Dynamische Office-Dokumente in SharePoint erzeugen
Office-Dokumente speichern kann in SharePoint jeder. Eine Herausforderung ist es jedoch, sie anzulegen, dynamisch mit Daten zu füllen und dann bereitzustellen. Mit XML geht das relativ einfach. So lassen sich Word-Dokumente direkt aus SharePoint heraus erzeugen und mit Daten füllen.


Office-Dokumente speichern kann in SharePoint jeder. Eine Herausforderung ist es jedoch, sie anzulegen, dynamisch mit Daten zu füllen und dann bereitzustellen. Mit XML geht das relativ einfach. So lassen sich Word-Dokumente direkt aus SharePoint heraus erzeugen und mit Daten füllen.
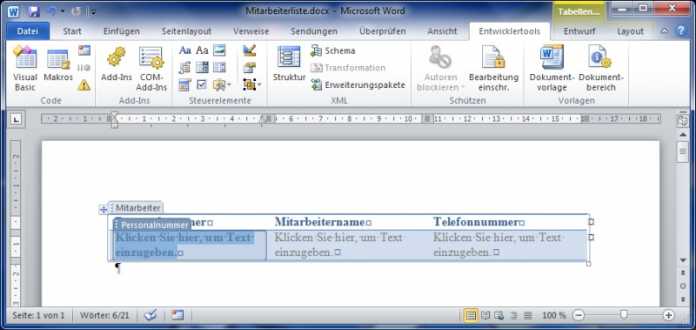
Im Büroalltag spielen Office-Dokumente eine gewichtige Rolle: Texte lassen sich schnell erstellen und Tabellen einfach anlegen. Sie jedoch nach eigenen Wünschen zu gestalten und dynamisch mit Daten zu füllen ist deutlich schwieriger, da die API recht komplex ist. Einen einfacheren Ansatz bieten die auf Office Open XML [1] beruhenden Formate DOCX, XSLX oder PPTX. Das zeigt sich bei einem Blick auf die grobe Struktur, beispielsweise einer Tabelle (Abb. 1).
Tipps & Tricks der SharePoint-Entwicklung
In dieser Artikelreihe der SharePoint-Experten von Computacenter bisher erschienen:
- Datenquellen im Griff mit SharePoints DataFormWebPart [2]
- Geschäftsdaten mit SharePoint und .NET aufbereiten [3]
- Mobile Webapps für SharePoint [4]
- SharePoint 2010 Ribbons anpassen [5]
- Dynamische Office-Dokumente in SharePoint erzeugen
Office Open XML basiert auf dem Packaging-Standard [6]. Das eigentliche Dokument ist hier in XML im Zip-Format zusammengefasst, darin enthalten auch sämtliche Ressourcen wie Bilder und andere Dokumententeile. Um zum Beispiel ein DOCX-Dokument direkt aus SharePoint zu erzeugen, muss man zuerst das document.xml im Verzeichnis /Word öffnen. Abbildung 1 zeigt einen Ausschnitt davon, hier die erste Zelle einer Tabelle mit einem Platzhalter. Hier werden später die Daten eingefügt (über Feldinformationen und auf direktem Weg ins XML). So muss sich der Entwickler nicht mit der API und deren komplexen Aufrufen auseinandersetzen. Es genügt, das Paket zu öffnen, das XML einzulesen, die Tabellenzeile mit den Feldern zu wiederholen und alles wieder zu verpacken.
Den Packvorgang unterstützt der Namensraum System.IO.Packaging. Er befindet sich in der Bibliothek WindowsBase.dll, die auch Teil der Windows Presentation Foundation (WPF) ist. (Die hier vorgestellte Entwicklung ist damit in der Lage, ein als Vorlage bereitstehendes XPS zu erzeugen. Um die Vorlage direkt bearbeiten zu können, verwendet das Beispiel jedoch das Word-Format.) Das Auspacken erledigt der Entwickler über folgende Codezeilen:
Package package = Package.Open(
documentStream,
FileMode.Open,
FileAccess.ReadWrite);
Als Basis dient ein Objekt vom Typ Stream, das sich aus einer Dokumentenbibliothek beschaffen lässt. Dazu muss ein als Vorlage geeignetes Dokument vorhanden sein. Wichtig sind auch die Namen für die Felder der Liste, die ausgegeben werden soll. Um einen sich wiederholenden Abschnitt zu erhalten, bietet sich eine Tabelle an. Dazu erstellt man als Entwickler eine Zeile mit Platzhaltern, die man mit Daten gefüllt wiederholt in die Tabelle einsetzt (vgl. Abb. 1).
Einführen von Platzhaltern
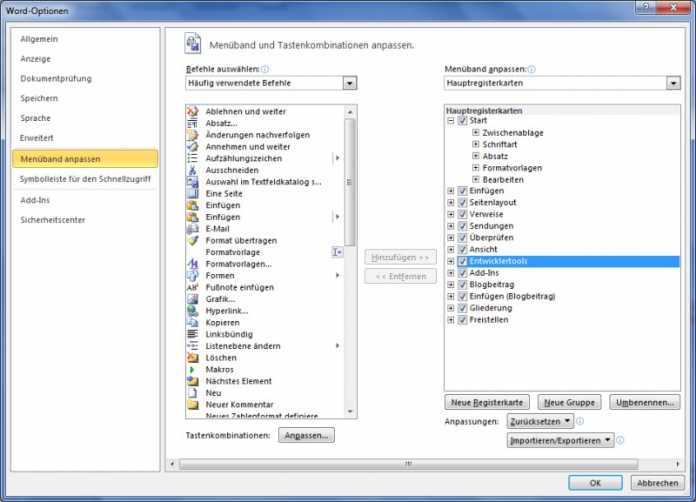
Anwender müssen diese Platzhalter auch als solche erkennen, um ungewollte Formatierungen der Tabelle auszuschließen. Man führt sie daher am besten über Steuerelemente als einfache Textfelder ein. In Word aktiviert man dazu die Entwickler-Toolbar (Abb. 2). Über den Eigenschaften-Dialog des jeweiligen Felds lässt sich der Name festlegen, der mit dem Feldnamen der Liste in SharePoint übereinstimmen muss.
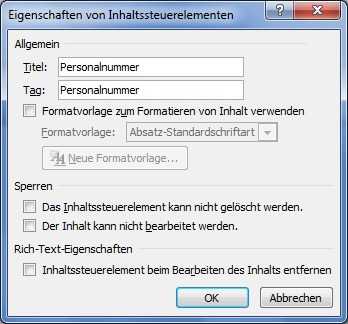
In Abbildung 3 ist zu sehen, wie sich ein eingefügtes Textfeld mit der Option Eigenschaften anpassen lässt. Der Tag-Name wird hier auf den Namen des Listenfelds gesetzt ("Personalnummer"). Alles Weitere geschieht außerhalb der Entwickleransicht und beschränkt sich auf das Formatieren der Seite.
Im nächsten Schritt ist die Vorlage aus der Dokumentenbibliothek WordTemplates auszulesen. Dazu benötigt der Entwickler ein Objekt vom Typ SPDocumentLibrary:
SPDocumentLibrary templateLib =
web.Lists.Cast<SPList>().FirstOrDefault(
list => list.RootFolder.Name == "WordTemplates")
as SPDocumentLibrary;
Alle weiteren Zugriffe erfolgen auf ähnliche Weise. Die Ergebnisse legt man in WordReports ab. Nun soll der Code für alle derartigen Fälle zum Einsatz kommen. Dazu bestimmt der Entwickler die Namen der Bibliotheken (bei Bedarf lässt sich das auch über Parameter regeln). Der Name der Vorlage ist hier mit ReportTemplate.docx festgelegt, während das Ergebnis den Zeitstempel als Teil des Dateinamens erhält.
Ein- und Ausgabe
Was eingegeben wird und dabei herauskommt
Die Vorlage wird als Stream gelesen:
string documentUrl = SPUrlUtility.CombineUrl
(web.Site.MakeFullUrl(templateLib.RootFolder.Url), templateName);
SPFile template = templateLib.RootFolder.Files[documentUrl];
Stream templateStream = template.OpenBinaryStream();
Wer sich im Umgang mit der SharePoint-Entwicklung nicht ganz sicher fühlt, sollte sich Klassen wie SPUrlUtility genauer ansehen. Sie helfen, die passenden Operationen elegant auszuführen. Das Objekt web liefert SPWeb, also die Anwendung, in der sich die Listen befinden. Der Code liest das betreffende Dokument aus der Dokumentenbibliothek und übergibt es als Stream. Wie gezeigt, ist das der Eingabetyp für die Packaging-Klasse. Die Ausgabe erfolgt über denselben Weg, nur wird der Stream hier geschrieben. Aus dem Paket liest der Entwickler die oben erwähnte Word-Datei document.xml wie folgt ein:
Uri uri = new Uri("/word/document.xml", UriKind.Relative);
PackagePart part = package.GetPart(uri);
Über einen Zwischenschritt (Listing 1 [7]) lädt er die Datei in ein XDocument-Objekt. In WordML [8] bietet es sich an, den nötigen Namensraum und die Tag-Namen vorzuhalten, da das endlose Erzeugen von XName-Objekten den Code sonst unleserlich macht. Listing 2 [9] zeigt, was für das Projekt nötig ist. Mit W.tagName lässt sich nun über nur zwei Anweisungen auf die Tabelle und die Platzhalter zugreifen. Tabellen basieren auf dem Tag <w:sdt>:
XElement tablePlaceHolder = doc.Descendants(W.sdt).FirstOrDefault(x =>
x.Element(W.sdtContent).Descendants(W.sdt).FirstOrDefault() != null);
Ihr Inhalt steht in <w:stdContent>, dieses Element wird im Aufruf zurückgegeben und daraus die Tabellenreihe extrahiert. Der Variablenname prototype dient als Vorlage für die wiederholte Ausgabe der Inhalte:
XElement prototype =
tablePlaceHolder.Element(W.sdtContent).Descendants(W.tr)
.Where(x => x.Descendants(W.sdt).FirstOrDefault() !=
null).FirstOrDefault();
Her mit den Daten
Im nächsten Schritt sind die Daten zu beschaffen. Dazu muss der Entwickler zunächst alle Elemente der SharePoint-Liste, im Beispiel mit dem Namen Finances, auslesen:
SPList dataList = web.Lists.Cast<SPList>().FirstOrDefault(list =>
list.RootFolder.Name == "Finances");
IEnumerable<SPListItem> allItems =
dataList.GetItems(new SPQuery()).Cast<SPListItem>();
Die LINQ-Abfrage nutzt ein LINQ-to-Object. Mit ihm wendet der Code hier eine LINQ-Abfrage auf einem IEnumerable<SPListItem> an, um die Listendaten komplett im Speicher zu verarbeiten. Bei großen Datenmengen sollte davor die passende CAML-Abfrage gesetzt werden, die sich in das genutzte SPQuery-Objekt platzieren lässt.
allItems dient jetzt als Datenquelle, und jedes Element produziert eine Reihe Daten auf Basis der Variablen prototype. Anschließend folgt eine komplexere LINQ-Anweisung, bei der die innere foreach-Schleife die Platzhalter-Elemente aus dem Prototyp in die Variable celltype holt. Die hat – per Definition – den Namen des Felds der Datenliste. Sicherheitshalber prüft der Programmierer den Namen mit ContainsField. Über li[celltag] kommt er an die Daten, die String.Format-Anweisung konvertiert sie in einen String und deutet zudem an, dass sich weitere Formatierungen einbauen lassen, um nachträglich komplexe Operationen zu ermöglichen. Auch eine Abfrage von Formatanweisungen aus der Quellliste wäre denkbar.
Da man für jede Datenreihe eine neue Tabellenreihe erstellen muss, ist noch der ursprüngliche Prototyp zu entfernen. Der fertige Bericht liegt jetzt bereits in XML vor. Über File.Add übergibt der Entwickler ihn an die Dokumentenbibliothek (die Quelle ist ein Stream). Anwender können sich den Bericht dann direkt aus der Bibliothek herunterladen.
Fazit
Eine Kombination aus SharePoint als Dokumentenverwaltungsapplikation, der SharePoint API und .NET 3.5 mit LINQ erlaubt eine codeseitig recht kompakte Umsetzung. Wie viel Kontrolle in der Vorlage ist und wie viel in der Datenquelle, hängt von der Anwendung und auch von den Benutzern ab. Prinzipiell ist es von Vorteil, die Gestaltung in Word sowie die Datenformatierung, Aufbereitung und Bereitstellung in der Applikation zu erledigen. Im Buch "SharePoint 2010 as a Development Platform" [1] gibt es dazu zahlreiche Anregungen.
Zwar bietet SharePoint 2010 Enterprise mit Word Services eine integrierte Funktion, um Word-Dokumente zu erzeugen, technisch ist das aber anspruchsvoll. Zudem ist die Enterprise-Lizenz recht teuer. Mit dem vorgestellten Beispiel, das sich auch in SharePoint 2010 und 2007 sowie Office 2010 und 2007 in jeder Kombination einsetzen lässt, kann man sich unnötigen Lernaufwand und Geld sparen. Und auf dem Server muss nicht einmal Office vorhanden sein, da der Entwickler direkt im XML arbeitet.
Jörg Krause
arbeitet mit den Schwerpunktthemen Programmierung von Web- und Datenbankapplikationen mit .NET sowie SharePoint- und BizTalk-Programmierung als Senior Consultant bei Computacenter.
Julius Eder
ist Berater und Entwickler für IT-Prozessentwicklungen auf Basis von ASP.NET, SharePoint, Silverlight und SQL Server bei Computacenter.
Literatur
- Jörg Krause, Christian Langhirt, Alexander Sterff, Bernd Pehlke, Martin Döring; SharePoint 2010 as a Development Platform; apress 2010
Listing 1
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Microsoft.SharePoint;
using Microsoft.SharePoint.Utilities;
using System.IO;
using System.IO.Packaging;
using System.Xml;
using System.Xml.Linq;
namespace DocxDemo
{
class Program
{
static void Main(string[] args)
{
using (SPSite site = new SPSite("http://localhost"))
using (SPWeb web = site.OpenWeb())
{
SPDocumentLibrary templateLib =
web.Lists.Cast<SPList>().FirstOrDefault(list =>
list.RootFolder.Name == "WordTemplates") as SPDocumentLibrary;
SPDocumentLibrary reportLib =
web.Lists.Cast<SPList>().FirstOrDefault(list =>
list.RootFolder.Name == "WordReports") as SPDocumentLibrary;
SPList dataList = web.Lists.Cast<SPList>().FirstOrDefault(list =>
list.RootFolder.Name == "Finances");
string templateName = "ReportTemplate.docx";
string reportName = String.Format("DailyReport{0}.docx",
DateTime.Now.ToShortDateString());
string documentUrl =
SPUrlUtility.CombineUrl(web.Site.MakeFullUrl
(templateLib.RootFolder.Url), templateName);
SPFile template = templateLib.RootFolder.Files[documentUrl];
Stream templateStream = template.OpenBinaryStream();
Stream documentStream = new MemoryStream();
BinaryReader templateReader = new BinaryReader(templateStream);
BinaryWriter documentWriter = new BinaryWriter(documentStream);
documentWriter.Write(templateReader.ReadBytes((int)templateStream.Length));
documentWriter.Flush();
templateReader.Close();
templateStream.Dispose();
Package package = Package.Open(documentStream, FileMode.Open,
FileAccess.ReadWrite);
Uri uri = new Uri("/word/document.xml", UriKind.Relative);
PackagePart part = package.GetPart(uri);
Stream partStream = part.GetStream(FileMode.OpenOrCreate,
FileAccess.ReadWrite);
XmlReader xmlReader = XmlReader.Create(partStream);
XDocument doc = XDocument.Load(xmlReader);
xmlReader.Close();
XElement tablePlaceHolder = doc.Descendants(W.sdt)
.FirstOrDefault(x => x.Element(W.sdtContent) .Descendants(W.sdt)
.FirstOrDefault() != null);
XElement prototype = tablePlaceHolder.Element(W.sdtContent)
.Descendants(W.tr) .Where(x => x.Descendants(W.sdt)
.FirstOrDefault() != null) .FirstOrDefault();
IEnumerable<SPListItem> allItems = dataList.GetItems(new
SPQuery()).Cast<SPListItem>();
prototype.Parent.Add(allItems.Select(li =>
{
var result = new XElement(prototype);
foreach (var placeholder in result.Descendants(W.sdt))
{
string celltag = placeholder.Element(W.sdtPr)
.Element(W.tag) .Attribute(W.val) .Value;
if (li.Fields.ContainsField(celltag))
{
placeholder.Element(W.sdtContent) .Descendants(W.t)
.Single() .Value = String.Format("{0}", li[celltag]);
}
else
{
placeholder.Element(W.sdtContent) .Descendants(W.t)
.Single() .Value = String.Empty;
}
}
return result;
}));
prototype.Remove();
partStream.SetLength(0);
XmlWriter writer = XmlWriter.Create(partStream); doc.WriteTo(writer);
writer.Close(); package.Flush();
string reportUrl =
SPUrlUtility.CombineUrl(web.Site.MakeFullUrl(reportLib.RootFolder.Url),
templateName);
SPFile report = reportLib.RootFolder.Files.Add(reportUrl,
documentStream, true);
SPListItem reportItem = report.Item;
reportItem["Title"] = reportName; // Set Metadata reportItem.Update();
}
}
}
}
Listing 2
Listing 2
public static class W
{
public static XNamespace w =
"http://schemas.openxmlformats.org/ wordprocessingml/2006/main";
public static XName body = w + "body";
public static XName sdt = w + "sdt";
public static XName sdtPr = w + "sdtPr";
public static XName tag = w + "tag";
public static XName val = w + "val";
public static XName sdtContent = w + "sdtContent";
public static XName tbl = w + "tbl";
public static XName tr = w + "tr";
public static XName tc = w + "tc";
public static XName p = w + "p";
public static XName r = w + "r";
public static XName t = w + "t";
public static XName rPr = w + "rPr";
public static XName highlight = w + "highlight";
public static XName pPr = w + "pPr";
public static XName color = w + "color";
public static XName sz = w + "sz";
public static XName szCs = w + "szCs";
} (ane [10])
URL dieses Artikels:
https://www.heise.de/-1754433
Links in diesem Artikel:
[1] http://de.wikipedia.org/wiki/Office_Open_XML/
[2] https://www.heise.de/hintergrund/Datenquellen-im-Griff-mit-SharePoints-DataFormWebPart-1383056.html
[3] https://www.heise.de/hintergrund/Geschaeftsdaten-mit-SharePoint-und-NET-aufbereiten-1406197.html
[4] https://www.heise.de/hintergrund/Mobile-Webapps-fuer-SharePoint-entwickeln-1573119.html
[5] https://www.heise.de/hintergrund/SharePoint-2010-Ribbons-anpassen-und-verwenden-1702510.html
[6] http://en.wikipedia.org/wiki/Open_Packaging_Conventions
[7] http://www.heise.de/developer/artikel/Dynamische-Office-Dokumente-in-SharePoint-erzeugen-1754433.html?artikelseite=3
[8] http://de.wikipedia.org/wiki/WordprocessingML
[9] http://www.heise.de/developer/artikel/Dynamische-Office-Dokumente-in-SharePoint-erzeugen-1754433.html?artikelseite=4
[10] mailto:ane@heise.de
Copyright © 2012 Heise Medien