

Brauchen asynchrone Microservices und Self-Contained Systems ein Service-Mesh?
Seite 3: Service-Mesh – das Rundum-Sorglos-Paket für Microservices
Ein Service-Mesh hebt viele Funktionen zu Observability, Routing, Resilienz und Sicherheit in die Infrastruktur. Es macht sich die verteilte Microservices-Architektur zunutze, statt sie mit zentralen Komponenten wie einem API Gateway unter Kontrolle zu bringen. Es stellt jeder Serviceinstanz einen Service-Proxy zur Seite, über den alle ein- und ausgehenden Netzwerkverbindungen der Instanz laufen. Der Service-Proxy wendet auf die Netzwerkanfragen Observability-, Routing-, Resilienz- und Sicherheitsfunktionen an (Abb. 3).
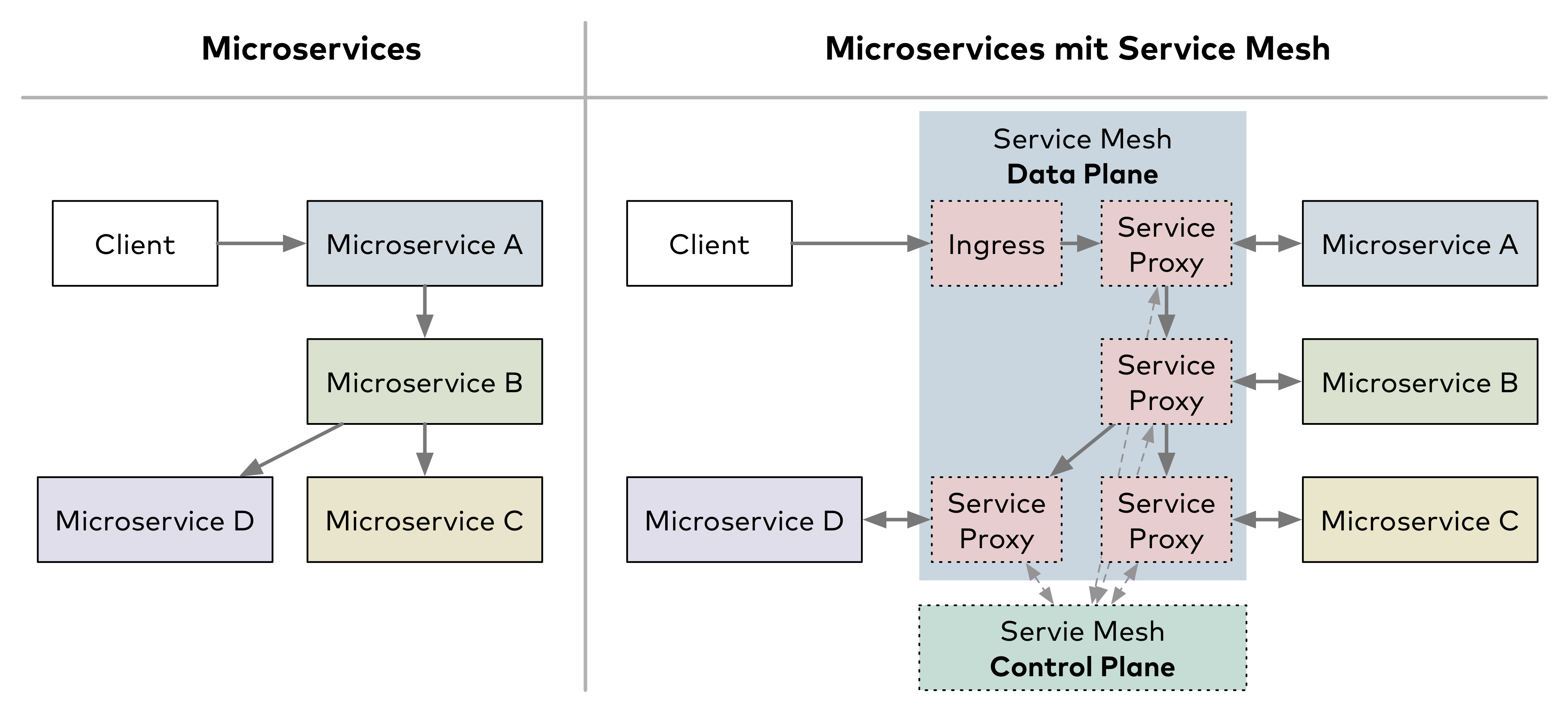
Das Sidecar-Pattern gab es bereits vor Service-Meshes. Neu ist eine weitere Ebene, die sogenannte Control Plane. Sie kennt alle Service-Proxys und konfiguriert deren Verhalten. Die Service-Proxys führen ihre Funktion als Teil eines dezentralen Netzes aus, sind aber zentral konfigurierbar. Sie erfassen außerdem Daten zum Netzverkehr, der sie passiert, und senden ihn an die Control Plane. Die Daten ermöglichen ein flächendeckendes Basis-Monitoring. Mit einem Service-Mesh wird also einerseits ein konsistentes Verhalten der Services unabhängig von ihrer Implementierung ermöglicht und andererseits die Komplexität der einzelnen Microservices reduziert.
Service-Meshes haben einen regelrechten Hype ausgelöst, weil sie gleich eine ganze Reihe komplexer Probleme von Microservices-Architekturen lösen, ohne dass Entwickler bestehenden Code ändern müssen. Nun sind viele Entwicklungsteams damit beschäftigt zu evaluieren, wie ein Service-Mesh in ihre individuelle Umgebung passt. Bei einer klassischen Microservices-Architektur ist die Antwort (in aller Regel "Ja!") schnell gefunden. Aber können asynchron kommunizierende Microservices oder Self-contained Systems von Service-Meshes profitieren?
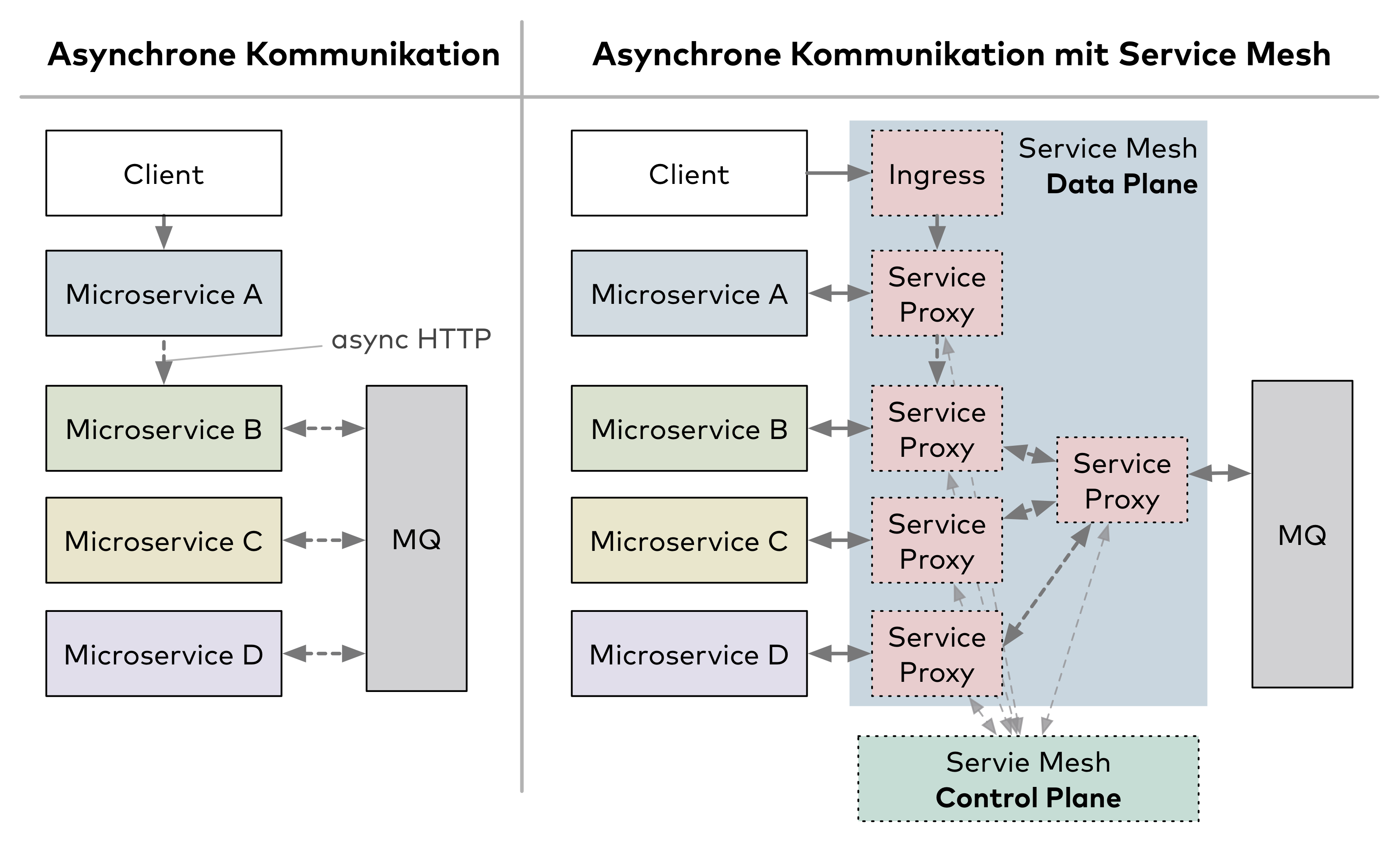
Während die aktuellen Service-Mesh-Implementierungen asynchrones HTTP ohne weiteres unterstützen, wird an der Kompatibilität zu Message Queues, die häufig eigene Protokolle nutzen, aktuell noch gearbeitet.
Tiefe Einblicke in Echtzeit: Observability
Zwischen asynchron kommunizierenden Microservices gibt es keine verschachtelten Aufrufe, die man mit Tracing sichtbar machen müsste. Antwortzeiten und Fehlerraten sind aber trotzdem wertvolle Daten, die Einblick in den Zustand einer Anwendung und Anhaltspunkte für Fehler liefern können. Bei beiden Formen der asynchronen Kommunikation kann ein Service-Mesh zu einem flächendeckenden Basis-Monitoring führen. Die von den Service-Proxys aufgezeichneten Metadaten zu Netzwerkverbindungen wie Quelle und Ziel einer Anfrage, URL, http-Methode, Statuscode und Antwortzeit können Tools wie Prometheus auswerten oder zu einem Dashboard mit Graphen zum Live-Netzwerkverkehr aufbereiten.
Der Netzwerkverkehr zwischen den Microservices und einer Message Queue läuft ebenfalls über einen Service-Proxy – damit ist ein Überwachen möglich. Um Fehler bei der Kommunikation zu erkennen, muss das Service-Mesh allerdings das Protokoll der Message Queue unterstützen. Da ein Service-Mesh aber keinen Einblick in den Inhalt der Anfragen und in die Interna der Anwendung hat, ist zusätzliches fachliches Monitoring weiterhin nötig.
Netzwerkverkehr intelligent steuern: Routing
Ein Service-Mesh kann Routing-Regeln umsetzen, mit denen Entwickler neue Versionen, zum Beispiel durch Canary Releasing, gezielt ausrollen oder zwei Versionen miteinander vergleichen können (A/B-Tests). Wenn asynchrone Kommunikation über eine Message Queue stattfindet, kann ein Service-Mesh Canary Releasing allerdings nicht allein umsetzen, da Metadaten der HTTP-Anfragen nicht ohne weiteres im Event landen. Realisiert man asynchrone Kommunikation durch HTTP-Aufrufe, kannn man wie bei synchroner Kommunikation Routing-Regeln für Canary Releasing und A/B-Tests nutzen.
Immun gegen Ausfälle und Fehler: Resilienz
Resilient ist ein Microservice, wenn er widerstandsfähig gegenüber Fehlern anderer Services oder des Netzwerks ist. Die Umsetzung erfolgt mit den Circuit-Breaker, die fehlerhafte Komponenten zeitweise vom Netzwerkverkehr abschirmen. Kurzzeitige Netzwerkfehler beheben Retry- und Timeout-Mechanismen. Auf den ersten Blick erscheint asynchrone Kommunikation solchen Fehlern vorzubeugen, weil sie blockierende Aufrufe zwischen Microservices vermeidet.
Wie Abbildung 4 allerdings zeigt, muss man den auf dem Server eingehenden Netzwerkverkehr über einen sogenannten Ingress an eine Microservice-Instanz routen (z. B. von Client zu Microservice A). Bei solchen Verbindungen können Resilienz-Maßnahmen durchaus sinnvoll sein.
Vertrauen automatisieren: Security
Angreifer können das gegenseitige Vertrauen von Services innerhalb eines Clusters nutzen, um einen Service zu imitieren und das System unbemerkt zu manipulieren, lahmzulegen oder auszuspionieren. Ein Service-Mesh kann ohne Codeänderungen dafür sorgen, dass alle Serviceinstanzen beidseitig TLS-authentifiziert und verschlüsselt kommunizieren (sogenanntes Mutual TLS/mTLS). Da er kein Zertifikat vorweisen kann, fehlt dem Angreifer damit der Einstiegspunkt ins System. Die für mTLS nötige Certificate Authority und die Mechanismen zum Verteilen der Schlüssel sind Teil eines Service-Mesh.
mTLS funktioniert sowohl für synchrone als auch für asynchrone HTTP-Kommunikation. Setzen Entwickler Message Queues ein, liegt die Vermutung nahe, dass die Services einander ohnehin nicht aufrufen und damit solche Sicherheitsmaßnahmen nicht benötigen. Allerdings können sich Angreifer, die Zugang zum Server haben, als Microservice-Instanz ausgeben und schadhafte Events in die Message Queue schreiben oder unautorisiert Events auslesen. Sofern die spezielle Message Queue unterstützt wird, profitiert die Anwendung vom automatischen mTLS.
