

Eine eigene Programmiersprache mit Xtext modellieren
Mit Xtext, einem Sprachframework auf der JVM, ist es mit wenig Aufwand möglich, eine eigene Programmiersprache zu definieren. Dieser Artikel zeigt den Werdegang einer kleinen domänenspezifischen Sprache von der Definition der Grammatik bis hin zur lauffähigen IDE.

- Markus Amshove
- Stefan Macke
Allgemeine Programmiersprachen (General Purpose Languages, GPL) – zum Beispiel Java oder C# – bieten die Möglichkeit, Lösungen für alle nur denkbaren Probleme umzusetzen. Aber das ist meist mehr, als benötigt wird, oder der Code besteht aus vielen sich wiederholenden Bestandteilen. Dem gegenüber stehen domänenspezifische Sprachen (Domain Specific Languages, DSL) wie SQL, die einen eingeschränkten Funktionsumfang haben, die Problemdomäne aber vollständig und präzise beschreiben.
Prägnant statt Boilerplate
Als Beispiel für Boilerplate-Code in Java dienen die sogenannten POJOs (Plain Old Java Objects). Ihre Getter und Setter sind sich wiederholende Bestandteile, die meistens keinen echten Mehrwert bieten. Das folgende Listing zeigt ein POJO zur Darstellung einer Person mit einem einzigen Attribut Name:
public class Person
{
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
@Override
public String toString()
{
return String.format("Objekt %s { Name = %s }",
"Person",
getName()
);
}
}
In einer speziell für die Abbildung solcher Datenmodelle definierten DSL könnte obiges Beispiel wie folgt aussehen:
Eine Person hat Name vom Typ Text.
Der Artikel beschreibt im Folgenden den Werdegang dieser kompakten und trotzdem verständlichen Sprache zur einfachen Definition von POJOs mit dem Framework Eclipse Xtext. Ziel ist es, mit ihr den obigen Java-Code zu generieren. Den kompletten Sourcecode gibt es zum Download bei GitHub.
Xtext und Xtend
Xtext ist ein Open-Source-Framework zur Entwicklung von Programmiersprachen und DSLs auf der Java-Plattform. Es bietet eine nahtlose Integration in bekannte Entwicklungsumgebungen wie Eclipse oder IntelliJ IDEA und arbeitet mit etablierten Build-Werkzeugen wie Gradle oder Maven zusammen. Gestützt durch den bekannten Parsergenerator ANTLR lässt sich etwa aus einer Grammatik recht einfach ein lauffähiges Plug-in für Eclipse erzeugen, das Syntax-Hightlighting, Code-Vervollständigung, Formatierung und vieles andere mehr bietet.
Das obige Beispiel der sprechenden Definition eines Datenmodells ließe sich durch eine Grammatik wie die folgende umsetzen:
grammar net.aokv.Datenmodell with org.eclipse.xtext.common.Terminals
generate datenmodell "http://www.aokv.net/Datenmodell"
Datenmodell:
elemente+=Datendefinition*;
Datendefinition:
Artikel name=ID 'hat' (attribute+=Attribut*) '.';
Attribut:
name=ID 'vom Typ' datentyp=Datentyp 'und'?;
Artikel:
'Ein' | 'Eine';
enum Datentyp:
Text | Zahl;
Eine Grammatik in Xtext, die übrigens selbst eine Xtext DSL ist, nämlich zur Beschreibung textueller Sprachen, beginnt mit der Deklaration der Sprache, wie in den ersten beiden Zeilen des Listings zu sehen ist. Die zweite Zeile weist Xtext an, aus der folgenden Grammatik eine Repräsentation in Form eines Objektgraphen mit dem Namen datenmodell zu erzeugen. Er lässt sich später nutzen, um zum Beispiel bei der Entwicklung von Code-Generatoren einfach auf die Bestandteile des konkreten Programms zuzugreifen.
Danach folgen die Regeln der DSL. Die einfachsten, Artikel und Datentyp, sind sogenannte terminale Regeln, die eine einzige atomare Ausgabe erzeugen. In diesem Fall definieren sie lediglich eine Auswahl an Alternativen (Operator |) mehrerer Schlüsselwörter (String-Literale Ein und Eine) oder Enum-Werte (Text und Zahl). Schlüsselwörter der DSL (vergleichbar mit class in Java) hebt der Editor später zum Beispiel automatisch farbig hervor und vervollständigt sie.
Die komplexeren Parser-Regeln – etwa Datenmodell oder Attribut – bestehen zusätzlich zu terminalen Elementen aus Referenzen auf andere Regeln. Sie produzieren keinen einzelnen Wert, sondern einen ganzen Parser-Baum. In Form von Objekten werden sie Teil des Abstract Syntax Tree (AST). In der baumförmigen Repräsentation des Programms lässt sich später auf objektorientierte Art navigieren, indem beispielsweise die Attribute der Objekte (Features genannt) abgefragt werden. Ein Beispiel hierfür ist die oberste Regel Datenmodell, die später als Objekt im AST ein Feature elemente haben wird, über das sich die einzelnen Datendefinitionen erreichen lassen.
Der Zuweisungsoperator += fügt die Datendefinitionen der Liste elemente hinzu. Dabei kennzeichnet die Kardinalität * aus der erweiterten Backus-Naur-Form, dass es keine oder mehrere Elemente geben kann. Die Kardinalitäten werden durch die gleichen Symbole verdeutlicht, die auch bei regulären Ausdrücken zum Einsatz kommen: ? für kein oder ein Element, + für ein oder mehrere und * für kein, ein oder mehrere Elemente.
Das Terminal ID, das Xtext selbst zur Verfügung stellt, steht für einen beliebigen gültigen Bezeichner, den der Benutzer später im Programm definieren kann. Im Beispiel kommt Person zum Einsatz, um der beschriebenen Entität einen Namen zu geben. Diese Bezeichner lassen sich etwa in Code-Generatoren auslesen und verwenden, um die Ausgabe der DSL zu programmieren (z. B. public class Person { ... }).
Praxis
Implementierung der Code-Generatoren
Auf Basis der Grammatik erzeugt Xtext beim Parsen der geschriebenen DSL einen Graphen in Form von Java-Objekten. Diese lassen sich nutzen, um Generatoren für beliebigen Output zu implementieren. Hierfür kommt Xtend zum Einsatz, eine ebenfalls in Xtext entwickelte Programmiersprache, die in Java kompiliert. Das folgende Listing zeigt einen Ausschnitt der Generierung der oben gezeigten POJOs in Xtend.
val attributMapping = #{ Datentyp.TEXT -> "String", Datentyp.ZAHL -> "int" }
def compile(Datendefinition datendefinition)
'''
public class «datendefinition.name»
{
«FOR attribut : datendefinition.attribute»
«generiereAttribut(attribut)»
«ENDFOR»
}
'''
def generiereAttribut(Attribut attribut)
{
val datentyp = attributMapping.get(attribut.datentyp)
val kleinerName = attribut.name.toLowerCase
'''
private «datentyp» «kleinerName»;
public «datentyp» get«attribut.name»()
{
return «kleinerName»;
}
public void set«attribut.name»(«datentyp» «kleinerName»)
{
this.«kleinerName» = «kleinerName»;
}
'''
}
Xtend unterstützt die Code-Generierung durch verschiedene Sprach-Features. Darunter fällt zum Beispiel die String-Interpolation, die in der Methode compile zu sehen ist. Innerhalb einer von ''' umschlossenen CharSequence lassen sich zwischen « und » (Guillements) beliebige Variablen und Ausdrücke verwenden. Der restliche Text wird inklusive Whitespace übernommen. Das führt dazu, dass auch der generierte Code korrekt wie dargestellt eingerückt wird.
Analog zu anderen Template-Sprachen wie ERB in Ruby on Rails oder Razor in .NET ist es möglich, Kontrollstrukturen in der String-Interpolation zu nutzen. Oben dargestellt ist eine Enhanced-For-Schleife innerhalb des Strings, um die Attribute der Datendefinition zu durchlaufen und für jedes von ihnen den Getter- und Setter-Code an dieser Stelle einzufügen.
Darüber hinaus bietet Xtend einige weitere Features, die den Code kompakt und lesbar halten:
- Extension Methods: Fremde Typen lassen sich durch eigene Methoden um Funktionen erweitern.
- Lambda-Ausdrücke: Anonyme Funktionen können in Parametern, Rückgabewerten und Variablen gespeichert werden.
- Type Inference: Entwickler können die redundante Angabe von Typen zum Beispiel bei der Variablendeklaration vermeiden.
- Operator-Überladung: Operatoren lassen sich für eigene Typen definieren.
- Multiple Dispatch: echte Polymorphie bei Methodenaufrufen.
Lauffähige IDE zur Programmierung in der DSL
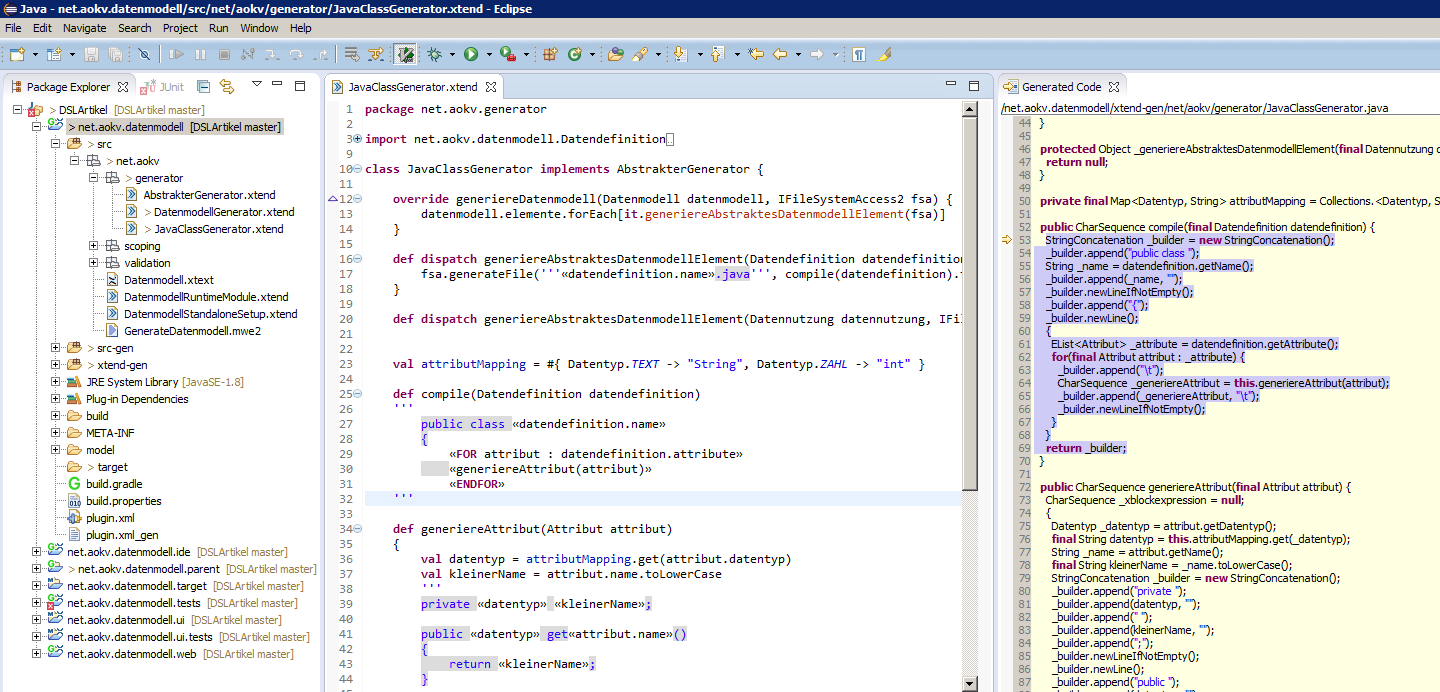
In der folgenden Abbildung ist die Entwicklung der Code-Generatoren mit Xtend in Eclipse zu betrachten. Im Editor-Fenster ist auch der sogenannte Greyspace zu sehen. Die String-Interpolation von Xtend stellt Whitespace im später generierten Code bereits während der Entwicklung dar. Im rechten Fenster erkennt man den Java-Code, in den Xtend kompiliert. Um eine lauffähige Eclipse-Umgebung mit dem geladenen Plug-in für die DSL zu starten, gibt es eine vordefinierte Run-Konfiguration.
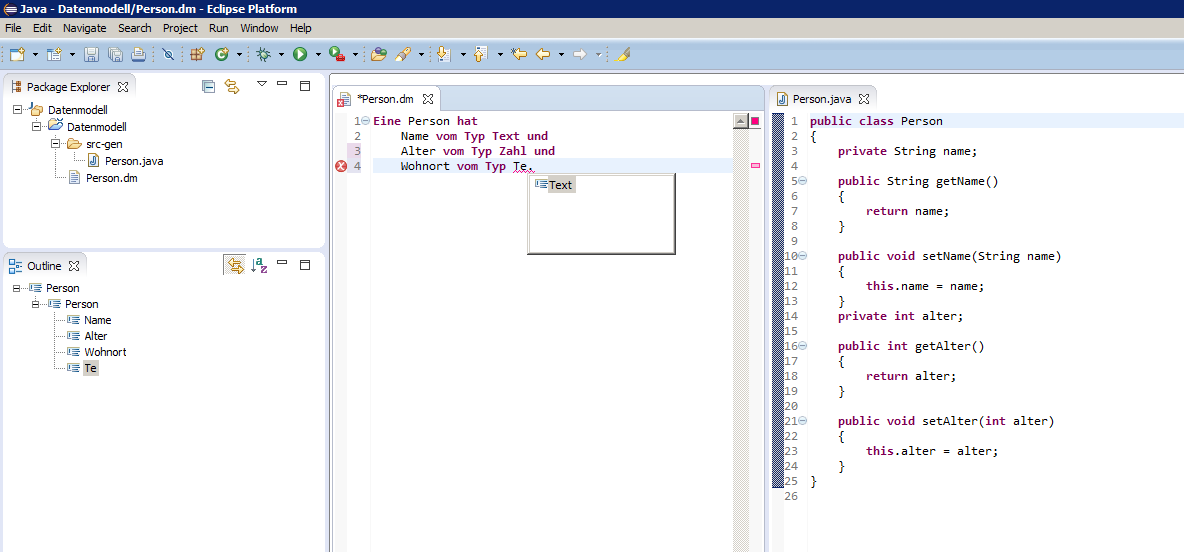
Die zweite Abbildung zeigt die gestartete Eclipse-Umgebung mit dem geladenen DSL-Plug-in. Zu sehen sind beispielsweise die Code-Vervollständigung, Fehler- und Syntax-Highlighting sowie die Outline. Aus der DSL in der Datei Person.dm generiert das Plug-in bei jedem Speichern automatisch die Java-Klasse in Person.java im Ordner src-gen.
Praxisbeispiele für DSLs
Es gibt prominente Beispiele, die durch oder als eine DSL umgesetzt sind. Unter anderem sind Inform7, eine Sprache zur Gestaltung interaktiver Textadventures, Gradle, ein Build-Tool mit einer eigenen DSL, und e(fx)clipse zur Unterstützung der Entwicklung von JavaFX innerhalb von Eclipse mit Xtext entwickelt.
Bei der Alten Oldenburger Krankenversicherung AG, bei der die beiden Autoren beschäftigt sind, wurden innerhalb der letzten zwei Jahre mehrere DSLs erfolgreich mit Xtext umgesetzt. Einige Beispiele werden im Folgenden kurz beschrieben.
- Routing: Das Routing des gesamten Posteingangs im Dokumentenmanagementsystem wird anhand von Regeln in einer DSL beschrieben, die C#-Code generiert.
- Domänenmodell: Auf Basis einer DSL für das Domänenmodell ähnlich der oben beschriebenen werden Artefakte für verschiedene Plattformen generiert (z. B. Java-Klassen, XML-Schemas, Adapter-Code für ein Legacy-System).
- Formeln: Komplette Programme für versicherungsmathematische Berechnungen im Legacy-System werden über eine an die mathematische Syntax angelehnte DSL generiert.
- Datenbank: Die gesamte Datenbankzugriffsschicht im Legacy-System wird vollständig auf Basis einer DSL erzeugt.
Fazit
Lessons Learned
Die bei der Umsetzung der obigen DSLs gemachten Erfahrungen lassen sich wie folgt zusammenfassen.
Vorteile:
- DSLs vereinfachen komplexe Sachverhalte durch prägnanten Quellcode, und wiederkehrende Probleme lassen sich mit wenig Aufwand lösen.
- Durch kurze Definitionen innerhalb einer DSL lässt sich bei gleichem Ergebnis auf viel Boilerplate-Code verzichten.
- Die definierten DSLs kann man fachbereichstauglich gestalten.
- Den zu generierenden Code können erfahrene Entwickler vorgeben, sodass er den Qualitätsanforderungen des Unternehmens entspricht.
- Sie können mehrere definierte DSLs referenzieren, die so miteinander arbeiten.
- Xtext wird aktiv weiterentwickelt, und der Umfang der Features wächst mit jedem Release.
Nachteile:
- DSLs lösen bestimmte Probleme gut, sind aber kein Allheilmittel für die Softwareentwicklung.
- Die Xtext-Entwicklungsumgebung büßt bei großem Projektumfang etwas Geschwindigkeit ein.
- Für den Einsatz von Xtext sind zwei neue Sprachen (Xtext und Xtend) zu lernen.
- Der automatische Build ohne Eclipse für Continuous Integration ist noch optimierungswürdig.
- Die Entwicklung einer DSL erfordert abstrakteres Denken, um Probleme allgemeiner zu formulieren.
Fazit
DSLs bieten eine gute Möglichkeit, von technischen Problemen zu abstrahieren und sie dadurch fachlicher und verständlicher auszudrücken. Damit ist nicht mehr sichtbar, wie etwas passiert; der Fokus liegt allein darauf, was geschieht.
Ein prominentes Beispiel für diese deklarative Beschreibung eines Problems anhand einer DSL ist SQL. Hier wird beispielsweise geschrieben, was gelesen werden soll. Wie das geschieht, entscheidet jedoch die Datenbank. Das hat den Vorteil, dass sich die Implementierung wahlweise ändern lässt, ohne die Problembeschreibung anpassen zu müssen. Beispielsweise könnte man das obige sprechende Datenmodell behalten und lediglich den Java-Generator (POJO) durch einen C#-Generator (POCO) ersetzen und damit die komplette zugrunde liegende Technologie austauschen.
Xtext eignet sich gut zur einfachen Umsetzung von DSLs, da sich aufgrund der Nähe zu Java ein schneller Lernerfolg einstellt. Anhand eines 15-Minuten-Tutorials werden die wichtigsten Grundlagen zur Grammatik vermittelt und nach weiteren 15 Minuten ist man in der Lage, einen Generator zu schreiben, seine DSL zu testen und somit einen Produktivitätsgewinn zu erzielen.
Markus Amshove
ist Softwareentwickler und dualer Student der Wirtschaftsinformatik bei der Alten Oldenburger Krankenversicherung AG. In seinen aktuellen Projekten hat er mehrere domänenspezifische Sprachen mit Xtext erstellt.
Stefan Macke
ist Softwareentwickler und -architekt bei der Alten Oldenburger Krankenversicherung AG. Seit 2007 ist er dort außerdem Ausbilder für Anwendungsentwickler. In seinen aktuellen Projekten beschäftigt er sich mit der
Modernisierung von Altanwendungen auf Basis einer serviceorientierten Architektur mithilfe von Java.
Onlinequellen
- Die obige Beispiel-DSL bei Github
- Implementing Domain-Specific Languages with Xtext and Xtend (Lorenzo Bettini)
(ane)
