

Atomare Referenzen mit C++20
Atomare Variablen erhalten wichtige Erweiterungen in C++20. Im heutigen Artikel stelle ich den neuen Datentyp std::atomic_ref genauer vor.
- Rainer Grimm
Atomare Variablen erhalten wichtige Erweiterungen in C++20. Im heutigen Artikel stelle ich den neuen Datentyp std::atomic_ref genauer vor.

Der Datentyp std::atomic_ref wendet atomare Operationen auf sein referenziertes Objekt an.
std::atomic_ref
Gleichzeitiges Schreiben und Lesen einer std::atomic_ref ist kein Data Race. Die Lebenszeit des referenzierten Objekts muss über die Lebenszeit der std::atomic_ref hinausgehen. Der Zugriff auf das Unterobjekt des referenzierten Objekts ist nicht wohldefiniert.
Motivation
Ist es nicht ausreichend, eine Referenz in einer atomaren Variable zu verwenden? Leider nicht.
Im folgenden Programm verwende ich die Klasse ExpensiveToCopy, die einen Zähler counter enthält. Dieser counter wird gleichzeitig von mehreren Threads inkrementiert. Konsequenterweise muss der Zähler daher geschützt werden:
// atomicReference.cpp
#include <atomic>
#include <iostream>
#include <random>
#include <thread>
#include <vector>
struct ExpensiveToCopy {
int counter{};
};
int getRandom(int begin, int end) { // (6)
std::random_device seed; // initial seed
std::mt19937 engine(seed()); // generator
std::uniform_int_distribution<> uniformDist(begin, end);
return uniformDist(engine);
}
void count(ExpensiveToCopy& exp) { // (2)
std::vector<std::thread> v;
std::atomic<int> counter{exp.counter}; // (3)
for (int n = 0; n < 10; ++n) { // (4)
v.emplace_back([&counter] {
auto randomNumber = getRandom(100, 200); // (5)
for (int i = 0; i < randomNumber; ++i) { ++counter; }
});
}
for (auto& t : v) t.join();
}
int main() {
std::cout << std::endl;
ExpensiveToCopy exp; // (1)
count(exp);
std::cout << "exp.counter: " << exp.counter << '\n';
std::cout << std::endl;
}
exp (1) ist ein teuer zu kopierendes Objekt. Aus Performancegründen nimmt die Funktion count (2) daher exp per Referenz an. count initialisiert den std::atomic<int> mit exp.counter (3). Die anschließenden Zeilen erzeugen zehn Threads (4). Jeder der Threads führt den Lambda-Ausdruck aus, der counter per Referenz annimmt. Der Lambda-Ausdruck erhält eine Zufallszahl zwischen 100 und 200 (5) und inkrementiert counter genau diese Anzahl. Die Funktion getRandom (6) ermittelt eine initiale Zufälligkeit und erzeugt den Zufallszahlengenerator Mersenne-Twister, der gleich verteilte Zufallszahlen erzeugt.
Letztlich sollte der exp.counter (7) ungefähr einen Wert von 1500 haben, den jeder der zehn Threads inkrementiert den Zähler 150 Mal. Die Ausführung des Programms auf dem Wandbox Online-Compiler überrascht mich.

Der Zähler ist 0. Was ist passiert? Das Problem verbirgt sich in der Zeile (3). Die Initialisierung des Ausdrucks std::atomic<int> counter{exp.counter} erzeugt eine Copy. Das folgende kleine Programm bringt das Problem auf den Punkt:
// atomicRefCopy.cpp
#include <atomic>
#include <iostream>
int main() {
std::cout << std::endl;
int val{5};
int& ref = val; // (2)
std::atomic<int> atomicRef(ref);
++atomicRef; // (1)
std::cout << "ref: " << ref << std::endl;
std::cout << "atomicRef.load(): " << atomicRef.load() << std::endl;
std::cout << std::endl;
}
Die Inkrementoperation (1) besitzt keine Auswirkung auf den referenzierten Wert ref (2). Der Wert von ref verändert sich nicht.

Wird std::atomic<int> counter{exp.counter} durch std::atomic_ref<int> counter{exp.counter} ersetzt, behebt das das Problem:
// atomicReference.cpp
#include <atomic>
#include <iostream>
#include <random>
#include <thread>
#include <vector>
struct ExpensiveToCopy {
int counter{};
};
int getRandom(int begin, int end) {
std::random_device seed; // initial randomness
std::mt19937 engine(seed()); // generator
std::uniform_int_distribution<> uniformDist(begin, end);
return uniformDist(engine);
}
void count(ExpensiveToCopy& exp) {
std::vector<std::thread> v;
std::atomic_ref<int> counter{exp.counter};
for (int n = 0; n < 10; ++n) {
v.emplace_back([&counter] {
auto randomNumber = getRandom(100, 200);
for (int i = 0; i < randomNumber; ++i) { ++counter; }
});
}
for (auto& t : v) t.join();
}
int main() {
std::cout << std::endl;
ExpensiveToCopy exp;
count(exp);
std::cout << "exp.counter: " << exp.counter << '\n';
std::cout << std::endl;
}
Nun besitzt counter den erwarteten Wert.

To be Atomic or not to be Atomic
Du magst dich fragen, warum ich den Zähler als atomare Variable erklärt habe:
struct ExpensiveToCopy {
std::atomic<int> counter{};
};
Das ist eine mögliche Strategie. Sie hat aber einen großen Nachteil. Jeder Zugriff auf den atomaren Zähler muss synchronisiert werden. Synchronisation gibt es aber nicht zum Nulltarif. Im Gegensatz dazu lässt sich dank std::atomic_ref<int> explizit steuern, wann der Zugriff auf den Zähler atomar sein muss. Eventuell wird der Zähler während der Programmausführung meist nur gelesen. Ihn in diesem Fall atomar zu erklären, ist das Gegenteil von Optimierung.
Nun möchte ich noch ein paar Details zum Klassen-Template std::atomic_ref hinzufügen.
Spezialisierungen für std::atomic_ref
std::atomic_ref lässt sich für benutzerdefinierte Datentypen definieren. Teilweise Spezialisierung für Zeiger und vollständige Spezialisierungen sind für arithmetische Datentypen wie Ganzzahlen oder Gleitkommazahlen möglich
Primäre Template
Das primäre Template std::atomic_ref lässt sich für einen trivial kopierbaren Datentyp T instanziieren. Trivial kopierbare Daten sind entweder skalare Datentypen (arithmetische Datentypen, enums, Zeiger, Zeiger auf Klassenmitglieder oder std::nullptr_t) oder trivial kopierbare Klassen oder Arrays von skalaren Datentypen.
Teilweise Spezialisierungen für Zeigerdatentypen
Der Standard bietet teilweise Spezialisierungen für Zeigertypen an: std::atomic_ref<t*>.
Spezialisierungen für arithmetische Datentypen
Der Standard bietet Spezialisierungen für Ganzzahl- und Gleitkommazahl-Datentypen an: std::atomic_ref<arithmetic type>.
- Zeichentypen:
char, char8_t (C++20),char16_t,char32_tundwchar_t - vorzeichenbehaftete Ganzzahlen:
signed char,short,int,longundlong long - vorzeichenlose Ganzzahlen:
unsigned char,unsigned short,unsigned int,unsigned long, undunsigned long long - zusätzliche Ganzzahlen, die in der Header-Datei
<cstdint>definiert sind - Standard-Gleitkommazahlen:
float,doubleundlong double
Alle atomare Operationen
Zuerst einmal zeigt die folgende Tabelle die Liste aller atomaren Operationen.
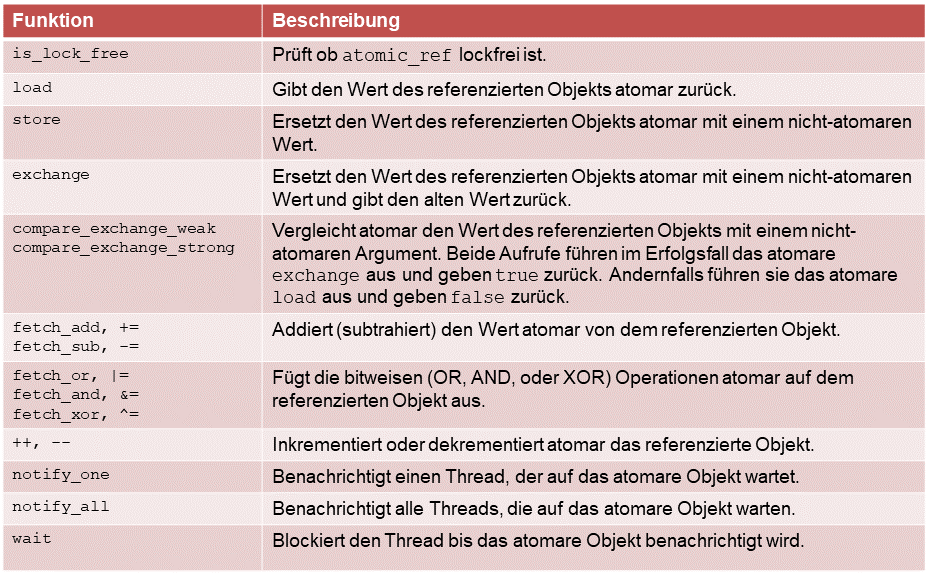
Die zusammengesetzten Zuweisungsoperatoren (+=, -=, |=, &= oder ^=) geben den neuen Wert zurück; die fetch-Varianten den alten. Jede Funktion unterstützt ein weiteres Argument zur Speicherordnung. Der Default ist die sequentielle Konsistenz.
Natürlich stehen nicht alle Funktionen für alle von std::atomic_ref referenzierten Objekte zur Verfügung. Die nächste Tabelle zeigt die Liste der atomaren Operationen, die von dem jeweiligen Datentyp unterstützt werden.

Beim sorgfältigen Studium der letzten zwei Tabellen fällt auf, dass sich Objekte vom Typ std::atomic_ref auch zur Synchronisation von Threads verwenden lassen.
Wie geht's weiter?
std::atomic und std::atomic_ref unterstützen in C++20 die neuen Funktionen notify_one, notify_all und wait. Dank dieser Funktion lassen sich Threads einfach synchronisieren. std::atomic und insbesondere Thread-Synchronisation mit atomaren Variablen werde ich mir in meinem nächsten Artikel genauer anschauen.
Neue Online-Seminare
- Embedded-Programmierung mit modernem C++ (Deutsch): 26. bis 28. Januar 2021 (9 bis 17 Uhr CEST; Durchführungsgarantie)
- C++20 – A Deep Insight (English): 1. bis 3. Februar 2021 (16 bis 20 Uhr UTC)
