

Toolbox: Texterkennung mit OCRmyPDF
Mit dem Konsolentool OCRmyPDF unterziehen Sie gescannte Dokumente einer Texterkennung und generieren eine durchsuchbare PDF-Datei im PDF/A-Format. Dabei kombiniert OCRmyPDF geschickt verschiedene Linux-Tools.
Um ein digital archiviertes Dokument möglichst schnell wiederzufinden, sollte es als durchsuchbare PDF-Datei gespeichert sein. Scans, die nur als PDF-Dateien mit eingebetteten Bitmaps, aber ohne Text vorliegen, lassen sich unter Linux mit dem Kommandozeilenprogramm OCRmyPDF in durchsuchbare PDF-Dokumente umwandeln. Dabei platziert das Tool die Textebene recht präzise im Dokument, sodass sich Textabschnitte auch gut per Copy & Paste weiterverwenden lassen.
Die eigentliche Arbeit machen dabei bewährte Linux-Konsolentools wie Imagemagick, Pdftk und Ghostscript. Die Texterkennung erledigt die OCR-Engine Tesseract, die PDF/A-Validierung übernimmt Jhove. Ein gut kommentiertes Shell-Skript ruft die Funktionen der Tools bei Bedarf ab, ein Python-Skript platziert anschließend den erkannten Text im PDF-Dokument.
Einrichten
OCRmyPDF steht bei Github zum Download bereit. Das heruntergeladene Archiv muss dann nur noch entpackt werden und das Shellskript mit dem Befehl chmod +x OCRmyPDF.sh ausführbar gemacht werden.
OCRmyPDF setzt ein paar Pakete voraus, darunter Parallel, Poppler-Utils, Imagemagick, Unpaper, Tesseract, Python 2, Ghostscript und Java, die sich allesamt über die Paketverwaltung installieren lassen. Genaueres verraten die im Paket mitgelieferten Release Notes. Fehlt eines davon, weist das Tool beim Aufruf darauf hin. Einen Überblick über die verfügbaren Optionen liefert der Befehl
./OCRmyPDF.sh -h
Loslegen
Der Parameter -l setzt die Erkennungssprache für Tesseract fest. Um dann zum Beispiel die Datei input.pdf im aktuellen Verzeichnis mit einer zusätzlichen Textebene zu versehen, dient der Befehl
./OCRmyPDF.sh -l deu input.pdf output.pdf
Das Ergebnis landet im aktuellen Verzeichnis in der Datei output.pdf, die OCRmyPDF in dem für die Langzeitarchivierung vorgesehenen PDF/A-Format speichert. Ist ein Scan schief und krumm, kann OCRmyPDF auf das Tool unpaper zurückgreifen, um das Dokument zu entzerren. Dazu ergänzen Sie den Aufruf um den Parameter -d.
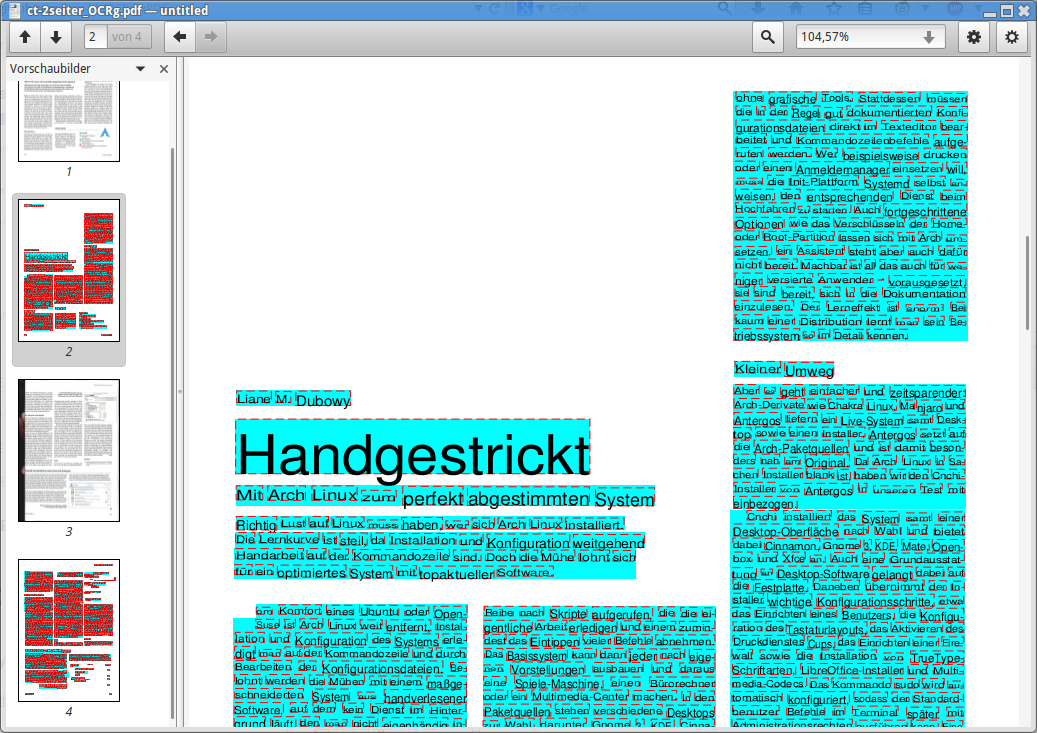
Zum Troubleshooting lässt sich die Textebene auch sichtbar machen. Dazu ergänzt man den Befehl um die Option -g und schaltet so in den Debug-Modus. OCRmyPDF gibt dann jede Seite zusätzlich einmal nur mit Text samt Platzierungsboxen aus.
Weder Buch- noch c't-Seiten mit drei oder vier Spalten machten OCRmyPDF im Test Probleme. Das Ergebnis der Texterkennung ist wie von Tesseract gewohnt recht akkurat. Bemerkenswert ist vor allem die gelungene Platzierung des OCR-Ergebnisses unter dem Originaltext im Bild, das OCRmyPDF in der Original-Auflösung aus dem Scan übernimmt. (lmd) (lmd)
