

Event-Streaming: Confluent 6.1 zielt auf Ausfallsicherheit für Kafka-Anwendungen
Das erste Release nach der Zusammenführung mit der Confluent Cloud soll vor allem die Verfügbarkeit verteilter Kafka-Cluster verbessern.

(Bild: Gorodenkoff / Shutterstock.com)
Confluent hat seine auf dem Open-Source-Projekt Kafka basierende Confluent-Plattform in Version 6.1 veröffentlicht. Die auf den Unternehmenseinsatz ausgerichtete Plattform bringt im aktuellen Release unter anderem eine automatische Verwaltung der Replikas für die Ausfallsicherheit. Außerdem lassen sich Production Queries für ksqlDB im laufenden Betrieb anpassen.
Das Release ist das erste seit der Zusammenführung der Confluent-Plattform mit der Confluent Cloud, die unter dem Projektnamen Metamorphosis (Metamorphose) stattfand und seit Dezember abgeschlossen ist. Die Streaming-Plattform Kafka als Grundlage der kommerziellen Plattform steht unter dem Dach der Apache Software Foundation und ist im Dezember in Version 2.7 erschienen.
Videos by heise
Ausfallende Beobachter
Das Konzept der Multi-Region-Cluster (MRC) verteilt einen einzeilnen Cluster über mehrere Rechenzentren, um einen dauerhaften Betrieb auch beim Ausfall eines kompletten Datacenters sicherzustellen. In MRCs existieren neben den Replikatypen Leader und Follower sogenannte Observer. Sie lassen sich asynchron einbinden, da sie bei den synchronisierten In-Sync Replicas (ISR) außen vor bleiben: Kafka muss damit nicht wie bei den Leader- und Follower-Replikas auf eine Bestätigung warten, dass Daten angekommen sind.
Die Observer-Replikas liegen üblicherweise in entfernten Rechenzentren, und der asynchrone Einsatz verringert die Latenzzeiten. Beim Ausfall des Hauptrechenzentrums lassen sich die Observer-Replikas in die ISR integrieren, damit sie den laufenden Datenverkehr von Clients übernehmen. Bisher gab es jedoch für diesen Prozess keinen Automatismus, sondern die Beförderung musste manuell erfolgen.
Version 6.1 führt die Automatic Obvserver Promotion ein, die bei einem Ausfall eine Observer-Replika automatisch zu einer Follower-Replika befördert. Nach dem Wiederherstellen des Rechenzentrums degradiert die Plattform die Replika ebenso selbsttätig in den Observer-Status.
Abfragenänderung im laufenden Betrieb
Neu ist zudem die Möglichkeit, Abfragenlogik und Schemata für die Event-Streaming-Datenbank ksqlDB im laufenden Betrieb anzupassen. Über den Befehl CREATE OR RPLACE lässt sich das Schema eines Streams neu definieren. Daneben ermöglicht der Befehl ALTER beispielsweise das Hinzufügen einer neuen Spalte über ADD COLUMN zu einem bestehenden Schema. Der Confluent-Blog zeigt das Ergänzen eines Schemas um eine Integer-Spalte in den beiden Varianten:
-- Original stream
CREATE STREAM s (x INTEGER, y INTEGER) WITH (...);
-- Add a column
ALTER STREAM s ADD COLUMN z INTEGER;
-- Note that CREATE OR REPLACE may also be used to change a schema:
CREATE OR REPLACE STREAM s
(x INTEGER, y INTEGER, z INTEGER) WITH (...);Daneben bekommt ksqlDB im aktuellen Release Pull Queries über WHERE mit mehreren Keys. Dazu dient das Prädikat IN. Bisher erlaubte diese Form Abfragen, die auf den aktuellen Zustand einer Materialized View erfolgen, nur einen Schlüssel.

(Bild: Confluent)
Sichtbar ausbalanciert
Eine weitere Neuerung betrifft die in der Confluent Platform 6.0 eingeführten Self-Balancing-Clusters, die sich selbsttätig um das Load Balancing kümmern, um den Durchsatz zu optimieren. Version 6.1 führt eine Status-API ein, über die sich der Zustand von Aufgaben wie das Hinzufügen eines Brokers abfragen lässt. Als visuelle Komponente verschafft die ebenfalls neue Status UI einen Überblick über die Operationen.
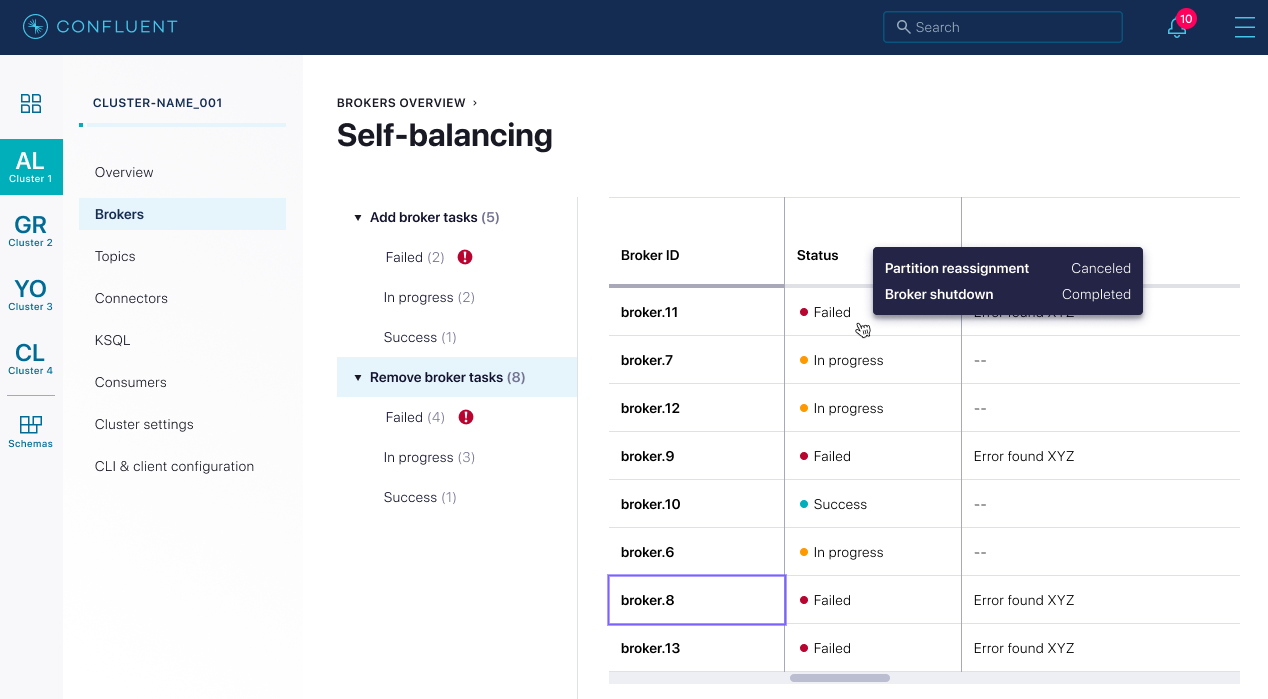
(Bild: Confluent)
Weitere Neuerungen in der Confluent-Plattform 6.1 lassen sich dem Confluent-Blog entnehmen.
(rme)
