

Einführung in die Aktor-Programmierung mit Akka
Akka ist eine mit Scala und Java verwendbare Implementierung des Actor-Modells für die Java Virtual Machine (JVM). Meist wird sie aus der Concurrency-Warte beschrieben. Robustheit ist allerdings eine ebenso wichtige Eigenschaft des Modells.
- Heiko Seeberger

Akka ist eine mit Scala und Java verwendbare Implementierung des Actor-Modells für die Java Virtual Machine (JVM). Meist wird sie aus der Concurrency-Warte beschrieben. Das hat durchaus seine Richtigkeit, denn schließlich handelt es sich bei Aktoren um eine Form der Nebenläufigkeit auf Basis der Message-Passing-Concurrency. Im Zentrum des Artikels steht jedoch eine andere, ebenso wichtige Eigenschaft des Actor-Modells, und zwar Robustheit, das heißt die Fähigkeit eines Systems, mit Fehlern erfolgreich umzugehen.
Man kann es drehen und wenden, Fehler lassen sich nicht vermeiden. Zum einen ist kein Programm fehlerfrei, auch kein nach allen Regeln der Kunst getestetes. Daher wird es früher oder später zwangsläufig dazu kommen, dass dem Entwickler Exceptions "um die Ohren fliegen". Zum anderen bringt der Trend hin zu verteilten Systemen noch ganz andere Fehlerquellen mit sich: Was passiert, wenn der Strom ausfällt? Oder die Putzkolonne über das Netzwerkkabel stolpert?
Für die Robustheit eines Systems ist es zunächst wichtig, dass es aus Komponenten aufgebaut ist, mit denen sich Fehler lokal eingrenzen lassen. Dadurch wird verhindert, dass eine fehlerhafte Komponente zwangsläufig das gesamte System "herunterzieht", auch wenn dadurch der Service-Level so lange verringert wird, bis sich die fehlerhafte Komponente wieder verwenden lässt oder man auf eine Alternative ausweichen kann.
Lose Kopplung durch asynchrone Nachrichten
Es dürfte rasch klar werden, dass die Komponenten eines robusten Systems lose gekoppelt sein müssen. Schließlich wird jegliches Wissen über den internen Zustand einer anderen Komponente bei einem Fehler dieser ungültig, sodass die abhängige Komponente anfällig für Fehler der anderen wird. Die (ursprüngliche) Objektorientierung antwortet auf diese Herausforderung, indem Objekte ihren Zustand verbergen und miteinander ausschließlich durch den Austausch von Nachrichten kommunizieren können.
Dieser Nachrichtenaustausch ist in objektorientierten Programmiersprachen wie Scala oder Java in Form synchroner Methodenaufrufe realisiert. Synchron bedeutet, dass der Programmfluss des Aufrufers unterbrochen wird, bis die aufgerufene Methode zurückkehrt oder eine Exception wirft. Ganz entscheidend ist, dass für letztere der Aufrufer zuständig ist. Das mag einem zwar ungewohnt vorkommen, jedoch kann man diese Form der Fehlerbehandlung anschaulich damit gleichsetzen, dass jeder Autofahrer jegliche Pannen selbst beheben können muss. Das führt letztlich doch wieder zu einer starken Kopplung zwischen den Objekten.
Um wirklich lose Kopplung zu erreichen, bedarf es daher asynchroner Kommunikation zwischen den Komponenten. Das heißt nichts anderes, als dass Nachrichten im Stil von Fire-and-forget versendet werden, der Programmfluss des Aufrufers also nicht unterbrochen wird, um auf eine Antwort zu warten. Eine solche wird vom Aufgerufenen womöglich später als weitere Nachricht zurückgeschickt. Dieses Prinzip ist bereits im "großen Maßstab" bekannt, etwa bei HTTP oder JMS (Java Message Service), aber es lässt sich auch auf die "Welt der kleinen Objekte" übertragen, und genau das tut das Actor-Modell. Darin sind Aktoren fundamentale Programmbausteine, die ausschließlich über asynchrone Nachrichten miteinander kommunizieren können.
Hello, World
"Hello, World!" mit Akka-Aktoren
Vor der Beleuchtung des Themas Robustheit sei ein erster Blick auf Akka und dessen Aktoren geworfen. Es ließe sich für die Code-Beispiele zwar auch Java verwenden, genommen wird aber lieber Scala, weil der Code damit leserlicher wird und weniger Ballast enthält. Eine Einführung in Scala findet man hier. Den Auftakt macht nun ein minimaler Aktor:
class Printer extends Actor {
override def receive: Receive = {
case message => println(message)
}
}
Der Programmierer erweitert den Actor-Trait und definiert die receive Methode, die das Verhalten des Aktors bestimmt, das heißt, auf welche Nachrichten er wie reagiert. Im Beispiel verarbeitet Printer alle Nachrichten, indem er sie einfach ausgibt. Um diesen Aktor in Aktion zu sehen, benötigt man eine ausführbare Applikation. Daher legt der Autor das Singleton-Objekt PrinterApp an und erweitert es um den App-Trait:
object PrinterApp extends App {
val system = ActorSystem("demo-system")
val printer = system.actorOf(Props(new Printer), "printer")
printer ! "Hello, world!"
Console.readLine(s"Hit ENTER to exit ...$newLine")
system.shutdown()
}
Von Carl Hewitt, dem Begründer des Actor-Modells, stammt der Spruch: "One actor is no actor; they come in systems." In Akka wird solch ein Ensemble von Aktoren durch ein ActorSystem repräsentiert, das unter anderem Factory-Methoden, Konfiguration und Thread-Management für die Aktoren bereitstellt. Im Beispiel erzeugt der Autor zunächst ein solches System und ruft dann die actorOf-Methode auf, die einen Printer-Aktor mit Namen "printer" erzeugt und darauf ActorRef zurückgibt.
Dass man niemals eine Instanz eines Aktors "in die Hände bekommt", ist ein grundlegendes Designprinzip von Akka. Es stellt sicher, dass sich nicht "aus Versehen" eine Methode eines Aktors direkt aufrufen lässt. Vielmehr kann der Programmierer durch ActorRef nur Nachrichten an den referenzierten Aktor schicken, wozu die !-Methode – sprich "Bang" – verwendet wird. Im Beispiel wird der bekannte Gruß "Hello World" geschickt.
Zu den Concurrency-Aspekte ist am Rande zu sagen: Das Senden und Verarbeiten von Nachrichten sind völlig unabhängige Aktionen, die höchstwahrscheinlich in verschiedenen Threads ablaufen. Beim Verarbeiten von Nachrichten übernimmt Akka – auf möglichst "günstige" Weise – die Speichersynchronisierung zwischen den Threads, sodass man quasi in einer Single-Threaded-Illusion programmieren kann. Mit anderen Worten muss sich der Entwickler innerhalb eines Aktors nicht mit synchronized, AtomicInteger, Locks et cetera herumschlagen.
Da ein ActorSystem die zugrunde liegende Maschinerie bereitstellt, um Nachrichten zuzustellen und der Verarbeitung durch Aktoren zuzuführen, wozu in der Regel letztlich ein Thread Pool verwendet wird, ist es wichtig, das ActorSystem "am Ende" herunterzufahren, also shutdown aufzurufen. Das geschieht aber erst, nachdem auf eine Eingabe im Terminal gewartet wurde. Denn sonst fährt das ActorSystem womöglich herunter, bevor der Printer die Nachricht verarbeiten kann, da Senden und Verarbeiten von Nachrichten in der asynchronen Welt separate Aktivitäten sind.
Lässt man das Beispiel innerhalb einer sbt-Session (Simple Build Tool) laufen, erhält man – wenig überraschend – das folgende Resultat:
[info] Running name.heikoseeberger.demoakka.PrinterApp
Hit ENTER to exit ...
Hello, world!
[success] Total time: 4 s, completed Jun 28, 2013 11:11:24 AM
Asynchron antworten
Doch wie kann man in dieser asynchronen Welt auf Nachrichten antworten beziehungsweise solche "erwarten"? Betrachtet sei dazu ein weiteres einfaches Beispiel:
class Echo extends Actor {
override def receive: Receive = {
case message => sender ! message
}
}
Statt Nachrichten einfach auszugeben, schickt der Echo-Aktor sie an den sender zurück. Dieser ist dann richtig definiert, wenn der Absender ebenfalls ein Aktor ist. Übernimmt der Entwickler die ausführbare Applikation quasi unverändert, ist das nicht der Fall und das Echo geht ins Leere, was jedoch keinen Fehler darstellt. Vielmehr kann es vorkommen, dass ein Aktor, für den man eine ActorRef besitzt, nicht mehr existiert: herzlich willkommen in der dynamischen asynchronen Welt.
Um Echo zu erhalten, benötigen der Programmierer also einen weiteren Aktor, der Nachrichten an Echo schickt und dessen Verhalten in der Lage ist, die Antwort zu verarbeiten:
object EchoApp extends App {
implicit val system = ActorSystem("demo-system")
val echo = system.actorOf(Props(new Echo), "echo")
actor(new Act {
context.system.scheduler.schedule(0 seconds, 2 seconds, echo,
"Hello, world!")(context.dispatcher, self)
become {
case message => println(message)
}
})
Console.readLine(s"Hit ENTER to exit ...$newLine")
system.shutdown()
}
Verwendet sei hierfür ein anonymer Aktor, für den sich die hier genutzte Actor-DSL gut eignet. In dessen Konstruktor nutzt man den Scheduler, um dem Echo-Aktor alle zwei Sekunden eine "Hello, world!"-Nachricht zu schicken. Wenn man dieses Beispiel nun laufen lässt, erhält man – wiederum wenig überraschend – das folgende Resultat:
[info] Running name.heikoseeberger.demoakka.EchoApp
Hit ENTER to exit ...
Hello, world!
Hello, world!
Hello, world!
[success] Total time: 13 s, completed Jun 28, 2013 11:10:27 AM
Fehlerbehandlung
Fehlerbehandlung durch Supervision
Zuvor wurde festgestellt, dass synchrone Methodenaufrufe im Fehlerfall zu starker Kopplung führen, weil der Aufrufer den Fehler des Aufgerufenen behandeln muss. Wie sieht es nun mit der Fehlerbehandlung im Falle asynchroner Kommunikation mit Nachrichten aus?
Es wird rasch klar, dass in einem robusten System jede Komponente einen Supervisor benötigt, der sich um deren Fehler kümmert. In Akka ist das in Form sogenannter Parental Supervision realisiert, was so viel bedeutet, dass sich ein Aktor um die Fehler der von ihm erzeugten Aktoren kümmert. Da in Akka jeder Aktor einen "Parent Actor" besitzt, ergibt sich eine Hierarchie von Aktoren, wie man das von einem Unternehmen kennt. Auch die Fehlerbehandlung gleicht weitgehend diesem anschaulichen Beispiel, denn wenn ein Mitarbeiter nicht weiter weiß, geht er in der Regel zum Chef, der sich darum kümmert oder seinerseits zu seinem Chef geht.
Vor der Fehlerbehandlung im Detail sei ein Blick auf die Aktor-Hierarchie in Akka geworfen. Jedes ActorSystem hat drei spezielle "System Actors", die die Spitze der Hierarchie bilden: Der "Root Guardian" ganz an der Spitze, darunter der "Guardian" für alle "User Actors", also die vom Programmierer angelegten, und schließlich der "System Guardian" für alle Akka-internen Aktoren.
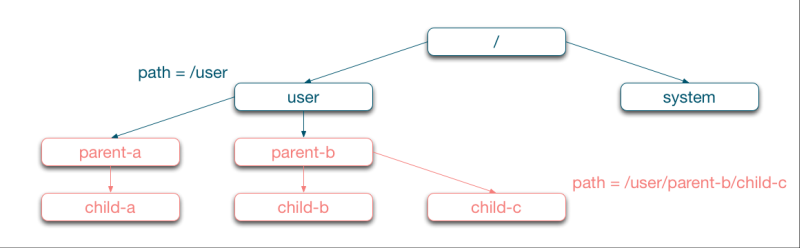
Wenn man mit ActorSystem.actorOf einen Aktor erzeugt, geschieht das unterhalb des Guardian. Da jeder Aktor einen ActorContext besitzt, der ebenfalls die actorOf-Methode zur Verfügung stellt, lässt sich innerhalb eines Aktors mit context.actorOf ein "Child Actor" anlegen:
class Parent extends Actor {
val echo = context.actorOf(Props(new Echo), "echo")
...
Doch wie werden Fehler behandelt? Diese sind hierbei Exceptions, die entweder bei der Initialisierung eines Aktors oder bei der Verarbeitung einer Nachricht durch einen Aktor geworfen werden. Aus Platzgründen lässt sich kein realistisches Beispiel aufführen, der Artikel begnügt sich mit der folgenden einfachen Modifikation des Echo-Aktors:
class Echo extends Actor {
override def receive: Receive = {
case "HARMLESS" => sys.error("HARMLESS")
case "SEVERE" => sys.error("SEVERE")
case "KILL" => sys.error("KILL")
case message => sender ! message
}
}
Es ist zu beobachten, dass Echo nun auf bestimmte Nachrichten hin Exceptions mit entsprechenden Fehlermeldungen wirft. Akka fängt solche Exceptions ab, deaktiviert die Nachrichtenverarbeitung des betroffenen Aktors und informiert den Parent Actor. Dieser muss nun entscheiden, wie es weitergehen soll, und hat dazu vier Möglichkeiten zur Auswahl: Er kann den betroffenen Aktor stoppen, neu starten, weiterlaufen oder den Fehler eskalieren lassen. In den ersten drei Fällen weiß der Parent Actor mit den Fehlern umzugehen, im letzten gibt er diesen eine Ebene weiter nach oben.
Welche Entscheidung ein Supervisor trifft, hängt stark davon ab, wie "ernsthaft" ein Fehler den betroffenen Aktor "schädigt": Falls der Aktor zustandslos ist, kann man diesen in der Regel einfach weiterlaufen lassen. Falls der Aktor hingegen veränderlichen Zustand besitzt, gilt es zu entscheiden, ob dieser noch intakt oder der Aktor neu zu starten ist. Letzteres bedeutet, dass – vom Rest der Welt umbemerkt – eine neue Instanz angelegt und anstelle der bisherigen der ActorRef "untergeschoben" wird. Im schlimmsten Fall wird der Aktor einfach gestoppt.
Diese Form der Fehlerbehandlung definiert die SupervisorStrategy des Aktors. Da jeder Aktor potenziell ein Parent Actor sein kann, besitzt auch jeder eine Standard-SupervisorStrategy, die bis auf wenige Ausnahmen den betroffenen Child Actor neu startet. Aber selbstverständlich lässt sich diese Strategie modifizieren, indem man die supervisorStrategy-Methode überschreibt, typischerweise sogar mit val, weil sich die Strategie normalerweise nicht ändert:
...
override val supervisorStrategy: SupervisorStrategy =
OneForOneStrategy(loggingEnabled = false) {
case e if e.getMessage == "HARMLESS" => SupervisorStrategy.Resume
case e if e.getMessage == "SEVERE" => SupervisorStrategy.Restart
case e if e.getMessage == "KILL" => SupervisorStrategy.Stop
}
actor(new Act {
echo ! "HARMLESS"
echo ! "After HARMLESS"
echo ! "SEVERE"
echo ! "After SEVERE"
echo ! "KILL"
echo ! "After KILL"
become {
case message =>
println(message)
}
})
override def receive: Receive =
Actor.emptyBehavior
}
In diesem zugegebenermaßen konstruierten Beispiel wurde die SupervisorStragety von Parent so auf die von Echo geworfenen Exceptions abgestimmt, dass er diesen Child Actor wahlweise stoppt, neu startet oder weiterlaufen lässt. Wohlgemerkt betrifft die gewählte OneForOneStrategy nur den fehlerhaften Aktor, zur Alternative stünde auch die AllForOneStrategy, die alle Child Actors gleichermaßen betrifft, auch die "gesunden". Um einige Nachrichten an Echo zu senden, verwendet man wieder einen anonymen Aktor wie zuvor.
Wiederum benötigt der Programmierer eine ausführbare Applikation, um das Beispiel in Aktion zu sehen:
object EchoApp extends App {
val system = ActorSystem("demo-system")
val parent = system.actorOf(Props(new Parent), "parent")
Console.readLine(s"Hit ENTER to exit ...$newLine")
system.shutdown()
}
Aktiviert er per Konfiguration das sogenannte "Life Cycle Debugging" und führt dann diese Applikation aus, erscheint dieses Resultat:
[info] Running name.heikoseeberger.demoakka.EchoApp
Hit ENTER to exit ...
...
After HARMLESS
11:20:03 DEBUG [akka://demo-system/user/parent/echo] - restarting
11:20:03 DEBUG [akka://demo-system/user/parent/echo] - restarted
After SEVERE
11:20:03 DEBUG [akka://demo-system/user/parent/echo] - stopped
...
[success] Total time: 11 s, completed Jun 28, 2013 11:20:07 AM
Es ist zu sehen, dass im Fall der HarmlessException "nichts Besonderes" passiert, weil der Aktor einfach weiterläuft. Bei der SevereException wird hingegen "restarting" und "restarted" ausgegeben, was gleichbedeutend mit dem Anlegen einer neuen Echo-Instanz ist. Offensichtlich führt die KillerException dazu, dass Echo gestoppt wird.
Das einfache Beispiel veranschaulicht, dass der Sender einer Nachricht Fehler eines Aktors nicht behandeln muss, sondern der Parent Actor des Empfängers. Diese Entkopplung von "Aufruf" und Fehlerbehandlung ist ganz entscheidend für die Robustheit, die das Actor-Modell bietet.
Fazit
Verteilte Systeme
Ein wirklich robustes System bedarf jedoch der Verteilung auf mehrere Knoten, um vor Hardwareausfällen gewappnet zu sein und im Fall stark steigender Last gegebenenfalls weitere Knoten hinzunehmen zu können.
Dank der losen Kopplung zwischen Aktoren durch asynchronen Nachrichtenaustausch eignet sich das Actor-Modell grundsätzlich hervorragend, um verteilte Systeme zu erstellen. Allerdings bedarf es hierfür zweierlei. Erstens muss der Nachrichtenaustausch optional über das Netzwerk statt innerhalb der JVM erfolgen können. Und zweitens bedarf "Remote Supervision" besonderer Vorkehrungen in Bezug auf die Verfügbarkeit der einzelnen Knoten – schließlich könnte der Parent Actor auf einem anderen Knoten laufen als dessen Child Actors.
Akka unterstützt durch Remoting und Cluster-Support beide Voraussetzungen und ist daher für die verteilte Welt gerüstet. Nun sei noch kurz darauf eingegangen, wie sich Nachrichten zwischen den Knoten austauschen lassen.
In Akka macht es für die Programmierung keinen Unterschied, ob das System in einer JVM läuft oder die Aktoren über verschiedene Knoten verteilt sind. Das bedeutet, dass die Verteilung eine reine Deployment-Entscheidung wird. Alles, was zu tun ist, ist das Modul akka-remote in den Klassenpfad aufzunehmen und einige Konfigurationsparameter hinzufügen:
akka {
actor {
provider = akka.remote.RemoteActorRefProvider
}
remote {
enabled-transports = [akka.remote.netty.tcp]
netty.tcp {
hostname = localhost
port = 2552
}
}
}
Mit diesen wenigen Einstellungen kann man Aktoren über Rechnergrenzen hinweg miteinander kommunizieren lassen. Im Beispiel wird TCP mit Netty verwendet, aber das Transportprotokoll ist flexibel und lässt sich austauschen.
Fazit
Akka implementiert das Actor-Modell für Scala und Java und bringt damit eine bewährte robuste Architektur auf die JVM. Die Robustheit beruht auf loser Kopplung zwischen Aktoren aufgrund asynchronen Nachrichtenaustauschs und klarer Trennung von Aufruf und Fehlerbehandlung. Durch diese lose Kopplung eignen sich Aktoren zudem hervorragend für verteilte Systeme, die wiederum die Voraussetzung für wirklich robuste Systeme darstellen.
Für weitere Informationen sei auf die Akka-Dokumentation verwiesen. Die gezeigten Beispiele stehen als vollständiges sbt-Projekt auf GitHub zur Verfügung.
Heiko Seeberger
ist als Director of Education für Typesafe tätig. Er hat mehr als 15 Jahre Erfahrung in der Beratung und Softwareentwicklung auf der Java-Plattform, trägt aktiv zu Projekten aus der Scala-Community bei und gibt seine Expertise regelmäßig in Form von Artikeln und Vorträgen weiter. Außerdem ist er der Autor des Buchs "Durchstarten mit Scala".
(ane)
