

Formel M1: Warum der Apple-Chip so schnell ist
Vor allem eine clevere Cache-Hierarchie verhilft Apples ARM-Chips zu einer Leistung, die AMD und Intel bei kompakten Geräten bisher nicht erreichen.

(Bild: Quality Stock Arts, stock.adobe.com; Apple; Bearbeitung: Mac & i)
Seit November 2020 werden MacBook Air, MacBook Pro und Mac mini mit Apples selbst entwickeltem M1-Chip ausgeliefert. Aber warum fällt die Performance so viel höher aus als bei den jeweiligen Vorgängern mit Intel-Prozessoren? Die bei Apple übliche Antwort lautet natürlich: Durch die perfekte Abstimmung von Hard- und Software. Erstmals hat das Unternehmen bis auf ein paar Schnittstellenbausteine das komplette System in eigener Hand. Aber damit ein optimiertes macOS auch fix arbeiten kann, muss die Hardware, auf der es läuft, ebenfalls entsprechend leistungsfähig sein.
Computer im Baustein
Die besteht im Falle des M1 aus einem System-on-Chip (SoC), also einem nahezu vollständigen Computer auf nur einem Baustein. Möglich wurde das, weil Apple seit 30 Jahren konsequent darauf hingearbeitet hat: Tatsächlich war das Unternehmen 1990 einer der ersten Investoren bei Advanced RISC Machines Ltd, und setzte deren ARM-Architektur – auf welcher der M1 basiert – später bei Newton, iPod und allen weiteren Handhelds ein.

Zum großen Erfolg entwickelte sich ARM für Apple erst mit dem iPhone 2007. 2012 vollzog man den logisch nächsten Schritt: Als eines der wenigen Unternehmen erwarb Apple eine Architekturlizenz und darf seitdem auch Änderungen an den Rechenwerken und der Gesamtstruktur der Prozessoren vornehmen. Vor allem Letzteres ist nun mit dem M1 passiert, denn das Cache-System geht über das hinaus, was andere mobile ARM-Chips bieten.
- Das Zusammenspiel von Performance- und Efficiency-Kernen sorgt für hohe Leistung und geringen Energieverbrauch.
- Das Cache-System des M1 geht über andere Apple-SoC und x86-Prozessoren weit hinaus.
- Fabric-Verbund und System Level Cache harmonieren mit Unified Memory in Speicherchips auf dem Prozessorträger und Flash-Bausteinen ohne PCIe.
Schon von außen ist der M1 anders als die meisten aktuellen SoCs für Notebooks, es handelt sich um ein System-in-Package (SiP). Der Chip selbst sitzt auf einem Substrat, und auf diesem befinden sich zwei herkömmliche Speicherchips in ihrem eigenen Package. Das ist sehr kompakt, aber absolut nicht erweiterbar und auch etwas aufwendiger zu kühlen als bei externem RAM. SiPs sind seit über 20 Jahren unter anderem bei Grafikkarten immer mal wieder in Mode, Apple traut sich nun aber, auch bei seinen Geräten die Erweiterbarkeit für Vorteile bei der Leistung durch kurze Leiterbahnen und kompakte Bauformen zu opfern.
Die sieht übrigens so aus, als gäbe es nur einen halben Heatspreader; die Lösung erweist sich aber als durchdacht: Das M1-Die sitzt links auf dem Package und ist vollständig vom Heatspreader bedeckt. Die beiden weniger heiß werdenden RAM-Chips von Hynix sind direkt mit dem Kühlkörper verbunden. Ein vollflächiger Heatspreader, der auch das RAM bedeckt, hätte für dieses eine weitere Schicht erfordert, was die Kühlung verschlechtern würde.


Firestorm und Icestorm als ungleiche Motoren
Wie schon bei den letzten SoCs der A-Reihe gibt es auch im M1 zwei Klassen von ARM-Kernen: Die besonders schnellen namens Firestorm mit bis zu 3,2 GHz Taktfrequenz und besonders sparsame namens Icestorm mit bis zu 2,1 GHz. Intern nennt Apple das auch P- und E-Cores für Performance und Efficiency. Gegenüber dem A14 Bionic aus dem iPhone 12 sind das doppelt so viele Firestorms (4 statt 2) und ein leicht von 3 GHz aus gesteigerter Takt. Über die genaue Ausgestaltung der Rechenwerke schweigt sich Apple aus.
Videos by heise
Weil iOS-Apps binärkompatibel sind, lässt sich vermuten, dass der volle 64-Bit-Befehlssatz von ARMv8-A aktiv ist. Alle Cores können gemeinsam arbeiten, beim M1 handelt es sich also um einen mobilen 8-Kern-Prozessor. Mit einer gesamten Leistungsaufnahme der Rechenkerne von rund 20 Watt gibt es das in der x86-Welt bisher nur beim AMD Ryzen 7 4000U. Welcher Kern welche Aufgaben übernimmt, entscheidet übrigens macOS. Bisherige Experimente von Entwicklern zeigen, dass die Lastverteilung von Hand wohl gar nicht oder nur sehr umständlich möglich ist.

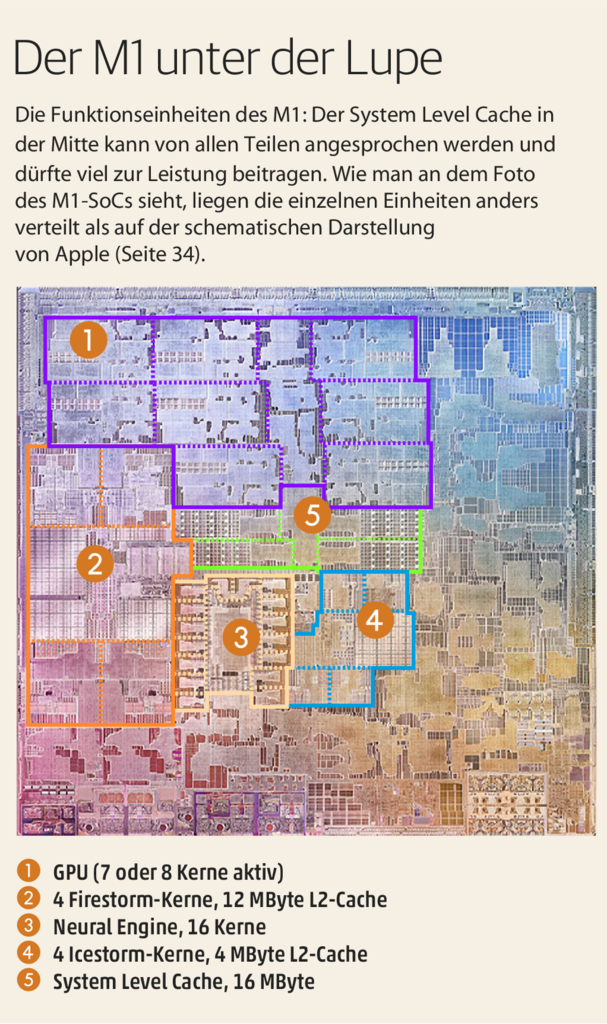
Recht groß sind die schnellsten Zwischenspeicher, die dedizierten L1-Caches pro Core. Firestorm kommt auf 192 KByte für Befehle und 128 KByte für Daten, Icestorm noch auf 128 und 64 KByte. Die L2-Caches dagegen fallen für ein Mobil-SoC geradezu riesig aus: 12 MByte besitzen die Firestorms, 4 die Icestorms. Dazu kommt noch ein System Level Cache (SLC) von offenbar 16 MByte, auf den wir gleich noch näher eingehen. Wenn man ihn als L3-Cache betrachtet, gibt es für die Kerne im M1 zusammen mit den L2-Speichern ganze 32 MByte Cache. Intel kann da nur bei Serverprozessoren mithalten, lediglich AMD baut in die Desktop-Prozessoren Ryzen 5000 mit 64 MByte noch mehr Cache ein.
Bei all dem fallen die Laufzeiten hervorragend aus: Bei leichter Last läuft das MacBook Air über 21 Stunden und beim Videoabspielen bringt es das MacBook Pro auf 13 Stunden. Der Pro-Vorgänger mit Intel-CPU schafft hier nur 7,5 Stunden bei gleich hell eingestelltem Display. Dahinter steckt kein Geheimnis, sondern schlicht die Grundeigenschaft von ARM-CPUs- und Handheld-GPUs: Sie brauchen beim Nichtstun nahezu keinerlei Energie. Seitenblick aufs iPhone: Wenn es nicht genutzt wird und keine sich selbst updatenden Apps laufen, kann es tagelang durchhalten. Ein Intel-Notebook schafft das mit einem vergleichsweise dicken Akku nicht einmal im Energiesparmodus (ACPI S3), aus dem es erst einige Sekunden aufwachen muss.
Wenn, um im Beispiel zu bleiben, auch nur 50 mal pro Sekunde ein Bild dekodiert und in den Framebuffer transportiert werden muss, können sich die Cores milliardenfach schlafen legen. Den Großteil der Arbeit erledigen dabei die Videoeinheiten des SoC, bei deren Betrieb die acht Cores sich weitgehend abschalten können. Hier hat Apple durch iPhone und iPad große Erfahrung.
Zudem kann macOS bei solch einfachen Aufgaben darauf achten, nur die sparsamen Icestorm-Kerne zu verwenden. Das klappt bei Intel zwar auch mit dem Core i5-L16G7 alias Lakefield, hier gibt es aber nur einen schnellen Sunny-Cove-Kern und vier einzeln sehr langsame Atom-Cores, nicht 4+4 Cores wie beim M1. Zudem ist dieser Chip erst seit Mitte 2020 lieferbar, da war Apples M1 längst fertig. Intel hätte diese Idee schon Jahre früher energisch verfolgen und zudem seine 10-Nanometer-Fertigung in den Griff bekommen müssen – darauf basieren die Lakefields – um Apple zum Bleiben zu überzeugen.
Caches, GPU, RAM und Unified Memory
Caches bringen die Leistung auf die Straße
Hinter den für ARM-Chips riesigen Caches steckt eine bewusste Designentscheidung: Man baut so große Areale aus statischem Speicher (SRAM) nur, wenn man sie wirklich benötigt. Schließlich belegen sie viel Platz auf einem Chip. So umfasst beispielsweise bei den ebenfalls neuen SoCs von Xbox Series S/X der L3-Cache nur 4 MByte, bei den Spielmaschinen kommt einer großen GPU mehr Bedeutung zu als einer besonders hohen CPU-Leistung.
Gerade bei einem RISC-Prozessor mit weniger hinterlegten Befehlsroutinen wie dem M1 bieten sich große Caches aber an, um die Ausführungseinheiten ständig zu füttern. Zwar kann ARM-Code (RISC) bei einfachen Algorithmen wie kleinen Schleifen sehr viel kompakter sein als Intel-Code (CISC), bei komplexen Aufgaben verkehrt sich der Vorteil des reduzierten Befehlssatzes aber ins Gegenteil: Die Programme nehmen im Speicher oft recht viel Platz ein.
Dass Apple im M1 im Unterschied zum A14 die Caches so groß macht, liegt an deren Stromhunger, wenn dauernd gelesen und geschrieben wird. Das Energiebudget fällt bei MacBook und Mac mini viel höher aus als bei einem iPhone oder iPad. Die großen Caches bieten zudem einen Vorteil bei der Emulation durch Rosetta 2, bei der x86-Programme in nativen ARM-Code übersetzt werden. Das geschieht weitgehend schon bei der Installation oder beim ersten Start der Programme. Apple weist aber in seinen Entwicklerunterlagen darauf hin, dass Teile des Codes zur Laufzeit übersetzt werden müssen – ganz wie ein Just-in-Time-Compiler (JIT). Für solche Umsetzungen, die fortlaufend arbeiten, nützen große Caches sehr viel.
Dazu kommt noch der von Apple nicht näher beschriebene System Level Cache. In bisherigen Designs würde man ihn als L3-Cache ansehen, die Benennung als SLC und seine Platzierung in der Mitte des Dies legen aber eine erweiterte Funktionsweise nahe: Er dient höchstwahrscheinlich als Direktverbindung zwischen allen Funktionseinheiten einschließlich der Neural Engine. Wenn beispielsweise ein Grafikelement von der CPU geändert wird, kann die GPU die neuen Daten zur Anzeige direkt aus dem SLC holen, ohne den viel langsameren Weg über das RAM zu gehen.
Ähnliche Mechanismen wurden früher schon, etwa beim Alpha-Prozessor von DEC, unter dem Namen Crossbar verwendet, erwiesen sich aber mit damaligen Fertigungstechniken nur als schlecht realisierbar und stromhungrig. Apple hat das offenbar erstmals richtig hinbekommen, denn einen reinen L3-Cache haben die eigenen A-SoCs nicht zu bieten.
Die ganzen Caches kann man sich in Cupertino nur leisten, weil der M1 im 5-Nanometer-Prozess bei TSMC hergestellt wird – einem der aktuell modernsten Verfahren zur Halbleiterfertigung. Insgesamt befinden sich auf dem Die, ohne Einberechnung der RAM-Chips, ganze 16 Milliarden Transistoren. Selbst Nvidias aktuelle Oberklasse-GPU, die GA104-300 für die RTX 3070, besitzt mit 17,4 Milliarden kaum mehr. Apple hat hier also schon bei seinem ersten ARM-SoC für Macs sehr großen Aufwand betrieben.
GPU und RAM deutlich beschleunigt
Apple spricht bei seinen selbst entwickelten GPUs wie bei den CPUs von Cores. Das ist jedoch in der Branche unüblich. Besser vergleichbar wäre eine Angabe von Execution Units (EUs) oder der Zahl der Shader/ALUs als einzelne Rechenwerke. Immerhin existieren konkrete Angaben zur Zahl der Cores, die sich auf acht gegenüber den vieren des A14 verdoppelt hat. Die theoretische Rechenleistung gibt Apple mit 2,6 Teraflops an, was für eine der schnellsten integrierten GPUs in Mobilrechnern spricht. Unsere Benchmarks mit Spielen, selbst in der Rosetta-2-Emulation, belegen das.
Die GPUs des M1 von MacBook Pro und Mac mini sind identisch, bei der günstigeren der beiden MacBook-Air-Konfigurationen hat Apple nur sieben der physikalisch vorhandenen acht GPU-Cores aktiviert, was die Leistungsaufnahme und damit die Wärmeentwicklung in dem lüfterlosen System etwas reduziert.
Bei einem SoC mit integrierter Grafik hängt die Leistung stark vom RAM ab – und auch hier wurde geklotzt, nicht gekleckert: Die LPDDR4X-Chips von Hynix sind über acht Speicherkanäle auf dem M1-Die angebunden und arbeiten mit effektiv 4266 MHz. So hohe Takte sind abseits von gesteckten und sehr teuren Übertakter-Modulen nur mit extrem kurzen Anbindungen zu haben, wohl auch darum sitzen sie auf dem M1-Package. Die theoretische Bandbreite der Bausteine erreichen sie laut synthetischen Tests von Anandtech auch beinahe: Gelesen wird mit fast 60 GByte pro Sekunde, geschrieben mit bis zu 36 GByte/s. Kopien innerhalb des Speichers erfolgen mit bis zu 62 GByte/s. Solche Werte bieten vergleichbare x86-Chips wie AMDs Ryzen 4000 oder Intels Tiger Lake bisher nicht. Wie schon bei den Caches war hohe Bandbreite also Apples Designziel.
Unified Memory für alle Einheiten
Das Unternehmen stellt für den M1 auch das Unified Memory heraus, ein gemeinsamer Speicher für CPU, GPU und alle Einheiten auf dem SoC. Das boten die Intel-Chips mit integrierter Grafik auch schon in ähnlicher Form, allein die wahrscheinliche Funktionsweise des SLC könnte hier etwas Neues bringen – das ist jedoch bisher noch nicht erforscht.
Möglicherweise hat Apple auch durch den System Level Cache einen gewissen Grad der Kohärenz des RAM – nicht nur der Caches – für verschiedene Speicherbereiche erzielt. Sichtbar werden solche Vorteile aber erst durch genau dafür optimierte Software. An der mangelt es noch, da ja auch das Entwicklerkit im Mac-mini-Gehäuse nur mit dem A12Z bestückt war, der diese Funktionen nicht bietet.
Das gilt auch für die in jedem M1 vorhandene Neural Engine aus 16 Kernen, die das Inferencing bei maschinellem Lernen alias KI beschleunigen soll. Bisher konnte man allenfalls die GPU für solche Aufgaben heranziehen, was aber bei vielen Anwendungen um Größenordnungen langsamer ist.
Apple Fabric, Ausblick auf M2
SSD per Fabric, Thunderbolt mit Intel
Dass Apple nicht nur die Intel-Kerne durch ARM-Cores ersetzt hat, zeigt sich an einem Detail deutlich: Der bisherige T2-Controller fehlt – er war unter anderem für die Anbindung der SSD zuständig. Die hängt nun direkt am Apple Fabric. Die deutsche Übersetzung der Herstellerbezeichnung gibt die Bauweise gut wieder: Es handelt sich um ein Gewebe. Wie bei mehreren übereinander liegenden karierten Blättern eines Notizblocks liegen Schichten aus horizontalen und vertikalen Leiterbahnen in den Silizium-Layers des M1 aufeinander. Sie verbinden alle Einheiten des SoC, und daran hängen nun auch die Flash-Bausteine der SSD. PCIe bedient bei M1-Macs nur noch Thunderbolt und das WLAN/Bluetooth-Modul.
Bei Thunderbolt kann Apple nicht ganz ohne Intel, denn die Technik gehört dem nun geschmähten Chiphersteller. Folglich gibt es zwei der Treiberbausteine JHL8040R von Intel. Es handelt sich um Retimer, welche die Signalintegrität bei langen Leiterbahnen vom eigentlichen Controller bis zu den Ports wiederherstellen. Und in der Tat sind beim neuen MacBook Pro der M1 und die Retimer an gegenüberliegenden Seiten des Logic Boards angebracht. Der Intel-Chip steht mit 2,40 US-Dollar in der Preisliste, ein bisschen Geld fließt also auch mit jedem M1-Mac noch an Intel.
Ausblick auf M2 und mehr
Schon im M1 stecken mit dem SLC und dem auch für die SSD genutzten Fabric Hinweise, wie Apple diese Plattform weiterentwickeln könnte. Die offensichtlichste Neuerung gegenüber dem A14 sind die vier statt zwei Firestorm-Kerne. Für einen iMac sollte sich das leicht nochmals verdoppeln lassen – gegebenenfalls unter Weglassen der Icestorm-Einheiten, denn die Leistungsaufnahme darf hier mehrfach so hoch sein wie bei den drei bisher verfügbaren Geräten MacBook Air, MacBook Pro und Mac mini.
(Bild: Apple, Bearbeitung: Mac & i, Quelle: AnandTech)
Neue M-SoCs wird Apple aber nur dann bringen, wenn TSMCs 5-Nanometer-Fertigung weiterhin problemlos läuft.
Aus dieser kann man allein durch mehr Erfahrung höhere Taktraten erwarten, die bisherigen maximal 3,2 GHz für die Firestorm-Cores sind da als recht konservativ anzusehen.
Bis Ende 2022 sollen alle Macs ausschließlich mit Apple Silicon laufen. Und was geschieht mit dem noch recht neuen Mac Pro? Zwar gibt es erste Gerüchte über einen Apple-Chip mit 32 Cores, aber gesteckte Grafikkarten und andere Beschleuniger sind hier Pflicht, und neue Karten erscheinen ebenso wie sehr schnelle M.2-SSDs nur noch mit PCI Express 4.0 (PCIe 4.0). Davon bräuchte ein Mac Pro mit Apple Silicon einige Dutzend Lanes mehr als der M1. Das bieten einige Großrechner auf ARM-Basis bereits heute.
Es erscheint zweifelhaft, dass Apple mit seinen eigenen GPUs die gerade erst vollzogenen Generationswechsel von AMD und Nvidia überbieten kann. Folglich ist das Bussystem und damit einhergehend die Erweiterung des Fabric sowie des SLC wohl die größte Herausforderung. Auf Software-Seite müssen ARM-Treiber für Radeon/FirePro und Geforce/Quadro her, was auch eGPUs für die mobilen Geräte ermöglichen könnte. Die Frage bleibt, ob Apple Letzteres auch wirklich will.
Zudem sind das ARM-macOS sowie die nativen Anwendungen noch so neu, dass schon die M1-Macs in den nächsten ein bis zwei Jahren allein durch Software-Optimierungen noch deutlich Tempo zulegen dürften. Mit der Freiheit der gesamten Plattform aus einer Hand hat sich Apple auch mehr Verantwortung aufgeladen. Aber selbst für Anwender, die keine Macs nutzen, ist das gut: AMD und Intel sind nun im Zugzwang, auch ihre Designs gründlich zu überdenken.
(lbe)
