

Große Sprachmodelle: BSI warnt vor manipulierenden Prompts
Angriffe durch Indirect Prompt Injections bei KI-Sprachmodellen sind dem Bundesamt für Sicherheit in der Informationstechnik zufolge schwer zu verhindern.

(Bild: Shutterstock/Wit Olszewski)
Große KI-Sprachmodelle (LLMs) entwickeln sich rasant und werden immer öfter in Anwendungen integriert. Inzwischen können einige Chatbots über Plug-ins Internetseiten oder Dokumente automatisiert auswerten und sogar auf Programmierumgebungen oder E-Mail-Postfächer zugreifen. Darum will das Bundesamt für Sicherheit in der Informationstechnik (BSI) "für mögliche Risiken beziehungsweise Limitierungen der Technologie" mit einer Warnung der Stufe 1 für die relativ neue Schwachstellenklasse sensibilisieren. Ein manipulierter Chatbot könnte, "ähnlich wie bei einem Social Engineering Angriff, unter Umständen glaubhaft argumentieren [...], warum eine (schadhafte) Aktion" unbedingt genehmigt werden muss.
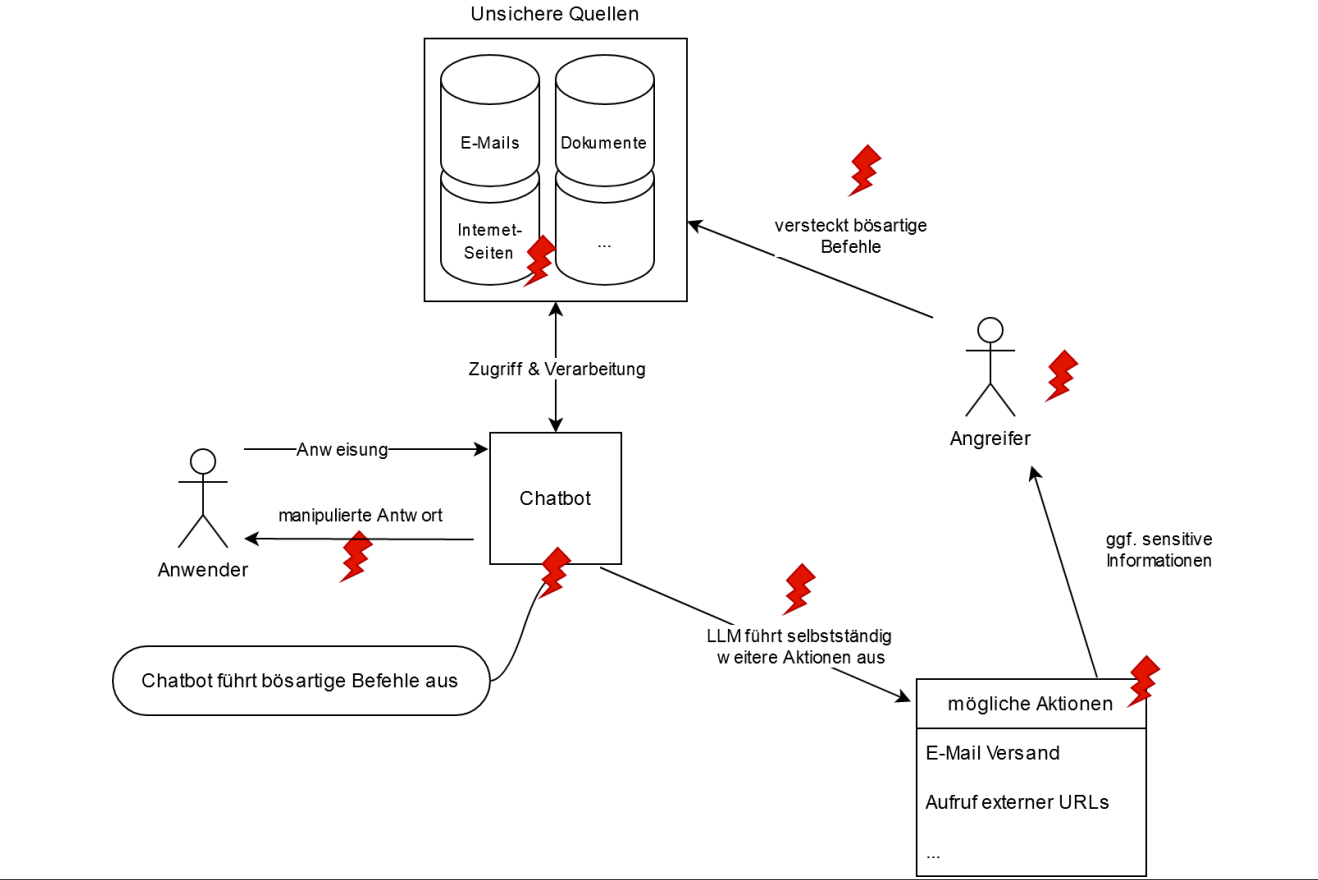
Die Risiken durch "Indirect Prompt Injections" seien ernst zu nehmen und "entstehen bei der Verarbeitung von Informationen aus unsicheren Quellen durch LLMs", heißt es in der Cybersicherheitswarnung. Angreifer können Daten aus den zweifelhaften Quellen ungeprüft verarbeiten, sie manipulieren und unerwünschte Befehle in LLMs platzieren, ausführen und deren Verhalten gezielt manipulieren. Aktuell gibt es im IT-Sicherheitsbereich noch keine "Best-Practices". Dass Texte sowohl in der menschlichen Kommunikation Informationen übermitteln, aber auch Befehle erteilen können, werde "auch in die IT-Sphäre übertragen". Eine klare Trennung zwischen Daten und Anweisungen gibt es demnach auch bei den LLMs nicht. "Da dies eine intrinsische Schwachstelle der derzeitigen Technologie ist, sind Angriffe dieser Art grundsätzlich schwierig zu verhindern", so das BSI.
Eine "zuverlässig und nachhaltig sichere Mitigationsmaßnahme [...] die nicht auch die Funktionalität deutlich einschränkt" ist dem BSI nicht bekannt. Somit müssen Anwender und Entwickler Vorsicht walten lassen. Verstärkt würden die Auswirkungen der Schwachstelle dadurch, dass LLMs als teils autonome Systeme agieren können. Für Anwender sei es schwierig, derartige Angriffe zu erkennen, auch wenn sie die Quellen prüfen. Das BSI empfiehlt bei der Integration von LLMs in Apps daher, "eine systematische Risikoanalyse" durchzuführen. Hilfreich sei auch, den Zugriff auf unsichere Quellen auszuschließen oder dass vor möglicherweise kritischen Aktionen ein Mensch eine Anfrage bestätigen muss. Der Einsatz einer Sandbox bei bestimmten Aktionen oder Penetrationstests seien ebenfalls hilfreich.
Gefährliche Befehle versteckt
Es gibt zahlreiche Möglichkeiten, bei denen die Nutzer nicht erkennen, dass es sich um potenziell schädliche Befehle handelt. Diese können verschlüsselt oder versteckt sein und werden vom Benutzer unter Umständen gar nicht bemerkt – etwa, weil Texte auf Websites in Schriftgröße null oder in einem Videotranskript versteckt sind oder weil sie vom Menschen schwer lesbar kodiert sind. Eine weitere Möglichkeit sei laut BSI, dass Nutzer nach Chatbot-Anfragen aufgrund weiterer durch den Webserver aufgerufene Parameter andere Antworten erhalten.
Erst kürzlich hat ein Student von der Technischen Universität München, Martin von Hagen, auf Prompt Injections bei Bing aufmerksam gemacht. Er hat mit seiner Eingabe in den Chatbot eine Liste mit den Regeln der KI erhalten, eine, die Hersteller eigentlich geheim halten wollen. Dass es bei ChatGPT noch offene Fragen bezüglich der IT-Sicherheit gibt, weiß auch OpenAI selbst. Das Unternehmen will daran arbeiten, zu verhindern, dass "nicht vertrauenswürdige Daten aus der Ausgabe eines Tools das Modell anweisen können, unbeabsichtigte Aktionen auszuführen". Außerdem empfiehlt OpenAI, "nur Informationen von vertrauenswürdigen Tools" zu nutzen und dass Entwickler vor bestimmten Aktionen zusätzliche Möglichkeiten zur Bestätigung von Aktionen einbauen sollen, etwa beim Senden von E-Mails oder vor einem Online-Kauf. Es gibt laut BSI verschiedene Risiken beim Einsatz von LLMs, die stark von den vergebenen Rechten und möglichen Aktionen abhängen.
Videos by heise
Angreifer können gezielt Ergebnisse manipulieren
Bei der automatischen Textverarbeitung aus externen Quellen können Angreifer Ergebnisse gezielt manipulieren. Sofern der Chatbot auf modifizierte Seiten zugreifen kann, warnt das BSI vor verschiedenen Szenarien und bezieht sich auch auf die Einschätzung des Open Web Application Security Project (PDF). Der Chatbot könnte demnach:
- rechtlich bedenklich oder unerwünschte Aussagen treffen
- Nutzer zum Aufrufen bösartiger Links motivieren
- versuchen, sensitive Informationen zu erhalten (etwa über Kreditkarten)
- selbst weitere Plug-ins aufrufen
Auf diese Weise sei Angreifern ein Zugriff auf das E-Mail-Konto oder mehr möglich. Falls ein "autonomer Agent" lokal in einem Docker-Container läuft und über einen API-Zugriff des LLMs verfügt, sei auch ein Ausbruch aus dem Docker-Container denkbar, was weitreichende Root-Rechte des Angreifers zur Folge hätte.
(Bild: BSI)
Bereits im Februar wurde diese neue Schwachstellenklasse wissenschaftlich diskutiert, woraufhin das BSI das Positionspapier "Große Sprachmodelle - Chancen und Risiken für Industrie und Behörden" veröffentlicht hatte.


(mack)
