
Wolkenintelligenz: Google Cloud Machine Learning Engines
Machine Learning Modelle werden trainiert und im Anschluss zur Abfrage bereitgestellt. Die Google Cloud bietet für beide Szenarien umfangreiche Optionen.

Google Cloud Machine Learning Engines
(Bild: iStockphoto.com - Guillaume)
- Lars Röwekamp
Die ersten zwei Blog-Artikel der Kurzserie Wolkenintelligenz haben die verschiedenen Optionen zum Training und zur Inferenz von Machine Learning Modellen in den Cloud-Umgebungen AWS von Amazon und Azure von Microsoft aufgezeigt. Der dritte Teil nimmt die Google Cloud unter die Lupe.

Videos by heise
Die Google Cloud bietet zwei grundsätzlich unterschiedliche Varianten an, GPU-beschleunigte VMs zu erstellen. In der ersten Varianten kann aus einer Liste vorkonfigurierter Kombinationen aus vCPUs, GPUs und Speicher die passende ausgewählt werden. Dies ist für die VM-Familien G2 und A2 möglich.

(Bild: open knowledge - Google Cloud Console)
Etwas komplizierter, dafür aber auch deutlich flexibler stellt sich die zweite Variante dar, die auf VMs der N1-Familie aufsetzt. VMs dieses Typs können nahezu frei bezüglich Anzahl an vCPUs, Art und Anzahl an GPUs und Größe des Speichers konfiguriert werden.

(Bild: open knowledge - Google Cloud Console)
Bei beiden Varianten – Rundum-sorglos-Paket und individuell konfigurierbare Kombination – sieht man noch vor dem Erstellen der VM die für die gewählte Kombination zu erwartenden Kosten pro Stunde und pro Monat. Ein nützliches kleines Feature, dass daran erinnert, VMs nur dann aktiv zu halten, wenn man sie benötigt. Eine VM in der Cloud aus Bequemlichkeit laufen zu lassen, kann schnell teuer werden.
Rundum-sorglos-Machine-Learning-VMs
Die GPU-gestützten VMs der G2-Familie sind noch relativ jung. Sie wurden erst im Frühjahr diesen Jahres in der Google Cloud eingeführt. Der primäre Einsatzzweck der VMs ist die Inferenz, also die Abfrage, von bereits trainierten Modellen. VMs vom Typ G2 können aber auch für das Training von ML-Modellen verwendet werden, solange diese überschaubar groß sind und nicht zu viele Daten benötigen. Als GPU kommt bei G2-VMs die ebenfalls relativ neue Nvidia L4 Tensor Core GPU auf Basis der Ada-Lovelace-Architektur zum Einsatz. Die L4-GPU ist die direkte Nachfolgerin der bekannten T4-GPU und sticht insbesondere durch ihre positive Kosten- und Energieeffizienz hervor. Laut Angaben des Herstellers kann mit ihr eine 2.5x bessere Performanz gegenüber des Vorgängermodells T4 erreicht werden.


Dieser Artikel ist auch in dem Sonderheft "Cloud Native" von iX Developer erschienen. Es zeigt auf 154 Seiten aktuelle Methoden für die Entwicklung im Cloud-nativen Umfeld. Die Artikel beleuchten sämtliche Stationen im Softwarelebenszyklus von der Infrastruktur über die CI/CD-Pipelines in der Softwareentwicklung bis hin zur Überwachung, Security und Governance von Anwendungen.
Ein wichtiger Part sind dabei die Kosten und die Nachhaltigkeit. Der Abschnitt zeigt die unterschiedlichen Angebote von AWS, Microsoft und Google für KI-Anwendungen in der Cloud. Außerdem hilft ein Artikel dabei, Kosten in der Cloud zu reduzieren.
Das Spektrum der verfügbaren G2-VM-Konfigurationen ist breit gefächert. Beginnend bei lediglich einer GPU mit 24 GByte GPU-Speicher kombiniert mit vier vCPUs und 16 GByte Arbeitsspeicher geht es hoch bis zu acht GPUs mit 192 GByte GPU-Speicher kombiniert mit 96 vCPUs mit insgesamt 384 GByte Arbeitsspeicher. Als lokale SSDs stehen je nach Variante Speichergrößen von 375 GByte bis 3000 GByte zur Verfügung. Entsprechend unterschiedlich sind die Preismodelle der einzelnen G2-VMs. Beginnend bei deutlich unter einem Euro pro Stunde für die kleinste Variante, steigt der Preis in der Region Europe West auf immerhin fast zehn Euro pro Stunde für die maximale Ausbaustufe. Das klingt nicht viel, belastet das Konto aber immerhin mit fast 6.500 Euro im Monat, wenn die Instanz

(Bild: open knowledge)
Für das Training größerer ML-Modelle bieten sich die Google Cloud VMs der A2-Familie an. Maschinen vom Typ A2 bieten CUDA-fähiges ML-Training und -Interferenz und erlauben eine massiv parallele Berechnung. Ermöglicht wird das durch die Nvidia A100-GPUs.
Während A2-Standardmaschinen auf Nvidia A100-GPUs mit 40 GByte Speicher aufsetzen, nutzen A2-Ultra-Maschinentypen die deutlich performantere Variante mit 80 GByte. Gleichzeitig ist bei ihnen der für die vCPUs verfügbare Speicher mit 170 GByte doppelt so hoch wie bei den A2-Standardmaschinen. Dadurch eignen sich die A2-Ultras besonders für den rechenintensiven Einsatz in Verbindung mit dem BERT-Modell für Natural Language Processing und für Deep Learning Recommendation Models (DLRM).

(Bild: open knowledge)
Die Preise der A2-Maschinentypen unterscheiden sich aufgrund der deutlich höheren Leistungsdaten stark von den G2-Maschinentypen. Bereits die kleinste Ausbaustufe mit nur einer GPU und einer vCPU kostet knapp unter 4 Euro (A100-GPU 40 GB) bzw. 5,50 Euro (A100-GPU 80 GB) pro Stunde. Deutlich teurer wird es bei den maximalen Ausbaustufen. Hier schlagen die A2-Ultras mit 8 GPUs und 96 vCPUs bei 1,3 TByte Speicher mit etwa 45 Euro pro Stunde zu buche. Noch höher fallen die Kosten bei den A2-Standardmaschinen aus, was mit der größeren Anzahl an möglichen GPUs – 16 statt 8 – zusammenhängt. Bei knapp 55 Euro pro Stunde würde sich im Monat ein stolzer Betrag von über 40.000 Euro ergeben. An dieser Stelle ist ein Zitat aus der Kinderserie Löwenzahn angebracht: „Abschalten nicht vergessen!“.

(Bild: open knowledge)
Machine Learning VMs im Bastelset
Anders als bei den bisher vorgestellten VM-Familien G2 und A2, bietet Google bei den VMs der N1-Familie keine vorkonfigurierten CPU-/GPU-Pakete. Stattdessen liegt es in der Verantwortung der Nutzer, die für den eigenen Kontext passende Kombination zu erstellen. Das ist zwar mit ein wenig Aufwand verbunden, bietet aber gleichzeitig eine deutlich höhere Flexibilität – auch in Hinblick auf den Preis.
Für die Grundkonfiguration der N1-VMs stehen zwischen einer und 96 vCPUs zur Auswahl, die sich je nach gewählter vCPU-Anzahl mit bis zu 624 GByte Speicher kombinieren lassen. Theoretisch könnte man sogar bei der größten Ausbaustufe an vCPUs mit nur einem GByte Speicher arbeiten. Auch wenn das in der Praxis nicht sinnvoll ist, zeigt es, dass man die N1-VMs flexibel auf die eigenen Bedürfnisse zuschneiden kann.
Steht die Grundkonfiguration für die N1-VM, gilt es sie mit einer oder mehreren GPUs zu verbinden. Hierzu stehen folgende GPUs zur Auswahl:
- Nvidia Tesla P4-GPU auf Basis der Pascal-Architektur
- Nvidia Tesla T4-GPU auf Basis der Turing-Architektur
- Nvidia Tesla P100-GPU auf Basis der Pascal-Architektur
- Nvidia Tesla V100-GPU auf Basis der Volta-Architektur
Während sich die ersten beiden Optionen mit den Low-Energy-GPUs P4 und T4 aufgrund ihrer technischen Daten insbesondere für das Training und die Inferenz von kleinen und mittelgroßen ML-Modellen anbieten, zielen die beiden High-End-GPU-Varianten P100 und V100 auf große bis sehr große ML-Modelle.
Neben den vier gezeigten GPUs bietet die Google Cloud in Kombination mit der N1-VM noch die etwas in die Jahre gekommene Nvidia Tesla K80 GPU auf Basis der Kepler-Architektur an. Da Google diesen GPU-Typ aber zum 1. Mai 2024 einstellen werden wird, ist der Einsatz nicht zu empfehlen.
Cloud Engines für kleine und mittelgroße ML-Modelle
Die Kombination der N1-VM mit Nvidia T4-GPUs ist mit einer, zwei oder vier GPUs und entsprechend 16 GByte bis 64 GByte GPU-Speicher möglich. Die Preise variieren von knapp 30 Eurocent pro Stunde für die kleinste Ausbaustufe mit einer T4-GPU und nur einer vCPU bis hin zu 4,50 Euro pro Stunde in der maximal möglichen Ausbaustufe mit vier T4-GPUs und 96 vCPUs. Eine N1-VM mit Nvidia T4-GPUs zu kombinieren, ist vor allem aufgrund des guten Preisleistungsverhältnisses sinnvoll. Zwar sind die Einsatzmöglichkeiten dieser Kombination limitiert, für das Training kleiner bis mittlerer Modelle sowie deren Inferenz reicht es aber allemal.
Für die Nvidia Tesla P4-GPU gelten dieselben Ausbauvarianten wie für die Kombinationen von N1-VM und T4-GPUs. Interessant ist, dass die Preise trotz geringerer Leistung im Vergleich höher ausfallen. In der minimalen Ausbaustufe mit einer Nvidia Tesla P4-GPU und nur einer vCPU fallen circa 50 Eurocent pro Stunde an. Die maximale Ausbaustufe mit vier Nvidia Tesla P4-GPUs und 96 vCPUs schlägt mit ca. 5,50 Euro zu buche. Eine N1-VM mit P4-GPUs ist somit in etwa 20% teurer als die gleiche VM mit T4-GPUs. Aufgrund des deutlich schlechteren Preisleistungsverhältnisses gibt es eigentlich keinen Grund, der P4-GPU gegenüber ihrem direkten Nachfolger T4 den Vorzug zu geben. Selbst der Energieverbrauch ist bei der T4-GPU mit 70 Watt um 5 Watt geringer als bei der P4-GPU.

(Bild: open knowledge)
Die beiden vorgestellten N1-VM-GPU-Kombinationen sind eher am unteren bis mittleren Leistungsspektrum anzusiedeln und lassen sich somit in das Einsatzszenario der G2-VM-Familie einordnen. Ein Vergleich der Preise von vorkonfigurierter G2-VM und N1-VM mit individuell gewählten GPUs zeigt, dass sich durch eine individuelle Konfiguration einiges an Geld sparen lässt. Natürlich hinkt der Vergleich ein wenig, da die G2-VMs mit der Nvidia L4 Tensor Core GPU auf der jüngsten Generation der Nvidia Low-Energy GPUs aufsetzen, die in den Leistungsdaten ihren Vorgängern T4 und P4 gegenüber in nahezu allen Belangen überlegen ist.
Cloud Engines für große und sehr große ML-Modelle
Deutlich leistungsstärker, aber auch entsprechend teurer fällt eine Kombination einer N1-VM mit P100- oder V100-GPUs aus. Vom Einsatzszenario her sind diese Kombinationen mit den vorkonfigurierten A2-Maschienentypen vergleichbar und eignen sich somit für das Training und die Inferenz von großen bis sehr großen Modellen. Entsprechend ähnlich, wenn auch aufgrund der schwächeren Leistungsdaten günstiger, sind die Preisstrukturen.
Bei der Auswahl einer Nvidia Tesla P100-GPU kann man zwischen einer und vier GPUs mit jeweils 16 GByte GPU-Speicher wählen. Die Anzahl der angebotenen vCPUs reicht von 1 bis 96 bei einem Arbeitsspeicher von maximal 624 GByte. Die Preise variieren von etwas gut einem Euro pro Stunde für eine vCPU und eine GPU – zugegeben eine eher theoretische als praxistaugliche Kombination – bis zu knapp 8 Euro pro Stunde für vier GPUs und 96 vCPUs.
Wer es noch performanter mag, kann auf die, laut Angaben des Herstellers Nvidia etwa dreimal schnellere V100-GPU zurückgreifen. Mit ihr sind Kombinationen mit bis zu acht GPUs mit jeweils 16 GByte GPU-Speicher und 96 vCPUs möglich. Die Preise starten bei etwas unter 2 Euro pro Stunde für die kleinste Ausbaustufe mit einer GPU und einer vCPU und gehen bis maximal 18 Euro pro Stunde bei acht GPUs und 96 vCPUs. Damit liegen die Preise bei gleicher Anzahl an GPUs und vCPUs deutlich unter denen der für dieselben Aufgaben vorkonfigurierten A2-Maschinentypen.

(Bild: open knowledge)
Ist teuer wirklich teuer?
Beim Blick auf die Leistungsdaten und die damit verbundenen Preisstrukturen stellt sich die Frage, welche Kombination am Ende zum besten Preis-Leistungs-Verhältnis führt. Darauf gibt es keine pauschale Antwort, sondern man muss den eigenen Kontext betrachten: die Art und Größe des eingesetzten Modells sowie die zum Training und zu Inferenz benötigten Datenmengen.
Da bei leistungsstärkeren CPU-GPU-Speicher-Kombinationen in der Regel die Bearbeitungszeit sinkt, kann es durchaus sinnvoll sein, auf eine scheinbar teurere Kombination zurückzugreifen, um so in der Multiplikation aus Preis pro Stunde und benötigter Rechenzeit auf einen besseren Preis-Leistungs-Koeffizienten zu kommen.
Wie Kunden sich eine Berechnungsgrundlage für eine belastbare Entscheidung erstellen können, lässt sich in den Blogbeiträgen „Your ML worloads cheaper and faster with the latest GPUs“ von Google und „Saving time and money in the cloud with the latest Nvidia-prowered instances” von Nvidia nachlesen.
Da die Beiträge von den Anbietern stammen, sind sie mit der notwendigen Vorsicht zu genießen. Trotzdem lässt sich aus ihnen gut herleiten, wie das Preis-Leistungs-Verhältnis der gewählten CPU-GPU-Speicher-Kombination im eigenen Kontext zu bewerten ist. Folgende Abbildung zeigt den Vergleich der potenziellen Kosten für das Training großer ML-Modelle mit den beiden Nvidia GPUs A100 und V100.
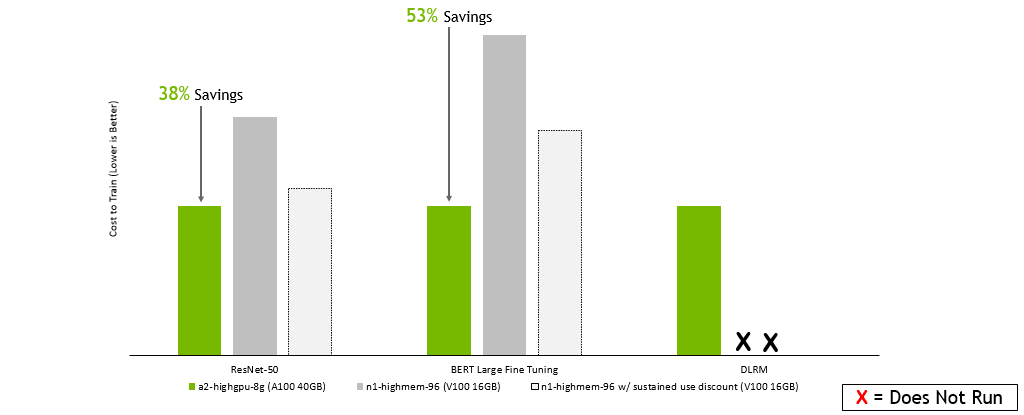
(Bild: Quelle: NVIDIA Tech-Blog)
Von der Stange oder maßgeschneidert
Die Google Cloud bietet ein breites Spektrum an GPU-gestützten virtuellen Maschinen. Kunden können frei entscheiden, ob sie für das Training und die Inferenz ihrer ML-Modelle eine der vorkonfigurierten VMs von Typ G2 oder A2 wählen oder stattdessen ihre eigene Wunschkonfiguration auf Basis von N1-VMs und einer der Nvidia GPUs P4, T4, P100 und V100 zusammenstellen.
Ein direkter Vergleich der Kosten zwischen den beiden Varianten ist nicht sinnvoll, da die Google Cloud bei den Rundum-sorglos-Paketen G2 und A2 bewusst auf die jeweils neueren Nvidia GPUs L4 und A100 setzt, während bei den individuell konfigurierbaren N1-VMs lediglich deren Vorgänger T4 und P4 beziehungsweise P100 und V100 zur Auswahl stehen.
Beide Varianten haben aber durchaus ihre Daseinsberechtigung. Welche am Ende für den eigenen Kontext zu besseren Ergebnissen bezüglich Performanz und Preis-Leistung führt, gilt es auf Basis des eigenen Modells und der damit zu verarbeitenden Daten zu entscheiden.
Um den Einstieg in die Welt der GPU-basierten Maschinentypen ein wenig zu erleichtern, bietet Google eine Übersicht der innerhalb der Google Cloud verfügbaren beschleunigungsoptimierten Maschinentypen an. Eine Auflistung und Beschreibung der verfügbaren GPU-Plattformen und ihrer Leistungsdaten sowie der mit ihnen verbundenen Abrechnungsmodelle und konkreten Kosten ergänzen die Übersicht.
Wer erste Erfahrungen mit Machine Learning in der Google Cloud sammeln möchte, ohne einen Google-Cloud-Account anzulegen und eine eigene VM aufzusetzen, sei auf den Google Cloud Service namens Colab verwiesen. Dabei handelt es sich um einen von Google gehosteten Jupyter-Notebook-Dienst, der einen kostenlosen Zugang zu Rechenressourcen einschließlich GPUs und TPUs bietet und keine Konfiguration im Vorfeld erfordert. Dazu aber mehr in einem späteren Blogbeitrag.
In diesem Sinne „stay connected!“
(rme)
