIterator.cpp
#include <iostream>
#include <string>
#include <regex>
#include <vector>
std::vector<std::string> splitAt(const std::string &text, // (6)
const std::regex ®) {
std::sregex_token_iterator hitIt(text.begin(), text.end(), reg, -1);
const std::sregex_token_iterator hitEnd;
std::vector<std::string> resVec;
for (; hitIt != hitEnd; ++hitIt)
resVec.push_back(hitIt->str());
return resVec;
}
int main() {
std::cout << std::endl;
const std::string text("3,-1000,4.5,-10.5,5e10,2e-5"); // (1)
const std::regex regNumber(
R"([-+]?([0-9]+\.?[0-9]*|\.[0-9]+)([eE][-+]?[0-9]+)?)"); // (2)
std::sregex_iterator numberIt(text.begin(), text.end(), regNumber); // (3)
const std::sregex_iterator numberEnd;
for (; numberIt != numberEnd; ++numberIt) {
std::cout << numberIt->str() << std::endl; // (4)
}
std::cout << std::endl;
const std::regex regComma(",");
std::sregex_token_iterator commaIt(text.begin(), text.end(), regComma, -1); // (5)
const std::sregex_token_iterator commaEnd;
for (; commaIt != commaEnd; ++commaIt) {
std::cout << commaIt->str() << std::endl;
}
std::cout << std::endl;
std::vector<std::string> resVec = splitAt(text, regComma); // (7)
for (auto s : resVec)
std::cout << s << " ";
std::cout << "\n\n";
resVec = splitAt("abc5.4def-10.5hij2e-5klm", regNumber); // (8)
for (auto s : resVec)
std::cout << s << " ";
std::cout << "\n\n";
std::regex regSpace(R"(\s+)");
resVec = splitAt("abc 123 456\t789 def hij\nklm", regSpace); // (9)
for (auto s : resVec)
std::cout << s << " ";
std::cout << "\n\n";
}
Die Zeile 1 enthält einen String, der aus Zahlen besteht, die durch Kommas separiert sind. Um alle Zahlen auszulesen, definiere ich in Zeile 2 einen regulären Ausdruck für eine Zahl. Eine Zahl kann in diesem Fall eine Ganzzahl, eine Fließkommazahl oder auch eine Zahl in wissenschaftlicher Notation sein. In Zeile 3 definiere ich einen Iterator vom Typ std::regex_iterator, der über alle Tokens iteriert und sie in Zeile 4 darstellt. Der Iterator std::regex_token_iterator in Zeile 5 ist noch mächtiger. Er sucht nach Kommas und gibt mir den Text zwischen den Kommas zurück, da ich den negativen Index -1 angewandt habe.
Dieses Pattern ist so praktisch, dass ich es in die Funktion splitAt (Zeile 6) gegossen habe. splitAt nimmt einen Text und einen regulären Ausdruck an und schiebt den Text zwischen dem angewandten regulären Ausdruck auf den std::vector<std::string> res. Jetzt ist es ein Kinderspiel, einen Text mehrmals an Kommas (Zeile 7), an Zahlen (Zeile 8) oder an Leerraum (Whitespaces) (Zeile 9) zu trennen.
Wie Christoph Stockmayer anmerkte, lässt sich die Funktion splitAt noch deutlich kompakter schreiben, da ein std::vector direkt mit einem Begin- und Enditerator umgehen kann.
std::vector<std::string> splitAt(const std::string &text,
const std::regex ®) {
return std::vector<std::string>(std::sregex_token_iterator(text.begin(), text.end(), reg, -1),
std::sregex_token_iterator());
}
Hier ist die Ausgabe des Programms.

Dies war meine letzte Regel zu regulären Ausdrücken. Damit beende ich auch die Regeln zu der Standard-Bibliothek in den C++ Core Guidelines. Stopp! Es gibt noch eine Regel zu der C-Standard-Bibliothek.
SL.C.1: Don’t use setjmp/longjmp
Die Begründung für die Regel in den Guidelines ist kurz und bündig: ein longjmp ignoriert einen Destruktor. Damit werden alle Resource-Management-Strategien, die auf RAII basieren, gebrochen. Ich hoffe, du kennst RAII. Wenn nicht, hier ist die Essenz.
RAII steht für Rescource Acquisition Is Initialization. Dieses wohl wichtigste C++-Idiom besagt, dass eine Ressource im Konstruktor eines Objekts angefordert und im Destruktor des Objekts wieder freigegeben wird. Das Entscheidende dabei ist, dass der Destruktor genau dann automatisch aufgerufen wird, wenn das Objekt seine Gültigkeit verliert.
Das folgende Beispiel bringt das deterministische Verhalten von RAII auf den Punkt:
// raii.cpp
#include <iostream>
#include <new>
#include <string>
class ResourceGuard{
private:
const std::string resource;
public:
ResourceGuard(const std::string& res):resource(res){
std::cout << "Acquire the " << resource << "." << std::endl;
}
~ResourceGuard(){
std::cout << "Release the "<< resource << "." << std::endl;
}
};
int main(){
std::cout << std::endl;
ResourceGuard resGuard1{"memoryBlock1"}; // (1)
std::cout << "\nBefore local scope" << std::endl;
{
ResourceGuard resGuard2{"memoryBlock2"}; // (3)
} // (4)
std::cout << "After local scope" << std::endl;
std::cout << std::endl;
std::cout << "\nBefore try-catch block" << std::endl;
try{
ResourceGuard resGuard3{"memoryBlock3"};
throw std::bad_alloc(); // (5)
}
catch (std::bad_alloc& e){ // (6)
std::cout << e.what();
}
std::cout << "\nAfter try-catch block" << std::endl;
std::cout << std::endl;
}
ResourceGuard ist ein Wächter, der auf seine Ressource aufpasst. In diesem Fall wird die Ressource durch einen String repräsentiert. ResourceGuard erzeugt den String in seinem Konstruktor und gibt diesen in seinem Destruktor wieder frei. ResourceGuard verrichtet seinen Job sehr zuverlässig.
Der Destruktor von resGuard1 (Zeile 1) wird am Ende der main-Funktion (Zeile 2) aufgerufen. Der Lebenszyklus von resGuard2 (Zeile 3) endet bereits in Zeile 4. Daher wird der Destruktor automatisch aufgerufen. Selbst das Werfen einer Ausnahme beeinflusst nicht die Zuverlässigkeit von resGuard3 (Zeile 5). Sein Destruktor wird am Ende des try-Blocks (Zeile 6) aufgerufen.
Der Screenshot zeigt schön die Lebenszyklen der einzelnen Objekte.
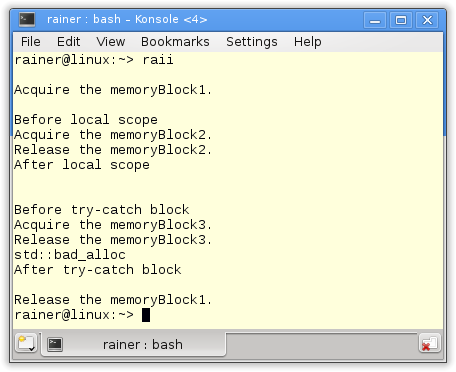
Gerne will ich die zentrale Idee von RAII hervorheben: Der Lebenszyklus einer Ressource wird an den Lebenszyklus einer lokalen Variable gebunden und C++ verwaltet automatisch den Lebenszyklus seiner lokalen Variablen.
Wie bricht nun aber setjmp/longjmp diesen Automatismus? Zuerst einmal möchte ich das Verhalten von setjmp und std::longjmp vorstellen:
int setjmp(std::jmp_buf env):
- speichert den Ausführungskontext in env für std::longjmp
- gibt bei dem ersten, direkten Aufruf 0 zurück
- gibt bei weiteren Aufrufen durch std::longjmp den Wert zurück, den std::longjmp setzt
- ist die Zieladresse eines std::longjmp-Aufrufs
- entspricht der catch-Clause bei der Ausnahmebehandlung
void std::longjmp(std::jmp_buf env, int status):
- stellt den Ausführungskontext, der in env gespeichert ist, wieder her
- setzt den Status des setjmp-Aufrufs
- entspricht dem throw-Aufruf bei der Ausnahmebehandlung
Das war sehr technisch. Hier ist ein einfaches Beispiel:
// setJumpLongJump.cpp
#include <cstdlib>
#include <iostream>
#include <csetjmp>
#include <string>
class ResourceGuard{
private:
const std::string resource;
public:
ResourceGuard(const std::string& res):resource(res){
std::cout << "Acquire the " << resource << "." << std::endl;
}
~ResourceGuard(){
std::cout << "Release the "<< resource << "." << std::endl;
}
};
int main(){
std::cout << std::endl;
std::jmp_buf env;
volatile int val;
val = setjmp(env); // (1)
if (val){
std::cout << "val: " << val << std::endl;
std::exit(EXIT_FAILURE);
}
{
ResourceGuard resGuard3{"memoryBlock3"}; // (2)
std::longjmp(env, EXIT_FAILURE); // (3)
} // (4)
}
Der Aufruf in Zeile 1 speichert den Ausführungskontext und gibt 0 zurück. In Zeile 3 wird der Ausführungskontext wieder aktiviert. Der entscheidende Punkt ist es, dass der Destruktor von resGuard3 (Zeile 2) nicht in Zeile 4 aufgerufen wird. Das kann im konkreten Fall bedeuten, dass du ein Speicherleck hast oder dein Mutex nicht freigegeben wird.

EXIT-FAILURE ist der Rückgabewert des zweiten setjmp-Aufrufs (Zeile 1) und auch der Rückgabewert des Executables.
Wie geht's weiter?
Fertig, aber nicht vollständig! Nun habe ich mehr als 100 Aritkel zu den C++ Core Guidelines geschrieben und dabei viel gelernt. Die C++ Core Guidelines besitzen aber noch eine supporting section. Das hört sich sehr interessant an. Mit dieser supporting section werde ich in meinem nächsten Artikel beginnen.
