

ARM-Revolution im Rechenzentrum: Wie es ARM-Prozessoren in Server schafften
Die ARM-Architektur eroberte schnell den Embedded- und Mobilphone-Markt. Nun soll die ARMv9-Architektur auch auf dem Servermarkt Erfolg erzielen.

- Andreas Stiller
Embedded Systeme und Mobilgeräte sind schon lange eine Domäne der energiesparenden ARM-Prozessoren. Doch inzwischen entwickeln sie sich auch zu einer Konkurrenz für Intel- und AMD-CPUs in Notebooks, Desktop-Systemen und erobern sogar den Server-Markt. In unserem Schwerpunkt "Die ARM-Revolution" untersuchen wir, wie es dazu gekommen ist.
Eigentlich haben Sophie Wilson und Steve Furber von der britischen Heimcomputerfirma Acorn den ARM-Prozessor nur entwickelt, weil Intel zu stur war. Die US-Firma wollte den Briten partout keine Architekturlizenz geben, sondern nur fertige 80186/88-Chips, und so machten sich die Acorn-Entwickler eben selbst dran und schufen eine eigene energieeffiziente Architektur auf RISC-Basis, die ein für Echtzeitverarbeitung und Interaktivität optimiertes Interrupt-Konzept bot.

Mithilfe von Apple lagerten sie ein paar Jahre später die Prozessorentwicklung in eine eigene Firma ARM Ltd. aus und legten damit den bis heute vielleicht wichtigsten Grundstein für den Erfolg. Denn dieser besteht weniger in der Architektur als vielmehr im Vermarktungskonzept: Statt fertiger Chips verkauft man unterschiedlich gestaffelte Lizenzen für zahlreiche Prozessorarchitekturen und Peripheriechips, sodass sich die Lizenznehmer ihre Chips maßschneidern und um eigene Features erweitern können. Kunden können sogar eine Architekturlizenz erwerben, mit der sie die Prozessor- und Befehlssatzarchitektur nach Belieben verändern dürfen.
ARMv7: vom Mobilchip in den Server
Videos by heise
ARM selbst trat dabei nie direkt als Chiphersteller auf, es sei denn über Beteiligungen. So etwa bei der Firma Calxeda, die 2008 gegründet wurde. Calxeda sollte den Weg in die Welt der (Mikro-)Server mit umgewidmeten Mobilchips namens EnergyCore ebnen. HPE stand als großer Kunde bereit, wollte mit verschiedenen Prozessorarchitekturen in seinem Moonshot-Projekt ausloten, wie man dicht gepackte Server mit vielen kleinen, energieeffizienten Minikernen vermarkten kann.
Calxeda wollte mit recht einfachen 32-bittigen ARM-Prozessoren – vierkernigen Cortex-A9-CPUs – auf dem Servermarkt mitspielen, Prozessoren, die auf der betagten ARMv7-Befehlssatzarchitektur beruhten. Mit dieser Architektur hatte sich ARM Jahre zuvor im Mobilsektor bravourös geschlagen.

Inzwischen ist ARM bei einem der bedeutendsten Chipentwickler, Nvidia, gelandet. Das ARM-Konzept soll auch hier erhalten bleiben, mit einem großen Heer von über 160 Lizenznehmern – darunter solche Riesen wie Apple, Samsung, Microsoft, Amazon, Alibaba. Auch Intel war und ist Lizenznehmer und hatte eine Zeit lang den von DEC übernommenen StrongARM-Prozessor im Angebot.
Dank des Bausteinprinzips von ARM, erweitert durch vielfältige Designs der Lizenznehmer, gibt es zu jeder Befehlssatzgeneration (Instruction Set Architecture, ISA) eine Vielzahl von Hardwareimplementierungen. Viele Lizenznehmer übernehmen fix und fertig designte Implementierungen von ARM, andere übernehmen nur die Kerne und ergänzen den Rest mit eigener Hardware, noch andere variieren auch die Kerne oder designen komplett eigene, die zur jeweiligen ISA kompatibel sind.
Die erfolgreiche Cortex-Familie auf Basis der ARMv7-Architektur wurde je nach Aufgabengebiet in drei Profile aufgeteilt: ARMv7-M ist für Mikrocontroller gedacht, ARMv7-R für Realtime-Systeme und ARMv7-A wie Application für größere Systeme, also auch für Server. Unter anderem wurde für die wesentlich komplexere A-Profil-Linie ein Sicherheitskonzept namens TrustZone eingeführt. Bekannt sind etwa neben diversen ARM-Cortex-Prozessoren Qualcomms Krait oder Apples Swift (A6), die auf ARMv7-A basieren.
| ARM-Historie | |||
| Befehlssatzarchitektur | Jahr | Prozessorfamilien | Prozessoren |
| ARMv1 | 1985 | ARM1 | |
| ARMv2 | 1986 | ARM2, ARM3 | |
| ARMv3 | 1991 | ARM6, ARM7 | |
| ARMv4 | 1995 | ARM7T, ARM8, StrongARM, ARM9T | DEC StrongARM |
| ARMv5 | 2002 | ARM7EJ, ARM9E, ARM10E | Intel Xscale |
| ARMv6 | 2002 | ARM11; Cortex-M0, M0+, M1 | BCM2835 (Raspberry Pi 1) |
| ARMv7 | 2004 | Cortex-A5, A7, A8, A9, A12, A15, A17, M3, M4, M7, R4, R5, R7, R8 | Qualcomm Krait und Snapdragon, Apple A; Calxeda EnergyCore |
| ARMv8 | 2012 | Cortex-A32, A35, A53, A55, A57, A72, A73, A75, A76, A77, A78, X1, M23, M33, R52; Neoverse E1, N1, V1 | Qualcomm Snapdragon, Apple A und M1, Samsung Exynos; Applied Micro X-Gene, Cavium/Marvell ThunderX und ThunderX2, Fujitsu A64FX, Broadcom Stingray, HiSilicon Hi 1620, Phytium Mars, Ampere Altra und Altra Max, Amazon Graviton und Graviton2 |
| ARMv9 | 2021 | Cortex-A510, A710, X2; Neoverse N2 | Marvell Octeon 10, Nvidia Grace, Alibaba Yitian 710 |


ARMv8: Einführung von 64 Bit
Im Oktober 2011 stellte ARM die neue Befehlssatzarchitektur ARMv8 vor, die die Aufteilung in die drei Profillinien A, R und M fortführte und die in den ARM-Prozessoren aktueller Smartphones und Embedded Devices zu Einsatz kommt.
ARMv8 bot eine Erweiterung auf 64 Bit, war aber auch weiterhin für reine 32-Bit-Prozessoren definiert. So blieb das Profil ARMv8-M grundsätzlich 32-bittig, R und A gibt es für beides. Landläufig versteht man allerdings unter ARMv8 immer die 64/32-Bit-Architektur, die eigentlich korrekter als AArch64/32 bezeichnet werden sollte.
64 Bit ist aber keinesfalls einfach nur eine Erweiterung, eher andersherum: Mit der 64-bittigen ARMv8-Architektur schuf ARM einen völlig neuen Prozessor, der noch alten 32-Bit-Code effizient ausführen kann. Allerdings will ARM spätestens ab 2023 auf diese dann schon recht obsolete Legacy-Unterstützung verzichten. Den ersten rein 64-bittigen ARM-Chip gibt es aber jetzt schon, den Cortex-A510 auf Basis von ARMv9.0.

(Bild: Cavium)
Nützlich für den Übergang war, dass die 64-Bit-Befehle weiterhin 32 Bit lang und ähnlich wie ihre 32-Bit-Pendants codiert sind. Im 64-Bit-Modus war dann aber doch vieles anders. So fiel ein zentrales Feature der klassischen ARM-Architektur weg, nahezu alle Befehle konditioniert ausführen zu können. Das gilt jetzt weitgehend nur noch für Sprungbefehle.
Auch das Interrupt-Konzept wurde völlig neu gestaltet. An Erweiterungen sind Thumb-2, NEON, VFPv4-D16 und VFPv4 obligatorisch, optional kamen Kryptoeinheiten für AES und SHA hinzu. Insbesondere zog mit ARMv8.2-A im Januar 2016 die neue, von Fujitsu entwickelte Scalable Vector Extension (SVE) als Option ein. Das sind immerhin insgesamt 522 neue Befehle.
Man darf bei SVE allerdings nicht automatisch an Fujitsus Implementierung im A64FX-Prozessor mit seinen zwei 512-Bit-Vektoreinheiten denken. Denn wie der Name Scalable andeutet, ist die tatsächliche Vektorlänge in Hardware flexibel zwischen 128 und 2048 Bit. De facto gibt es derzeit außer beim A64FX keine andere ARM-Implementierung, die mehr als 128 Bit für SVE oder das später eingeführte SVE2 bietet.
ARMv8.4-A führte im November 2017 unter anderem weitere Kryptoerweiterungen ein, ARMv8.5-A definierte im September 2018 die MTE (Memory Tagging Extension) für gesicherten Speicher. Fürs High-Performance-Computing und für KI brachte ARMv8.6-A im September 2019 zahlreiche Goodies wie General Matrix Multiply und den Datentyp Bfloat16.
ARMv9: der nächste große Wurf
Im März 2021 gelang ARM dann wieder ein großer Wurf mit der neuen Befehlssatzgeneration ARMv9-A. Hier wurden wichtige neue Fähigkeiten festgelegt, viele davon sind allerdings zumindest für ARMv9.0-A optional. SVE2 hingegen ist obligatorisch. Es umfasst eine Erweiterung der alten ARM-SIMD-Einheit NEON im Zusammenspiel mit SVE. Optional sind die Scalable Matrix Extension SME, Transactional Memory und ein erheblich erweitertes Sicherheitskonzept namens Confidential Compute Architecture (CCA).

(Bild: ARM)
SME bietet Optimierungen für Matrixmultiplikation und -transposition und führt einen neuen Streaming-Modus ein. Transactional Memory wird derzeit von Intel Xeon und Power 9 angeboten. Es kann etwa bei Datenbankservern erhebliche Performancevorteile bieten – um so stärker, je mehr Prozessoren in einem SMP-System zusammengeschaltet sind. CCA umfasst mit der "Realm" Memory Extension RME eine Erweiterung von TrustZone sowie einen Security Monitor. Damit sollen auch Drittanbieter eigene gesicherte Zonen einrichten können, bei TrustZone ist das auf den Hersteller beschränkt. Und der Security Monitor soll einen geschützten Parallelbetrieb von gesicherten und ungesicherten Applikationen auf der gleichen Anlage garantieren – das ist ein Feature, an dem die amerikanischen National Laboratories hochgradig interessiert sind, etwa das Los Alamos National Laboratory.
Neoverse: bereit für die großen Eisen
Mit den ARMv9-Features kann sich ARM in der Oberklasse der Server mehr als sehen lassen, insbesondere dann, wenn die optionalen Features auch eingebaut sind. Zunächst brachte ARM kleine ARMv9-Chips für den Mobile- und Desktopbereich heraus: Den bereits erwähnten rein 64-bittigen Cortex-A510, den Cortex-A710 und den Cortex-X2.
Für Server hatte ARM auf der Hotchips-Konferenz 2018 die ersten Neoverse-Plattformen auf ARMv8-Basis für "Cloud to Edge" vorgestellt, die drei große Baukastenlinien umfassen:
- Serie V: High Performance und KI;
- Serie N: Energie/Performance balanciert für Scale-out-Anwendungen;
- Serie E: Energieeffizienz.
Als erste Plattform für Hyperscale wurde N1 Ares auf Basis von ARMv8.2+-A (das Plus steht für einige Erweiterungen von ARMv8.3-8.5-A) mit 64 Kernen vorgestellt, dessen Architektur zum Teil auf dem Cortex-A76 beruht, aber andere Caches und ein anderes Mesh-Interconnect aufweist. Wie der A76 ist er für den 7-nm-Prozess konzipiert. Das Design ist auf bis zu 128 Kerne ausgelegt. Mit 105 Watt/SoC und etwa 190 SPECint2017-Rate bietet er etwa 30 Prozent bessere Performance/Watt als beispielsweise ein älterer Cortex-A72. Für kleine Edge-Systeme gibt es 8-Kerner mit 25 Watt/SoC und 20 SPECint2017-Rate.
Die erste E1-Plattform, Helios, baut ebenfalls auf einem vorhandenen Cortex-Prozessor auf – hier auf dem Cortex-A65AE. Auch Helios arbeitet mit ARMv8.2+-A, anders als Aries aber mit SMT.
ARMs Neoverse-N2-Kerne (Perseus) kommen derweil in Gestalt des Marvell Octeon 10 als erster ARMv9-Serverchip überhaupt auf den Markt, zumindest als Muster, gefertigt in TSMCs 5-nm-Prozess. Marvells Octeon 10 hat bis zu 36 Kerne pro Chip und unterstützt DDR5-Speicher und PCIe Gen 5. ARMs N2-Kerne bieten SVE2 in der kleinsten Ausführung mit zweimal 128 Bit, die mächtigen Features Transactional Memory und CCA sind allerdings unter ARMv9.0-A noch nicht an Bord. Zu betonen ist hier der große Performancesprung gegenüber Neoverse N1 insbesondere bei der Zahl der Instruktionen pro Takt, die um 40 Prozent größer sein soll.
Der performanceoptimierte Neoverse-V1-Kern mit dem Codenamen Zeus basiert wie der N1 noch auf ARMv8.2+, ist hardwaremäßig aber deutlich erweitert, mit verdoppelter Skalarität – bis zu acht Befehle vom Decoder – und mit einer Verdoppelung der Zahl der Vektoreinheiten. Gebündelt bieten diese dann zweimal SVE mit je 256 Bit. Das entspricht an Vektorleistung den AVX2-Einheiten im AMD Epyc oder einer AVX512-Einheit aktueller Intel Xeons.
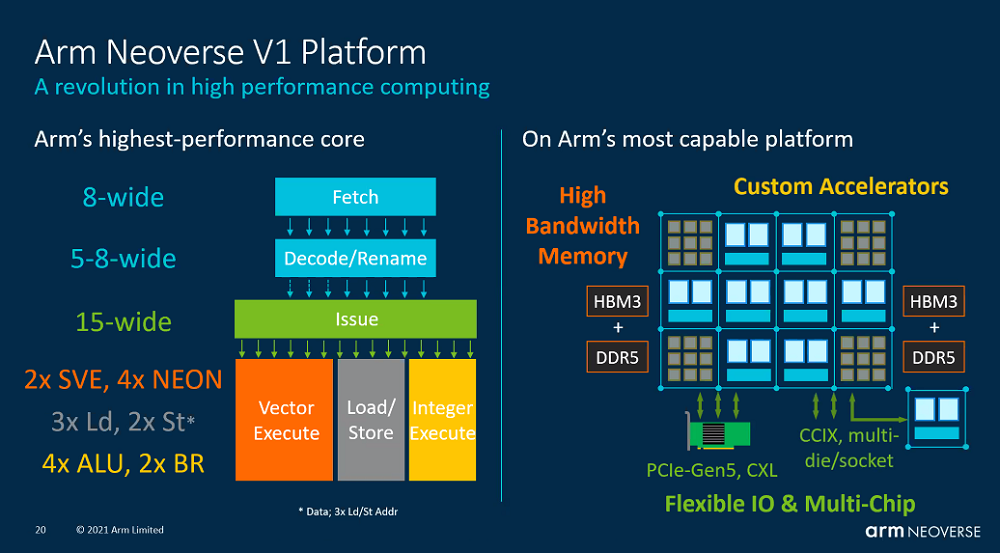
(Bild: ARM)

(Bild: ARM)
Die Serverprozessoren kommen
Unmittelbar nach der Vorstellung der 64-bittigen ARMv8-Architektur im Oktober 2011 machten sich fast ein Dutzend Firmen auf, ARM-Chips für den Servermarkt zu designen: Samsung, Broadcom, Qualcomm, Cavium, Caldexa, Applied Micro, AMD, Marwell. Davon haben die meisten ihre Pläne begraben oder ihr Design verkauft, oder sie gingen wie Caldexa in Konkurs. AMD etwa gab mit Start der Epyc-Familie seine ARM-Ambitionen und seine SeaMicro-Mikroserverlinie auf – jedenfalls vorerst. Andeutungen von AMDs CFO Devinder Kumar auf einem Technikforum der Deutschen Bank im September 2021 zeigen jedoch, dass man ARM weiterhin im Blick hat.
Samsung hat derweil sein Design aus der Serversphäre verabschiedet und für andere Märkte umgewidmet. Broadcom wurde von der HP-Großtochter Adago aufgekauft, der Vulcan-Prozessor – der auch nur zusammen mit der Firma NetLogic eingekauft war – ging als ThunderX2 an Cavium, die ihren eigenen ThunderX beerdigten. Cavium wiederum wurde im Juli 2018 von der israelischen Firma Marvell übernommen, die die ThunderX-Linie zunächst weiterführte. Auf der Hotchips-Konferenz im August 2020 präsentierte man noch den ThunderX 3 auf Basis von ARMv8.3, um ihn und damit die ganze ThunderX-Linie kurz danach einzustampfen – und ganz auf die neuen Neoverse-Kerne zu setzen. Schon im Juni 2021 stellte man den Octeon 10 vor: den ersten, der auf ARM Neoverse N2 mit ARMv9-Architektur beruht.
Applied Micro wurde im November 2016 von der Firma Macom übernommen und das ARMv8-Design X-Gene 3 an den Investment-Riesen Carlyle Group verhökert, der es einem frisch gegründeten Start-up namens Ampere Computing übergab. Diese neue ARM-Entwicklungsfirma wurde ausgerechnet von der ehemaligen Software-Chefin von Intel, Renee James, gegründet, die zwar wenig Hardware-, aber viel Managementerfahrung aufweist und die vielleicht noch ein Hühnchen mit Intel zu rupfen hatte. Für die Hardware nahm sie zwei erfahrene Top-Leute von Intel mit: Atiq Bajwa als CTO und Rohit Vidwans als Chief Engineering & Manufacturing Officer. In kürzester Zeit schaffte es Ampere, wichtige Partner wie Lenovo, Oracle und Cloudflare zu gewinnen.
Wie Marvell führte auch Ampere die übernommene X-Gene-Linie nicht fort, sondern wechselte zu ARM Neoverse, jedenfalls zunächst einmal. Fertiggestellt ist derweil der Ampere Altra mit 80 Kernen auf Basis von ARM Neoverse N1 (ARMv8) mit einigen Modifikationen. Seit Kurzem gesellt sich der Altra Max mit 128 Kernen hinzu. Ein weiterer neuer Player ist das von ehemaligen Apple-Entwicklern gegründete Start-up Nuvia, das Anfang des Jahres 2021 von Qualcomm aufgekauft wurde. Was Nuvia in petto hat, weiß man nicht so genau, vermutlich einen Konkurrenzchip zu Apples M1, aber vielleicht wird sich auch Qualcomm wieder auf den Servermarkt wagen.
In China kamen Firmen wie die Huawei-Tochter HiSilicon mit ihrer Neoverse-N1-CPU Hi 1620 und Phytium hinzu. Phytium hatte im Jahr 2016 auf der Hotchips-Konferenz den ARMv8-Prozessor Mars vorgestellt.
Das Geschäft mit der Cloud
Auch die großen Cloud-Provider rührten sich. Zuerst kam Amazon mit dem Graviton aus der Reserve, nun ist man schon beim Graviton2 auf Basis von ARMs Neoverse N1. Mittlerweile bietet Amazon fünf verschiedene Instanzenfamilien dafür an – und hat jetzt den Graviton3 vorgestellt. Im November 2021 war noch nicht klar, ob der Prozessor auf Neoverse N2 (ARMv9) oder V1 (ARMv8) basiert.
Cloudflare hat die ersten Altras von Ampere im Einsatz und berichtete im Juni 2021 begeistert von 57 Prozent mehr Performance per Watt. Auch die Oracle Cloud Infrastructure (OCI) setzt Ampere Altra ein. Auf der SC21 stellte Oracle seine positiven Erfahrungen mit HPC-Anwendungen in der Cloud vor. In der für Kunden wichtigen Metrik Performance per Dollar schlugen sich die Systeme laut Oracle sehr gut: nahezu so schnell wie ein AMD Epyc Milan, aber mit 7 PFlops/Dollar um 34 Prozent günstiger.
Auch in China wird zunehmend auf ARM in der Cloud gesetzt. Im Oktober 2021 hat die Handels- und Kommunikationsplattform Alibaba ihren 128-Kern-ARM Yitian 710 vorgestellt. Ob Alibaba dabei auf Neoverse-Kerne setzt oder auf eigene, ist derzeit unklar. Laut Alibaba soll er im SPEC2017-Benchmark so schnell sein wie zwei aktuelle Intel Xeons mit je 32 Kernen. In der Cloud von Google-Konkurrent Baidu kann man zwar noch keine Neoverse-, aber Instanzen mit Broadcoms Cortex-A72-CPU Stingray wählen.
Auch der größte chinesische Internetkonzern, Tencent, hat nicht weiter beschriebene ARM-Neoverse-Prozessoren im Einsatz und lässt verlauten: "ARM delivers 28 % better performance than traditional architectures and 100 % better power performance."
Und schließlich gibt es ja noch Microsoft und Google. Von Microsoft erwartet man eigene ARM-Prozessoren für die Azure-Cloud. Bislang weiß man allerdings nur, dass Microsoft eine Architekturlizenz für 32 Bit hat – aber nicht alle Lizenznehmer werden veröffentlicht. Intern stehen für die Produktion jedenfalls Instanzen mit Marvell ThunderX2 zur Verfügung. Inwieweit Google für seine riesigen Serverfarmen ARM-Kerne einsetzt, darüber kann man nur spekulieren. In der Google Cloud kann man derzeit lediglich Intel- und AMD-Instanzen wählen. Im Frühjahr 2021 hat Google Uri Frank, Intels Director of Product Development, abgeworben, der in Israel ein Center für eine eigene SoC-Entwicklung aufbauen soll. Hier wird als mögliche Grundlage ARM vermutet – aber Google-Mutter Alphabet ist auch Mitglied bei der RISC-V-Foundation und bei OpenPower.
Die schnellsten Rechner der Welt
Mit dem von Fujitsu gebauten Fugaku steht ein System mit dem ARM-Prozessor A64FX seit Mitte des Jahres 2019 an der Spitze der TOP500-Liste der Supercomputer. Hinzu kommen noch ein paar kleinere A64FX-Systeme in Japan sowie auf Platz 393 der ThunderX2-Rechner Astra von HPE am Sandia National Lab. In Europa gibt es ein paar kleinere Installationen mit ThunderX2, etwa Fulham und Isambard in Großbritannien. Aber inoffiziell weiß man, dass China inzwischen weit schnellere Systeme besitzt, diese nur noch nicht gemeldet hat. Spitzenreiter dürfte mit 1,3 Exaflops der Tianhe-3 in Guangzhou sein, der von Phytium-ARM-Prozessoren angetrieben wird, zusammen mit speziellen Beschleunigern Matrix-2000+.
Mit ARM Neoverse V1 (Zeus) wollen im Jahr 2022 zwei bedeutende Teilnehmer im oberen HPC-Segment mitspielen: Rhea von SiPearl und ETRI K-AB21. Rhea ist der Prozessor der Europäischen Prozessor-Initiative (EPI), an der 17 EU-Staaten teilnehmen, die rund eine Milliarde Euro in das Gesamtprojekt EuroHPC stecken. So wie es ausschaut, soll Rhea 72 Neoverse-V1-Kerne haben und eine Schnittstelle zu Intels geplanter Xeon-GPU Ponte Vecchio. ETRI ist das südkoreanische Energy Technology Research Institute, dessen Neoverse-V1-CPU 16 TFlops abliefern soll.
Am Horizont der Neoverse-Linien taucht jedoch bereits Poseidon auf, der – anders als in der griechischen Mythologie – deutlich mächtiger als sein Bruder Zeus sein soll. Mit diesem Design will ARM-Neubesitzer Nvidia Anfang 2023 ganz groß in das CPU-Geschäft im High-Performance-Computing einsteigen: 10-fach höhere Performance und 30-fach höhere aggregierte Speicherbandbreite als aktuelle Serversysteme, das hat Nvidias Chef Jensen Huang auf der Entwicklerkonferenz im Frühjahr 2021 für Grace verkündet. Grace dürfte wohl all die beschriebenen ARMv9-Optionen wie SME, Transactional Memory und CCA anbieten. Mit welcher Vektorbreite SVE aufgebaut sein wird, weiß man noch nicht.

(Bild: Nvidia)
Bestellungen liegen bereits vor. Das Schweizer nationale Supercomputer-Zentrum SCSC, das viele Jahre lang Europas schnellsten Rechner Piz Daint betrieb, will mit Grace und der nächsten Nvidia-GPU-Generation mit dem kommenden Alps in den Exascale-Bereich. Dank NVLINK-5-Verbindungen soll Grace besonders schnell mit den hauseigenen GPUs kommunizieren können. Daneben hat auch das Los Alamos National Lab bereits einen etwas kleineren Rechner mit Grace und Nvidia-GPUs geplant. Auf der SC21 verriet Steven Poole vom Los Alamos National Lab, dass der Rechner den Namen Vendito tragen und über 100 PFlops Spitzenleistung liefern soll.
Epilog
Die Roadmap für den Serverbereich bis zum Jahr 2023 sieht für ARM sehr erfolgversprechend aus. Aber man muss da vorsichtig sein: Vorteile in Performance pro Dollar können schnell schwinden, einfach wenn die Konkurrenz die Preise drastisch senkt. Intel ist wegen großer Schwierigkeiten mit dem 10-nm-Prozess etwas ins Hintertreffen geraten, beim 7-nm-Prozess ist man etwa sechs Monate in Verzug.
Im Softwarebereich hat x86 noch deutliche Vorteile, sowohl an Vielfalt als auch an Reife und Stabilität. Auf der SC21 berichtete die ARM HPC User Group noch von diversen Nickligkeiten, etwa mit MPI, Lustre oder Mellanox-Treibern. "Alle MPI-Blibliotheken haben Issues", sagt Eva Siegmann von der Stony Brook University. Die Tool Chains sind noch nicht ausgereift beziehungsweise nicht auf dem neuesten Stand. Die GCC kennt zwar SVE, bietet aber noch nicht die nötigen hochoptimierten Vektorbibliotheken. Aber das sind relativ schnell lösbare Probleme, wenn erst einmal genügend Leute Zugriff auf ARM-Server haben.
Andreas Stiller war bis zum wohlverdienten Ruhestand 2017 dienstältester Heise-Redakteur. Er beschäftigt sich mit Prozessoren, High-Performance-Computing und hardwarenaher Programmierung. (odi)
