

Eingelocht
Fast täglich tauchen neue Einbruchsmöglichkeiten und Verwundbarkeiten in Applikationen oder Betriebssystemen auf. In vielen Fällen ist die Ursache ein Buffer-Overflow, zu Deutsch Pufferüberlauf.
- Stephan Kallnik
- Daniel Pape
- Daniel Schröter
- Stefan Strobel
- Daniel Bachfeld
Verfolgt man Berichte über Sicherheitslöcher in Software, könnte man glauben, dass es kaum ein Programm gibt, welches nicht durch einen Buffer-Overflow angreifbar ist. Kein Betriebssystem, kein Server und keine Applikation bleibt verschont von möglichen Schwachstellen, die durch Pufferüberläufe verursacht werden, selbst Firewalls sind betroffen. Das Hintergrundwissen, um Meldungen über Buffer-Overflows besser verstehen zu können und was man damit alles anstellen kann, liefert dieser Artikel.
Jedes Programm legt zur Laufzeit lokale Variablen, Übergabeparameter für Funktionen sowie Rücksprungadressen für Unterprogramme im Arbeitsspeicher, genauer auf dem Stack, ab. Dort sind sie vor ungewollten Änderungen nicht geschützt. Kopiert ein Programm eine Zeichenkette in eine lokale Puffervariable, so kann es zu einem Buffer-Overflow kommen, wenn die Zeichenkette größer als erwartet ist. Variablen und unter Umständen auch die Rücksprungadresse werden überschrieben. Meist geschieht dies bei Programmen in Verbindung mit Zeichenketten, insbesondere bei Programmen die in C geschrieben sind. C kennt keine Strings, deshalb werden Zeichenketten als eindimensionale Felder (Arrays) angelegt. Viele C-Funktionen kopieren Daten in solche Arrays -- ohne zuvor zu prüfen, ob diese dort hineinpassen. Dies hätte ein Programmierer eigentlich mit einer entsprechenden Abfrage sicherstellen müssen. Die Programmiersprache Java kennt dieses Problem nicht. Zeichenketten werden als Strings behandelt und der Puffer wird dynamisch angepasst.
Meist führt ein Buffer-Overflow zum Absturz des betroffenen Programms, weil Variablen unsinnige Werte enthalten oder die Rücksprungadresse ins Nirvana zeigt und einen Speicherzugriffsfehler provoziert. Gelingt es einem Angreifer aber, sinnvollen Code in den Stack zu schreiben, kann er durch das richtige Setzen der Rücksprungadresse diesen Code anspringen lassen und ausführen. Der Code lässt sich zum Beispiel als Benutzereingabe eingeschleusen. Vorgefertigter Assembler-Code zum Öffnen einer Root-Shell auf einem beliebigen TCP-Port passt in 200 Bytes und ist im Internet mittlerweile frei verfügbar.
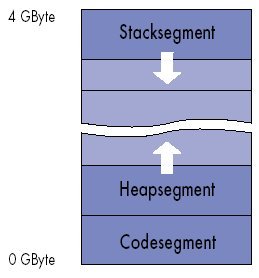
Bei modernen Betriebssystemen arbeitet jedes Programm in einem eigenen, virtuellen Adressraum, dessen Adressen die Hardware -- konkret die Memory Management Unit (MMU) -- erst bei Bedarf physikalischen Speicher zuordnet. Im virtuellen Speicher legt das Betriebssystem beim Start eines Programms drei Segmente an: das Code-Segment, das Daten-Segment (auch Heap genannt) und das Stack-Segment. Das Stack-Segment ist ein Zwischenspeicher für lokale Variable und gesicherte Prozessorregister, die das Programm zu einem späteren Zeitpunkt wieder benötigt. Der Stack beginnt am oberen Ende des Adressraums und wächst nach unten. Er funktioniert als Last-in-first-out-Puffer, den man erst abräumen muss, bevor man an früher abgelegte Daten kommt. Der Stack Pointer (ESP) markiert das Ende des Stacks und zeigt damit immer auf den letzten Eintrag.
C-Programme legen die Übergabeparameter einer Funktion, die Rücksprungadresse und lokale Variable auf dem Stack ab. Auf die lokalen Variablen greift die Funktion über einen Offset zum so genannten Base Pointer (EBP) zu, der auf ihren Datenbereich zeigt. Die beiden Basisoperationen für den Stack sind push und pop: push schreibt ein Register in den Stack und erniedrigt den ESP, pop liest es vom Stack und erhöht den ESP. Der Befehl RET in einer Unterfunktion lädt den Instruction Pointer (EIP) mit der Rücksprungadresse und springt damit zurück in das Hauptprogramm.
Hochstapler
Hochstapler
Folgendes Listing zeigt ein einfaches Beispielprogramm in C, Auszüge aus dem zugehörigen Assembler-Code und den Stack-Inhalt während der Ausführung der Funktion.
void function(int a, int b, int c) {
char buffer1[8];
char buffer2[16];
...
}
void main() {
function(1,2,3);
}
Assembler-Code
(Auszug aus "gcc -S -o example1.s example1.c")
function:
pushl %ebp # sichert EBP
movl %esp,%ebp # kopiert ESP nach EBP
subl $24,%esp # schafft Platz f. buffer1+2
movl %ebp,%esp # korrigiert EBP
...
popl %ebp
ret
main:
pushl %ebp
movl %esp,%ebp
pushl $3 # Parameter auf den Stack
pushl $2
pushl $1
call function # Funktionsaufruf
addl $12,%esp # Stack aufräumen

Auf dem Stack befinden sich unter anderem die lokalen Puffer buffer1 und buffer2 und die gespeicherte Rücksprungadresse. Kopiert man in der Funktion mit strcpy (buffer1, buffer2) den Inhalt des größeren, zweiten Puffers in den ersten, überschreibt diese Operation auch diese Rücksprungadresse. Der abschließende Assemblerbefehl ret holt diesen quasi zufälligen Wert vom Stack und schreibt ihn in den Instruction Pointer. Im nächsten Arbeitsschritt versucht der Prozessor, von dieser Adresse den nächsten Befehl zu laden -- was in der Regel fehlschlägt und eine Speicherschutzverletzung erzeugt.
Dass das nicht immer so sein muss, demonstriert das folgendes Beispiellisting:
void function(int a, int b, int c) {
char buffer1[8];
char buffer2[16];
int *ret;
ret = buffer1 + 12;
(*ret) += 8;
}
void main() {
int x;
x = 0;
function(1,2,3);
x = 1;
printf("%d\n",x);
}
Hier erhöht das Programm den Wert der Rücksprungadresse um 8 -- mit dem Resultat, dass es direkt den printf-Aufruf anspringt. Der Befehl x=1 kommt nicht zur Ausführung. Probieren Sie es aus: Das Programm gibt "0" aus. (Anmerkung: Je nach verwendetem Compiler muss der Wert in (*ret) += 8 variiert werden. Nicht jeder Compiler erzeugt den gleichen Assemblercode!)
Zahlenjongleur
Zahlenjongleur
Die Kunst eines Exploits besteht im richtigen Setzen der Rücksprungaddresse. Sie muss als absoluter Wert an die Stelle der Rücksprungadresse geschrieben werden. Ein Angreifer weiß aber nicht, wo sein Code beginnt, da ja bereits andere Daten auf dem Stack liegen. Als Trick stellt man dem eigentlichen Assembler-Code einfach mehrere NOP-Befehle voran, die nur ein Byte groß sind. Ist die Rücksprungadresse nun falsch, so landet man im schlechtesten Fall an irgendeinem NOP-Befehl. Diese werden abgearbeitet, bis man zum eigentlichen Code kommt.
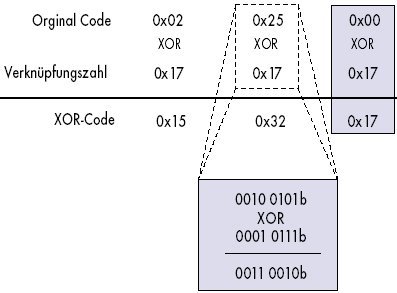
Eine weitere Hürde beim Einschleusen von Code besteht darin, dass die meisten Systeme das Ende einer Zeichenkette mit dem Wert "0" markieren, dieser in ausführbarem Code aber recht häufig auftaucht. Beim Kopieren einer Zeichenkette hören die Systemfunktionen beim ersten Zeichen mit diesem Wert auf: Der Code wird dann nur unvollständig übertragen. Auch hier greift man wieder zu Tricks: Zuweisungen wie mov 0,eax werden durch das gleichwertige "xor eax,eax" ersetzt. Alternativ kann man den Code mit einem Wert X über XOR verknüpfen. Den Wert X manipuliert man so lange, bis die Zeichenkette keine Nullen mehr enthält. Allerdings muss man diesem Code nun ein paar Zeilen Asssembler voranstellen, die das wieder rückgängig machen.

Schließlich muss man auch in einem solchen Exploit gelegentlich auf eigene Daten wie den String "/bin/bash" zugreifen. Da die absolute Position des Strings im Speicher nicht bekannt ist, muss die Adressierung relativ erfolgen. Doch relativ wozu? Auch hier greifen die Programmierer von Exploits zu einem Trick: Sie springen mit einem relativen Jump-Befehl an das Ende ihres Codes, hinter dem sich die benötigten Variablen befinden. Dort simulieren sie via call einen Funktionsaufruf auf den nächsten abzuarbeitenden Befehl. Dabei schiebt das System die nächste Adresse - also die des Stringanfangs - auf den Stack. Von dort kann man sie via pop in ein beliebiges Register befördern. Schon hat der Programmierer seinen Zeiger auf den eigenen Datenbereich.

Natürlich will der Angreifer in seinem Exploit Dateizugriffe oder den Start eines Programms nicht selbst in Assembler programmieren. Deshalb greift er auf Funktionen des jeweiligen Betriebssystems zurück. Linux bietet über den Software-Interrupt 0x80 Zugang zu allen wichtigen Funktionen. Um eine neue Datei anzulegen, genügt es, vor dem Aufruf von int 0x80 einige Register entsprechend zu präparieren. EBX muss die Adresse des Strings mit dem Dateinamen enthalten, ECX sorgt für passende Zugriffsrechte und EAX wählt mit dem Wert 0x8 den Systemaufruf create() aus. Mit 0x80 erhält man auch Zugriff auf die Funktion execve(), über das man externe Programme wie die Shell "/bin/sh" starten kann.
Unter Windows kann der Exploit-Code direkt alle Funktionen des Windows-APIs nutzen, die das Programm einbindet. Befindet sich darunter die Funktion LoadLibrary, kann der Angreifer auch beliebige Funktionen nachladen. Beim Aufruf der Windows-API-Funktionen müssen sich die Übergabeparameter wie bei einem normalen Funktionsaufruf in der richtigen Reihenfolge auf dem Stack befinden.
Evolution
Evolution
Neben den klassischen Buffer-Overflows tauchen auch vermehrt Angriffe über Format-Strings und Heap-Overflows auf -- auch als Exploits der dritten Generation bezeichnet. Format-Strings [4] werden in C-Programmen benutzt, um Ausgaben besser lesbar zu gestalten. Dazu wird ein solcher String entweder als Argument oder als Teil einer Zeichenkette übergeben. Neben üblichen Format Strings (%d, %s, %h) existiert auch ein selten benutzter: %n. Dieser weist die printf-Funktion an, die Anzahl der übergebenen Zeichen an eine wählbare Adresse zu schreiben [5]:
printf ("%.*d%n\n", (int) attack_code , 0 , return_addr_ptr);
In diesem Beispiel lässt sich die exakte Anzahl der zu schreibenden Werte definieren (%.*d), der Wert attack_code wird an die Stelle geschrieben, auf die return_addr_ptr zeigt. Zu Problemen kann es kommen, wenn es einem Angreifer gelingt, obige Zeichenkette irgendwie an printf() zu übergeben. Verwundbarer Code sieht zum Beispiel so aus:
while (fgets(buf, sizeof buf, f))
lreply(200, buf);
...
}
void lreply(int n, char *fmt, ...) {
...
vnsprintf(buf, sizeof buf, fmt, ap);
...
}
Der Ausschnitt liest eine Zeile vom Netzwerk und übergibt sie an lreply(), welche sie wiederum an vnsprintf() weitergibt. vsnprintf() wertet ebenfalls Format-Strings aus. Dabei hat der Programmierer hier bei der Übergabe vergessen, den Format-String-Specifier (lreply(200, "%s", buf)) anzugegeben. Enthält buf Format-Strings wie oben, lässt sich eigener Code in den Speicher schreiben und im Kontext des Programmes, welches vnsprintf() aufgerufen hat, ausführen. Im Gegensatz zu den klassischen Buffer Overflows ist ein Angreifer nun nicht mehr auf den Stack beschränkt. Glücklicherweise finden sich derartige Schwachstellen relativ selten, obwohl sie im Quellcode leicht zu entdecken sind.
Heap-Overflows [6] machen sich spezifische Eigenschaften verschiedener Compiler beim Reservieren und Freigeben von Datenbereichen zu Nutze. Man kann durch geschickte Wahl der Parameter gezielt Datenbereiche mit beliebigem Code überschreiben und ausführen. Heap-Overflows sind schwer zu finden und auszunutzen, deshalb existieren auch nur wenige Exploits. Allerdings kann man damit Abwehrmaßnahmen auf Systemen umgehen, die den Stack mit speziellen Programmen überwachen und schützen, um zum Beispiel Buffer-Overflows ins Leere laufen zu lassen. Der Kreativität der Angreifer ist offenbar keine Grenze gesetzt. Auch das Appellieren an Entwickler sichere Programme zu schreiben, trägt keine Früchte. Der Anwender ist daher gezwungen seine Systeme selbst zu schützen. Wie das aussehen kann und welche Maßnahmen man ergreifen kann, wird in einem Folgeartikel erklärt.
Literatur
[1] Smashing the Stack for Fun and Profit, Aleph One
[2] Buffer Overflows und Format Strings, Linuxfocus.org
[3] FAQ über BufferOverflows, GCF
[4] Tutorial über Format Strings, Team Teso
[5] Paper über Format Strings, Avaya Labs
[6] Tutorial über Heap Overflows, w00w00 (dab)
