
Softwareentwicklung: Optimierung mit Allokatoren in C++17
Das Ende der Miniserie zu C++17 stellt die polymorphen Allokatoren zum Optimieren der Speicherzuweisung vor.

- Rainer Grimm
Polymorphe Allokatoren in C++17 helfen dabei, die Speicherzuweisung sowohl auf die Performanz als auch auf die Wiederverwendung von Speicher zu optimieren.

Performanz
Das folgende Programm stammt von cppreference.com/monotonic_buffer_resource. Ich werde seinen Performanz-Test für Clang und den MSVC-Compiler erweitern und erklären.
// pmrPerformance.cpp
// https://en.cppreference.com/w/cpp/memory/monotonic_buffer_resource
#include <array>
#include <chrono>
#include <cstddef>
#include <iomanip>
#include <iostream>
#include <list>
#include <memory_resource>
template<typename Func>
auto benchmark(Func test_func, int iterations) // (1)
{
const auto start = std::chrono::system_clock::now();
while (iterations-- > 0)
test_func();
const auto stop = std::chrono::system_clock::now();
const auto secs = std::chrono::duration<double>(stop - start);
return secs.count();
}
int main()
{
constexpr int iterations{100};
constexpr int total_nodes{2'00'000};
auto default_std_alloc = [total_nodes] // (2)
{
std::list<int> list;
for (int i{}; i != total_nodes; ++i)
list.push_back(i);
};
auto default_pmr_alloc = [total_nodes] // (3)
{
std::pmr::list<int> list;
for (int i{}; i != total_nodes; ++i)
list.push_back(i);
};
auto pmr_alloc_no_buf = [total_nodes] // (4)
{
std::pmr::monotonic_buffer_resource mbr;
std::pmr::polymorphic_allocator<int> pa{&mbr};
std::pmr::list<int> list{pa};
for (int i{}; i != total_nodes; ++i)
list.push_back(i);
};
auto pmr_alloc_and_buf = [total_nodes] // (5)
{
// enough to fit in all nodes:
std::array<std::byte, total_nodes * 32> buffer;
std::pmr::monotonic_buffer_resource mbr{buffer.data(),
buffer.size()};
std::pmr::polymorphic_allocator<int> pa{&mbr};
std::pmr::list<int> list{pa};
for (int i{}; i != total_nodes; ++i)
list.push_back(i);
};
const double t1 = benchmark(default_std_alloc, iterations);
const double t2 = benchmark(default_pmr_alloc, iterations);
const double t3 = benchmark(pmr_alloc_no_buf , iterations);
const double t4 = benchmark(pmr_alloc_and_buf, iterations);
std::cout << std::fixed << std::setprecision(3)
<< "t1 (default std alloc): " << t1
<< " sec; t1/t1: " << t1/t1 << '\n'
<< "t2 (default pmr alloc): " << t2
<< " sec; t1/t2: " << t1/t2 << '\n'
<< "t3 (pmr alloc no buf): " << t3
<< " sec; t1/t3: " << t1/t3 << '\n'
<< "t4 (pmr alloc and buf): " << t4
<< " sec; t1/t4: " << t1/t4 << '\n';
}Dieser Performanz-Test in (1) führt die Funktionen in (2) - (5) hundertmal aus (constexpr int iterations{100}). Jeder Aufruf der Funktionen erzeugt eine std::pmr::list<int> mit zweihunderttausend Knoten (constexpr int total_nodes{2'00'000}). Die Knoten der einzelnen Listen werden auf unterschiedliche Weise allokiert:
- (2):
std::list<int>verwendet den globalenoperator new - (3):
std::pmr::list<int>verwendet die spezielle Speicherressourcestd::pmr::new_delete_resource - (4):
std::pmr::list<int>verwendetstd::pmr::monotonic_bufferohne einen vorab zugewiesenen Puffer auf dem Stack - (5):
std::pmr::listverwendetstd::pmr::monotonic_buffermit einem vorab zugewiesenen Puffer auf dem Stack
Der Kommentar zur letzten Funktion (5) behauptet, dass auf dem Stack genug Platz ist, um alle Knoten unterzubringen: "enough to fit in all nodes". Das war auf meinem Linux-PC richtig, aber nicht auf meinem Windows-PC. Unter Linux ist die Standardgröße für den Stack 8 MByte, unter Windows aber nur 1 MByte. Das hatte zur Folge, dass meine Programmausführung unter Windows mit dem MSVC-Compiler und dem Clang-Compiler lautlos fehlschlug. Ich habe das Problem behoben, indem ich mithilfe von editbin.exe die Stack-Größe meiner MSVC- und Clang-Executables geändert habe:

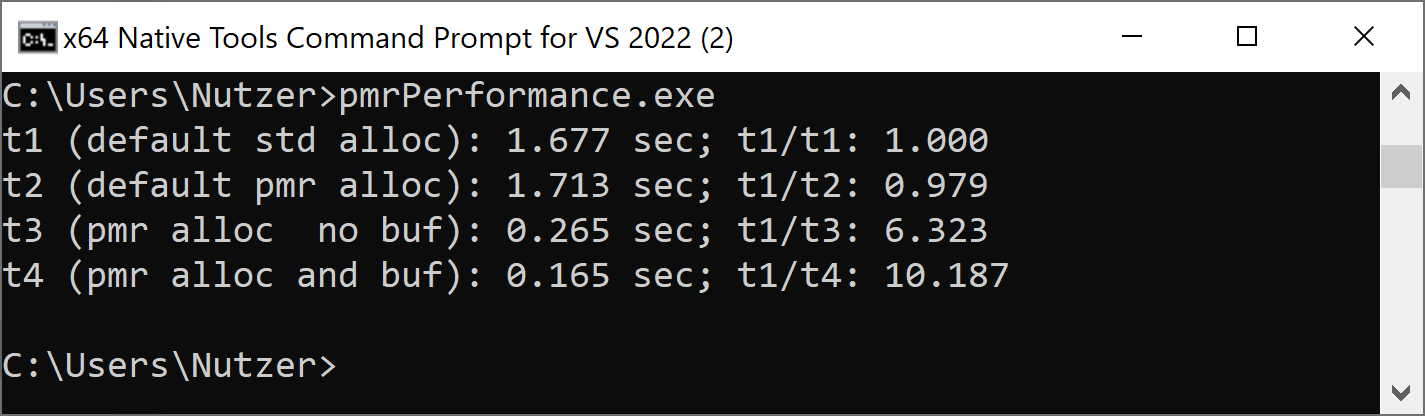
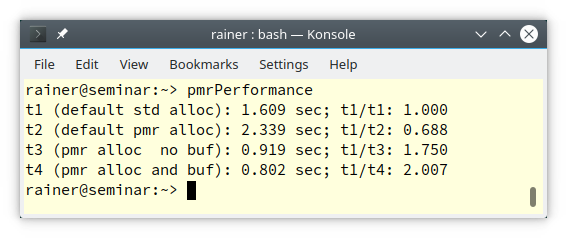
Hier sind endlich die Zahlen. Der Referenzwert ist die Zuweisung mit std::list<int> (Zeile 2). Vergleiche nicht die absoluten, sondern die relativen Zahlen, denn ich habe einen virtualisierten Linux-PC und einen nicht-virtuellen Windows-PC verwendet. Natürlich habe ich die maximale Optimierung aktiviert. Das bedeutet (/Ox) für den MSVC Compiler und (-Ox) für die GCC und Clang Compiler.
- Clang Compiler
- GCC Compiler
- MSVC-Compiler

Interessanterweise war die Speicherzuweisung mit der Speicherressource std::pmr::new_delete_resource immer die langsamste. Im Gegenteil dazu stellt std::pmr::monotonic_buffer die schnellste Speicherzuweisung dar. Das gilt vor allem, wenn man einen vorab zugewiesenen Puffer auf dem Stack verwendet. Auf Windows ist dadurch die Speicherallokation etwa zehnmal schneller.


Die mit C++20 eingeführten Concepts haben zusammen mit der Ranges-Bibliothek, Modulen und Coroutinen das Erstellen von modernen C++- Anwendungen neu definiert. Vom 7. bis zum 9. November 2023 bringt Sie Rainer Grimm in seinem Intensiv-Workshop C++20: die neuen Konzepte umfassend erklärt auf Stand und geht auf die vielen nützlichen Funktionen ein, die C++20 mitbringt.
Die Speicherressource std::pmr::new_delete_resource bietet noch mehr Optimierung an.
Wiederverwendung von Speicher
std::pmr::monotonic_buffer ermöglicht die Wiederverwendung von Speicher, sodass man sich das Freigeben des Speichers sparen kann.
// reuseMemory.cpp
#include <array>
#include <cstddef>
#include <iostream>
#include <memory_resource>
#include <string>
#include <vector>
int main() {
std::array<std::byte, 2000> buf;
for (int i = 0; i < 100; ++i) { // (1)
std::pmr::monotonic_buffer_resource pool{buf.data(),
buf.size(), // (2)
std::pmr::null_memory_resource()};
std::pmr::vector<std::pmr::string> myVec{&pool};
for (int j = 0; j < 16; ++j) { // (3)
myVec.emplace_back("A short string");
}
}
}Dieses Programm allokiert ein std::array mit 2000 Bytes: std::array<std::byte, 2000>. Dieser vom Stack zugewiesene Speicher wird hundertmal wiederverwendet (1). Der std::pmr::vector<std::prm::string> verwendet die std::pmr::monotonic_buffer_resource mit der upstream-Speicherressource std::pmr::null_memory_resource (2). Schließlich werden auf den Vektor 16 Strings geschoben.
Wie geht's weiter?
Dieser Artikel beendet meine Miniserie über die polymorphen Speicherressourcen in C++17. In meinem nächsten Artikel werde ich drei Jahre weiter springen und meine Reise durch C++20 fortsetzen. (rme)
