

HTTP-Feeds: Asynchrone Schnittstellen ohne Kafka oder RabbitMQ
Für asynchrone Schnittstellen braucht es nicht immer Apache Kafka oder RabbitMQ. Sie lassen sich auch ohne Middleware einfach über HTTP-APIs gestalten.

(Bild: Bignai/Shutterstock.com)
- Jochen Christ
Um die Softwareentwicklung in mehreren Teams effizient und zielgerichtet durchzuführen, lassen sich Softwaresysteme durch Architekturkonzepte wie Microservices und Self-contained Systems entlang der fachlichen Grenzen in eigenständige Bereiche unterteilen. Im Zuge dieser Trennung entstehen Schnittstellen zwischen diesen Systemen, da der Zugriff auf Daten aus anderen Bereichen wie Bestellungen oder Kundendaten erforderlich ist und gegebenenfalls Nachfolgeaktionen wie Rechnungsstellung oder Reporting auszulösen sind.
Schnittstellen lassen sich synchron oder asynchron anlegen. Synchrone Schnittstellen sind entfernte Funktionsaufrufe, die zu einer Anfrage eine Antwort zurückgeben. Sie sind in der Regel zwar einfach zu implementieren, sollten in unternehmenskritischen Systemkomponenten jedoch besser nicht zum Einsatz kommen, da sich Verfügbarkeiten der beteiligten Systeme multiplizieren und die Latenzzeiten der Aufrufe addieren. So sollte beispielsweise die Verfügbarkeit eines Onlineshops möglichst nicht davon abhängen, ob das Finanzbuchhaltungssystem gerade durch ein Wartungsfenster blockiert ist. Im Gegenzug sollte ein Monatsabschluss der Finanzbuchhaltung auch den Onlineshop nicht durch massenhafte GET-Requests negativ beeinflussen.
Beispiel für einen synchronen GET-Aufruf einer HTTP-API:
GET /api/customers/387484543
200 Ok
{
"customerId": "387484543",
"firstname": "Alice",
"lastname": "Springs",
"email": "alice.springs@example.org",
"newsletter": true,
"termsAccepted": ["2018-01-01"],
"locked": false,
"created": "2018-04-12T12:13:58.876111Z",
"updated": "2021-09-29T11:44:46.254440Z"
}Um die beschriebenen Probleme zu verhindern, sollten Entwicklerinnen und Entwickler auf asynchrone Schnittstellen ausweichen. Traditionell kommen diese häufig im Rahmen der Batch-Verarbeitung zum Einsatz. Dabei wird beispielsweise ein Datei-Export nachts generiert und anderen Systemen anschließend auf einem File-Server zur Verfügung gestellt. Das Hauptproblem hierbei ist jedoch die Aktualität der Daten – niemand möchte mit veralteten Daten arbeiten.
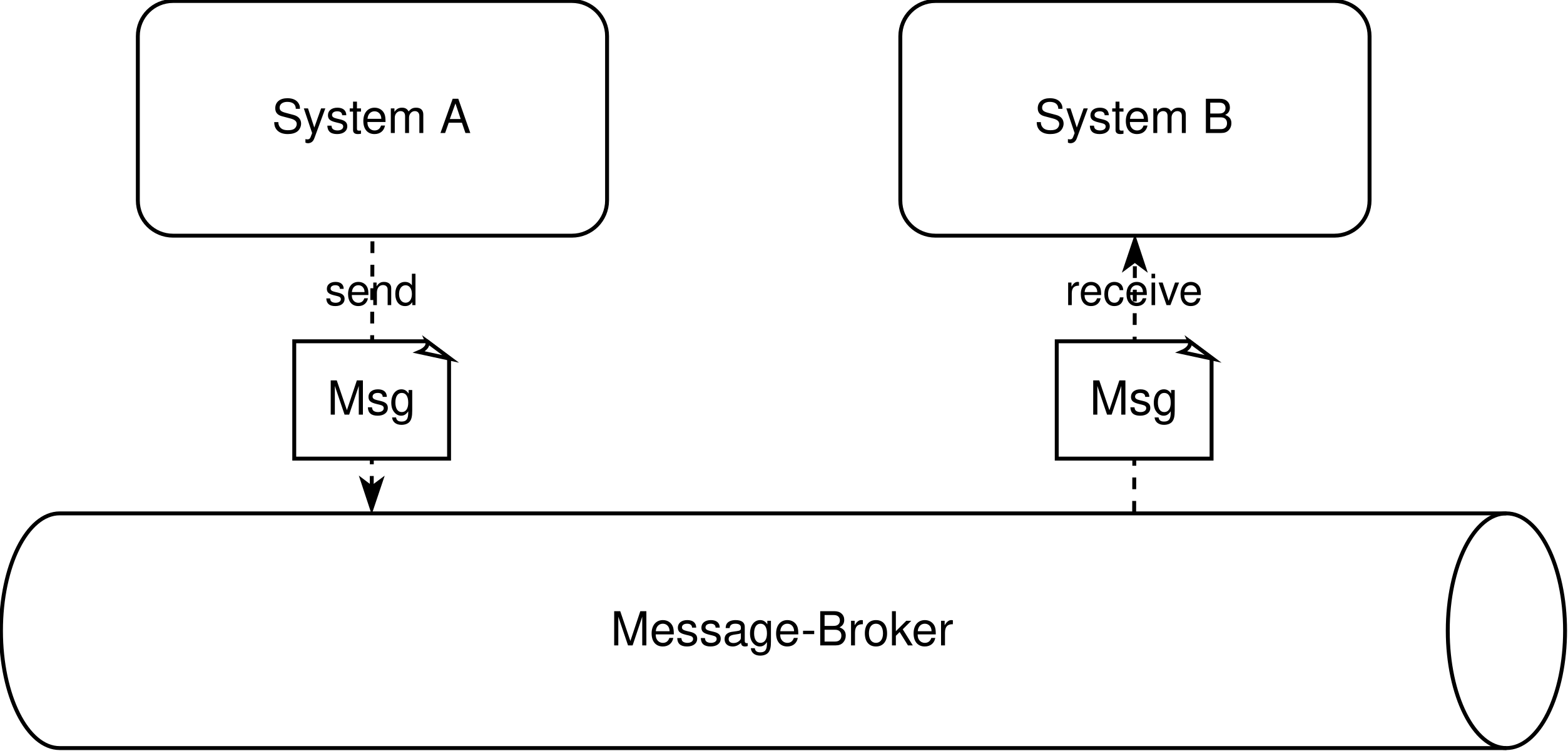
Um Daten auch asynchron nahezu in Echtzeit austauschen zu können, haben sich nachrichtenorientierte Broker-Systeme etabliert. Dabei schickt ein System eine Nachricht über ein Protokoll wie AMQP (Advanced Message Queuing Protocol) an ein Topic und ein registrierter Consumer verarbeitet sie, sobald er dafür bereit ist. Der Broker agiert als Middleware-System, das die Nachrichten zwischenspeichert und verwaltet. Typische Vertreter dieser Art von Middleware sind MQSeries, Apache Kafka und RabbitMQ, aber auch AWS SQS oder das in der Google Cloud verwendete Pub/Sub.
Middleware führt zu Abhängigkeiten
Der systemübergreifende Einsatz solcher Broker-Systeme als Schnittstellentechnologie führt in der Regel zu organisatorischen und technischen Abhängigkeiten. Unter anderem stellt sich die Frage nach der organisatorischen Verantwortung: Welches Team kümmert sich um den Betrieb dieses Systems mit Installation, Betrieb, Bereitschaft und Abstimmung von Versionsupdates? Und wer übernimmt die Kosten? Das betreffende Team ist zudem immer dann involviert, wenn es darum geht, neue Topics oder Berechtigungen einzurichten.
Die Wahl des Broker-Systems zieht auch technische Konsequenzen für die beteiligten Systeme nach sich. Alle Beteiligten müssen versionskompatible Client-Bibliotheken verwenden und es wird ein Serialisierungsformat vorgegeben, das beispielsweise im Falle von Avro oder Protobuf ein spezielles Schema-Management erfordert. Kommt es zu einem Fehler, wenn beispielsweise eine Nachricht nicht an den Broker zugestellt werden kann, hilft häufig nur eine aufwendige, teamübergreifende Fehleranalyse.
