

Natural Language Processing: LinkedIn veröffentlicht Framework für BERT und Co
DeText ist ein NLP-Framework zum Verarbeiten von Texten und dem Ranking von Dokumenten über Machine Learning mit Sprachmodellen wie BERT.

LinkedIn hat ein Framework für Natural Language Processing (NLP) veröffentlicht: DeText bietet kein eigenes Sprachmodell, sondern verwendet Verfahren wie das von Google entwickelte BERT. Dabei konzentriert es sich auf das Sprachverständnis über Textklassifikation und Sequenz Tagging sowie auf das Ranking von Textdokumenten.
DeText ist ein Open-Source-Framework, das dem Einsatz von BERT- (Bidirectional Encoder Representations from Transformers) und anderen Modellen die Komplexität nehmen und mehr Flexibilität für das Verarbeiten von Sprache ermöglichen soll. LinkedIn vergleicht das Werkzeug mit einem Bohrer, der einen kräftigen Motor mitbringt, aber für unterschiedliche Aufgaben spezielle Aufsätze benötigt.
Videos by heise
Austausch der Modelle
Analog dazu können Data Scientists die Modelle in DeText passend zur jeweiligen Aufgabe auswählen. LinkedIn setzt ein mit den hauseigenen Daten trainiertes BERT-Modell, das den Namen LiBERT trägt, für typische Aufgabenstellungen im Unternehmen ein. Anwendungen nutzen es unter anderem für den Versuch, die Bedeutung von Textabfragen zu verstehen und herauszufinden, was Nutzerinnen und Nutzer mit einer Abfrage bezwecken. Als Beispiel nennt der Blogbeitrag die englische Anfrage "sales consultant at Insights", die das System als die Suche nach einem Job als Verkaufsberater im Unternehmen Insights verstehen soll.

(Bild: LinkedIn)
Als Vorteil von DeText hebt der Blogbeitrag hervor, dass sich mit den vortrainierten Modellen deutlich einfacher von vorhandenen Anwendungsfällen auf weitere Aufgaben schließen lässt. Unter anderem soll es das semantische Verständnis von Texten auf andere Bereiche wie das Auffinden weiterer relevanter Wortsequenzen zu einer Query oder dem Erstellen einer Rangfolge für Dokumente übertragen.
Die passende Reihenfolge
Das Ranking ist eine wichtige Aufgabe von DeText. Das Erstellen einer Rangfolge mit BERT ist laut LinkedIn nicht gerade trivial, da es kein Standardverfahren für den effizienten Einsatz damit gibt. Mit DeText sei das Unternehmen aber in der Lage, vortrainierte BERT-Modelle im produktiven Einsatz für das Ranking zu verwenden.
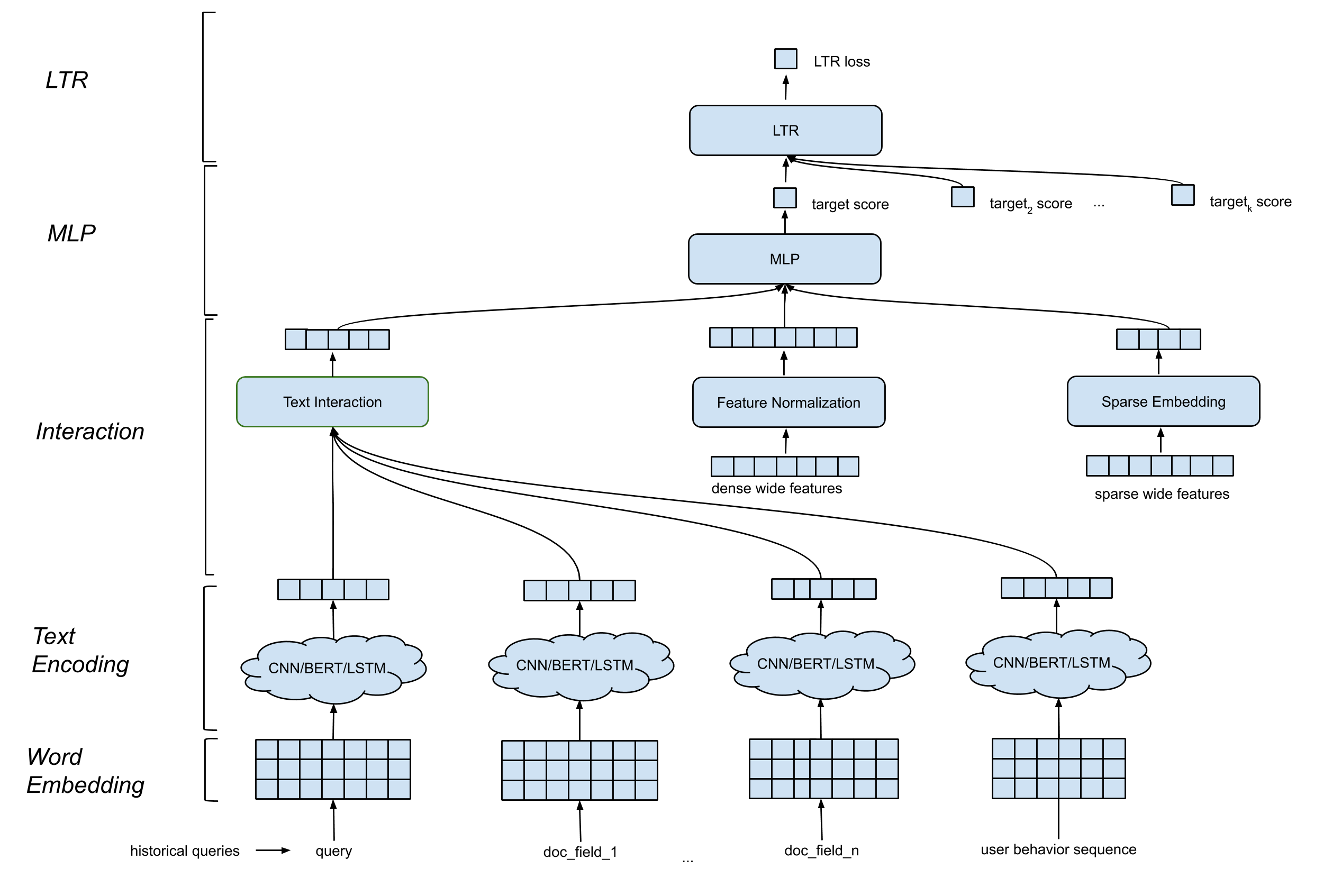
(Bild: LinkedIn)
Das Framework kombiniert dabei verschiedene Quellen wie die Suchabfragen und die Nutzerprofile mit den Informationen zu den Zielen wie Textdokumenten. Im ersten Schritt berechnet das DeText-Ranking-Modell den semantischen Bezug zwischen den Quellen und Zielen und verbindet die semantischen Features anschließend mit handgestrickten traditionellen Features, um einen endgültigen Score für die Quell-Ziel-Relevanz zu berechnen.

(Bild: LinkedIn)
Das Erstellen der Rangfolge erfolgt auf mehreren Ebenen, die sich unter anderem auf Word Embeddings und Text Embeddings konzentrieren. Ein Interaction Layer kombiniert die unteren Schichten, und ein MLP Layer (Multilayer Perceptron) berechnet den Score unter Berücksichtigung der nichtlinearen Kombination der Features. Ganz oben sitzt schließlich ein Learning-to-Rank Layer (LTR), der die unterschiedlichen Target-Scores verarbeitet.
Weitere Details zu DeText finden sich in einem Blogbeitrag bei LinkedIn. Das Framework ist auf GitHub als Open-Source-Projekt verfügbar.
(rme)
