

Nvidia erweitert Stable Diffusion zum hochauflösenden Text-zu-Video-Generator
Ein Nvidia-Forscherteam arbeitet an einem latenten Diffusionsmodell für hochaufgelöste Videos am Beispiel des Text-zu-Bild-Generators Stable Diffusion.

Nvidias Video-LDM erzeugt Bewegtbilder
(Bild: NVIDIA)
Text-zu-Video-Generatoren wie Metas Make-a-Video erzeugen bisher meist Videos mit einer geringen Auflösung. Nvidias AI Lab hat mit Wissenschaftlern der Universitäten Toronto, München und Waterloo ein Model entwickelt, das aus dem Text-zu-Bild-Generator Stable Diffusion einen Text-zu-Video-Generator (Video-LDM) für hochaufgelöste Videosequenzen gemacht hat. Ihr Vorgehen beschreiben Sie in dem Paper "Align you Latents – High-Resolution Video Synthesis with Latent Diffusion Models" (PDF), an dem unter anderem Andreas Blattmann und Robin Rombach von der LMU München beteiligt waren, die bereits den Text-zu-Bild-Generator Stable Diffusion mitentwickelt hatten.
Das Paper konzentriert sich auf zwei Anwendungsfälle: Erzeugung kreativer Videoinhalte und simulierte Autofahrten. Für den kreativen Einsatz wurde das Video-LDM auf dem WebVid-10M-Videodatensatz trainiert – ein umfangreicher Datensatz von Kurzvideos mit Textbeschreibungen von Stock-Footage-Websites. Für die Autofahrten griffen die Forschenden auf Dashcam-Videos zurück.
Wie bei Stable Diffusion selbst nutzten die Forscher aus, dass latente Diffusionsmodelle (LDMs) eine qualitativ hochwertige Bildsynthese ermöglichen und gleichzeitig übermäßigen Rechenaufwand vermeiden, indem sie ein Diffusionsmodell in einem latenten (komprimierten) Raum trainieren. Zunächst wurde das Modell auf Bilddaten vortrainiert, anschließend um eine zeitliche Dimension erweitert und fein abgestimmt. Die Forscher betonen, dass ihr Modell mit beliebigen Text-zu-Bild-Generatoren zusammenarbeitet, beispielsweise Dreambooth.
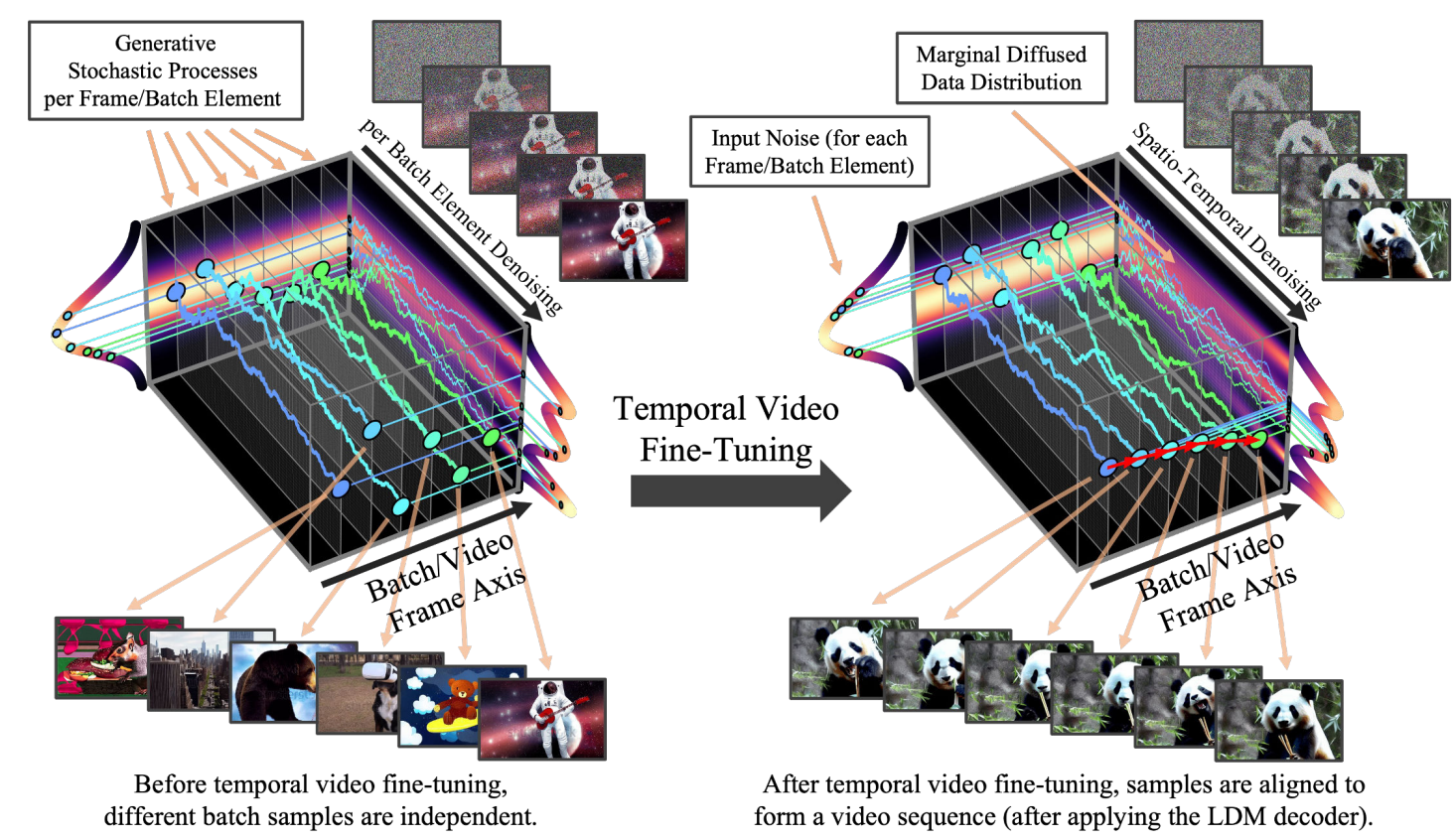
(Bild: NVIDIA Toronto AI Lab)
Das Video-LDM erzeugt 4,7 Sekunden lange Bewegtbildsequenzen mit einer Auflösung von bis zu 2048 × 1024 Pixeln bei 24 Bildern pro Sekunde oder 3,8 Sekunden lange Videos mit 30 Bildern pro Sekunde. Auf der Video-LDM-Projektseite führen die Forscher zahlreiche Beispiele auf, etwa "a teddy bear is playing the electric guitar, high definition, 4k":
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes Video (TargetVideo GmbH) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (TargetVideo GmbH) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
oder "two pandas sitting at a table playing, 4k, high resolution":
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes Video (TargetVideo GmbH) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (TargetVideo GmbH) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Video-LDM als Fahrsimulator
Ferner hat das Team sein Video-LDM auf einem umfangreichen Datensatz aus Dashcam-Videos trainiert und teils auch zusätzliche Vorhersagemodelle eingesetzt, die über die Zeit von sich selbst abhängen (autoreggressiv), um so längere Videosequenzen zu erzeugen. So entstanden minutenlange Autofahrvideos mit einer Auflösung von 1024 × 512 Pixeln. Das Video-LDM kann dabei unterschiedliche, plausible Szenarien vorhersagen. Als einen möglichen Anwendungsfall für solche Videogeneratoren sehen die Forscher beispielsweise Fahrsimulationen.
Siehe auch.
- Stable Diffusion bei heise Download


(mack)
