

ARM-Prozessoren sollen bei Supercomputern und Cloud-Servern punkten
Nvidias ARM-Chip "Grace" soll ab 2023 Supercomputer antreiben; Ampere Altra und Amazon Graviton2 rechnen schon jetzt günstig. Bei der Software hakelt es noch.

Nvidia Grace (links) mit LPDDR5-SDRAM, rechts eine GPU mit HBM
(Bild: Nvidia)
- Andreas Stiller
Die britische Chipschmiede ARM, die derzeit von Nvidia übernommen wird, ist bei Supercomputern höchst prominent vertreten, vor allem im Top500-Spitzenreiter Fugaku mit dem Fujitsu-Prozessor A64FX. Aber auf der aktuellen, 58. Top500-Liste der schnellsten Supercomputer tauchten keine neuen Systeme mit ARM-Prozessortechnik auf. Das soll sich spätestens Anfang 2023 mit dem schweizerischen "Alps" sowie mit "Venado" am Los Alamos National Laboratoy (LANL) ändern. In beiden rechnet dann Nvidias kommender ARM-Prozessor "Grace", und zwar im Verbund mit LPDDR5-RAM, einer kommenden GPU als Rechenbeschleuniger, die High-Bandwith Memory (HBM) nutzt. Die AMD-Epyc-Partition des Alps (HPE Cray EX) mit 3 PFlops läuft bereits seit einem Jahr.
Auf der Supercomputing-Konferenz SC'21 wurden einige neue Details zu kommenden und aktuellen ARM-Rechnern fürs High Performance Computing (HPC) bekannt.
Videos by heise
Attraktive ARMv9-Features
Steven Poole, Chefarchitekt des Los Alamos National Laboratory (LANL), verriet Neuigkeiten zum gemeinsam mit Nvidia sowie der HPE-Sparte Cray für Anfang 2023 geplanten Supercomputerprojekt. Das trägt jetzt den Namen "Venado" und soll über 100 PFlops abliefern. Ob das noch für die Top Ten der 61. Top500-Liste im Juni 2023 reicht, wird spannend.
Nvidia Grace wird "ARM-Neoverse-Kerne der nächsten Generation" haben, also mit ARMv9-Architektur. Ob Nvidia auf Neoverse N2 oder V2 setzt, ist offen; sicherlich sind aber die Scalable Vector Extensions SVE2 an Bord. Als Cache-kohärente Verbindung zwischen CPU und GPU dient NVLink 4 (oder 5) mit 900 GByte/s.
(Bild: Los Alamos National Laboratory (LANL))
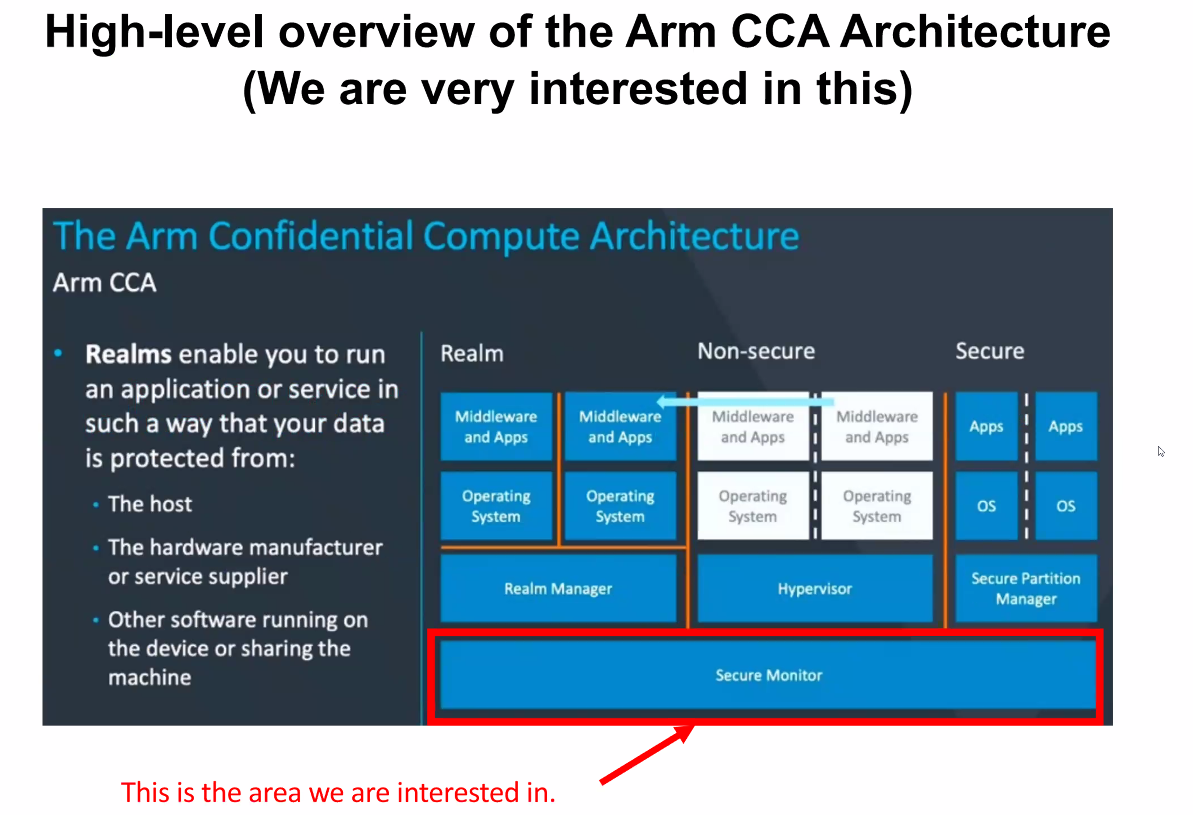
Für das LANL sind laut Poole zwei Aspekte von Grace besonders attraktiv: Die hohe Speicherperformance sowie die Confidential Compute Architecure (CCA). Erstere sei bei dünn besetzten Matrizen (sparse matrix) vorteilhaft, während der Top500-Benchmark Linpack mit dichten Matrizen rechnet. Noch wichtiger sei aber CCA, weil damit fremde Nutzer des Superrechners sicher abgeschottete Partitionen nutzen könnten.
"Penny-Cores" rechnen günstig
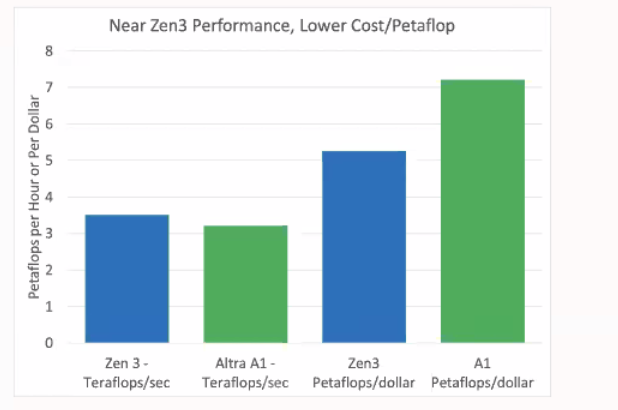
Die Cloud-Anbieter Amazon und Oracle von ihren HPC-Erfahrungen mit ARM-Maschinen. Oracle Cloud Infrastructure (OCI) bietet ARM-Instanzen zum Preis von 1 Cent pro Stunde und Kern an: "Penny-Cores". OCI betreibt seit Juni den 80-kernigen Altra A1 (Quicksilver) des Startups Ampere. Seine Neoverse-N1-Kernen (ARMv8.2) kennen kein SMT, haben aber je zwei SIMD-Einheiten mit Unterstützung für INT8 und BFloat16 fürs Maschinenlernen. Der Altra A1 kommt dank acht Speicherkanälen auf hohe Datentransferraten. Damit konnte er laut OCI etwa im klassischen HPC-Benchmark DGEMM dem AMD Epyc "Milan" (Zen 3) in der Performance nahezu das Wasser reichen, war aber mit 7 gegenüber 5,2 Petaflops pro US-Dollar (PFlops/$) um 34 Prozent preisgünstiger.
(Bild: Oracle)
Amazon setzt beim selbst designten Graviton2 ebenfalls auf ARM-Neoverse-N1-Kerne sowie acht RAM-Kanäle; hier stehen aber höchstens 64 Kerne bereit. Die darauf laufenden Instanzen (C6g.15xlarge) setzen sich bei den HPC-Benchmarks OpenFOAM und WRF mit 37 bis 40 Prozent besserem Preisleistungsverhältnis gegenüber Intel Skylake und Intel Cascade Lake in Szene. Auch hier hilft insbesondere die höhere Speicherbandbreite.
Stolperstellen
Bei Betriebssystemen, Compilern und Programmierbibliotheken für ARM-Serverprozessoren gibt es aber noch Verbesserungsbedarf. Die Rechenzentrumsbetreiber des schottischen Edinburgh Parallel Computing Center (epcc) sammelten drei Jahre Erfahrung mit ihrem HPE-Apollo-70-System namens Fulhame. Es ist mit ThunderX2-Prozessoren von Cavium (jetzt Marvell) bestückt. Fulhame ist eine kleinere Ausführung des "Astra" am Sandia National Lab, der auf Platz 393 in der Top500 gelistet ist.

(Bild: eppc, Edinburgh)
Die Schotten hatten sich gefreut, dass SLES 15 for HPC endlich SLURM und Lustre-Support brachte, auch wenn es ein paar Performance-Probleme mit Lustre gab. MPI machte ebenfalls Probleme, aber nur bei sehr großen Messages größer als 16 GByte, und auch mit den Infiniband-Treibern für Mellanox hakte es. Diese Macke weisen neuere SLES-15-Versionen nun nicht mehr auf, blöd nur, dass sie Lustre nicht mehr unterstützen. Da bleiben die Schotten lieber beim alten SLES 15.
Ein schönes Projekt läuft derweil an der Universität Stony Brooks (SBU) unter dem Namen Ookami (Wolf): ein A64FX-System für "fast jeden". Forscher aus aller Welt können sich anmelden, um kostenlose Rechenzeit zu erhalten. Das klappt laut Eva Siegmann von SBU sehr gut. Die User erreichen schnell eine gute Performance, bei speicherintensiven Anwendungen oft mehr als auf vergleichbaren Intel/AMD-Rechnern. Mit MPI gibt's jedoch mitunter Probleme, denn alle MPI-Bibliotheken weisen "Issues" auf, so Siegmann.
Für richtig hohe Rechenperformance muss man SVE gezielt ansprechen, allerdings sind die Compiler und Toolchains noch nicht so ganz ausgereift. GNU-C/C++ bietet zwar SVE an, es fehlen aber wichtige Vektor-Bibliotheken. Fujitsu und Cray besitzen zwar solche Bibliotheken für ihre jeweiligen Compiler, aber letztere hängen sechs Jahre zurück und stehen noch auf dem Stand von C++14.
ARM selbst hat auf Basis von LLVM 11 wiederum eine eigene Toolchain, die bezüglich C++ zwar auf dem Laufenden (C++20) ist – aber FORTRAN fällt ab, OpenMP wird nur bis V3.2 und Fortran 2008 lediglich partiell unterstützt.


(ciw)
