

Eingelocht
Fast täglich tauchen neue Einbruchsmöglichkeiten und Verwundbarkeiten in Applikationen oder Betriebssystemen auf. In vielen Fällen ist die Ursache ein Buffer-Overflow, zu Deutsch Pufferüberlauf.
- Stephan Kallnik
- Daniel Pape
- Daniel Schröter
- Stefan Strobel
- Daniel Bachfeld
Verfolgt man Berichte über Sicherheitslöcher in Software, könnte man glauben, dass es kaum ein Programm gibt, welches nicht durch einen Buffer-Overflow angreifbar ist. Kein Betriebssystem, kein Server und keine Applikation bleibt verschont von möglichen Schwachstellen, die durch Pufferüberläufe verursacht werden, selbst Firewalls sind betroffen. Das Hintergrundwissen, um Meldungen über Buffer-Overflows besser verstehen zu können und was man damit alles anstellen kann, liefert dieser Artikel.
Jedes Programm legt zur Laufzeit lokale Variablen, Übergabeparameter für Funktionen sowie Rücksprungadressen für Unterprogramme im Arbeitsspeicher, genauer auf dem Stack, ab. Dort sind sie vor ungewollten Änderungen nicht geschützt. Kopiert ein Programm eine Zeichenkette in eine lokale Puffervariable, so kann es zu einem Buffer-Overflow kommen, wenn die Zeichenkette größer als erwartet ist. Variablen und unter Umständen auch die Rücksprungadresse werden überschrieben. Meist geschieht dies bei Programmen in Verbindung mit Zeichenketten, insbesondere bei Programmen die in C geschrieben sind. C kennt keine Strings, deshalb werden Zeichenketten als eindimensionale Felder (Arrays) angelegt. Viele C-Funktionen kopieren Daten in solche Arrays -- ohne zuvor zu prüfen, ob diese dort hineinpassen. Dies hätte ein Programmierer eigentlich mit einer entsprechenden Abfrage sicherstellen müssen. Die Programmiersprache Java kennt dieses Problem nicht. Zeichenketten werden als Strings behandelt und der Puffer wird dynamisch angepasst.
Meist führt ein Buffer-Overflow zum Absturz des betroffenen Programms, weil Variablen unsinnige Werte enthalten oder die Rücksprungadresse ins Nirvana zeigt und einen Speicherzugriffsfehler provoziert. Gelingt es einem Angreifer aber, sinnvollen Code in den Stack zu schreiben, kann er durch das richtige Setzen der Rücksprungadresse diesen Code anspringen lassen und ausführen. Der Code lässt sich zum Beispiel als Benutzereingabe eingeschleusen. Vorgefertigter Assembler-Code zum Öffnen einer Root-Shell auf einem beliebigen TCP-Port passt in 200 Bytes und ist im Internet mittlerweile frei verfügbar.
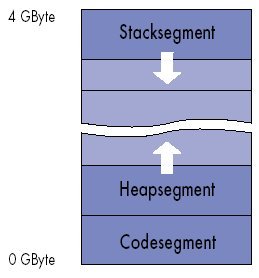
Bei modernen Betriebssystemen arbeitet jedes Programm in einem eigenen, virtuellen Adressraum, dessen Adressen die Hardware -- konkret die Memory Management Unit (MMU) -- erst bei Bedarf physikalischen Speicher zuordnet. Im virtuellen Speicher legt das Betriebssystem beim Start eines Programms drei Segmente an: das Code-Segment, das Daten-Segment (auch Heap genannt) und das Stack-Segment. Das Stack-Segment ist ein Zwischenspeicher für lokale Variable und gesicherte Prozessorregister, die das Programm zu einem späteren Zeitpunkt wieder benötigt. Der Stack beginnt am oberen Ende des Adressraums und wächst nach unten. Er funktioniert als Last-in-first-out-Puffer, den man erst abräumen muss, bevor man an früher abgelegte Daten kommt. Der Stack Pointer (ESP) markiert das Ende des Stacks und zeigt damit immer auf den letzten Eintrag.
C-Programme legen die Übergabeparameter einer Funktion, die Rücksprungadresse und lokale Variable auf dem Stack ab. Auf die lokalen Variablen greift die Funktion über einen Offset zum so genannten Base Pointer (EBP) zu, der auf ihren Datenbereich zeigt. Die beiden Basisoperationen für den Stack sind push und pop: push schreibt ein Register in den Stack und erniedrigt den ESP, pop liest es vom Stack und erhöht den ESP. Der Befehl RET in einer Unterfunktion lädt den Instruction Pointer (EIP) mit der Rücksprungadresse und springt damit zurück in das Hauptprogramm.
