

Kategorisieren mit Few Shot Learning: Die Macht der Wenigen
Seite 2: Mehr ist (fast) immer besser
Häufig können Data Scientists a priori nicht bestimmen, welche Kombinationen aus Pattern und Verbalizer für ein Modell und den zugehörigen Datensatz gut funktionieren. Daher setzt PET nicht nur auf ein Pattern Verbalizer Pair, sondern auf mehrere. Die Ergebnisse der unterschiedlichen Modelle kombiniert man ähnlich wie bei der Knowledge Distillation miteinander, indem man für jedes PVP ein Modell erstellt. Da nur ein kleiner Trainingsdatensatz erforderlich ist, dauert das Training nicht lange. Anschließend dienen die Modelle dazu, bisher nicht klassifizierte Daten zu labeln, um mehr Trainingsbeispiele zu erhalten. Dazu kombiniert man die Wahrscheinlichkeiten aller trainierten Modelle entweder einheitlich oder gewichtet nach der vorher gemessenen Genauigkeit der Modelle mit dem Trainingsdatensatz. Abschließend erfolgt das Feintuning des Modells mit den gelabelten Daten wie bei einer normalen Klassifikation.

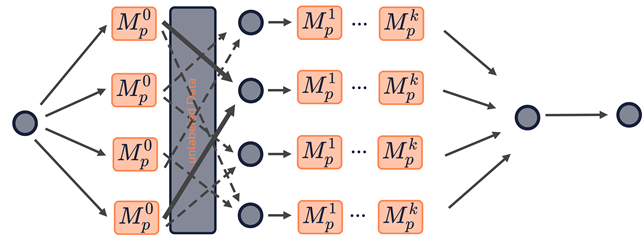
Das Vorgehen hat einen Nachteil: Wenn einzelne Modelle keine korrekten Ergebnisse liefern, können damit viele falsch gelabelte Daten in dem finalen Trainingsdatensatz landen. Daher optimiert der iPET-Ansatz (iterative Pattern Exploiting Training) das Verfahren, indem er Modelle in weiteren Iterationsschleifen trainiert, die hier Generationen heißen. Die Idee dahinter ist, dass eine Generation von Modellen nur von einem Teil der vorherigen Modelle lernt und somit Fehler im Trainingsdatensatz weniger ins Gewicht fallen.
Im Detail funktioniert das Vorgehen folgendermaßen: Man erstellt die erste Generation, indem man jedes Modell mit einem eigenen Pattern Verbalizer Pair mit dem manuell gelabelten Trainingsdatensatz trainiert. Die daraus resultierenden Modelle labeln nun einen Teil des originalen (ungelabelten) Datensatzes.
In der nachfolgenden Generation folgt das erneute Training mit den jeweiligen PVPs, aber mit dem erweiterten Datensatz. Dieser enthält nun zusätzlich die von der vorherigen Generation gelabelten Daten. Allerdings verwendet man dabei nicht wie bei PET die gelabelten Daten aller Modelle, sondern nur von einem Teil. Jeder Trainingsdatensatz wird somit von einer anderen Teilmenge von Modellen der vorherigen Generation erstellt, sodass in der aktuellen Generation jedes Modell mit potenziell unterschiedlichen Daten trainiert wird. Nach einer bestimmten Anzahl Generationen folgt abschließend das gewichtete Labeln eines Datensatzes aus allen Modellen, der schließlich dazu dient, das Modell wie bei PET feinzutunen.
Eine weitere Ergänzung zu PET ist ADAPET. Dabei fügt man weitere Trainingsziele hinzu, um mehr Kontext zu erzeugen und damit das Ergebnis zu verbessern.
PET und iPET berücksichtigen bei ihrem Training lediglich die Token, die in den PVPs vorhanden sind. Die anderen Token des Vokabulars lassen sie außer Acht. ADAPET berücksichtigt hingegen die Wahrscheinlichkeiten aller Token. Dadurch beeinflussen andere Wörter das Ergebnis ebenfalls. Die binäre Kreuzentropie kann als Verlustfunktion dazu dienen, das Modell für ein falsches Token zu "bestrafen". Dieser Loss kommt häufig für binäre Klassifikationsprobleme zum Einsatz.
Die zweite Erweiterung kehrt die Fragestellung von PET um: Während Letzteres nach einer bestimmten Lücke im Text fragt, erweitert ADAPET das Konzept um die umgedrehte Frage: Welcher Kontext passt zu einem Token? Anders ausgedrückt: Wie lautet die Frage zu der gegebenen Antwort? Während des Trainings werden zusätzlich einzelne Wörter des Textes maskiert. Ist die Klassifizierung des Modells korrekt, muss es die maskierten Wörter fehlerfrei vorhersagen. Liegt es jedoch falsch, soll es die falschen Token angeben.
Überzeugende Ergebnisse
Die vom Autor ausgewerteten Ergebnisse zeigen, dass sowohl iPET als auch ADAPET bei den Benchmarks besser abschneiden als GPT-3. Evaluiert hat er sie mit unterschiedlichen NLP-typischen Aufgaben wie Textklassifikation, aber auch das Extrahieren relevanter Informationen aus einem Satz. Der Benchmark SuperGLUE fasst die Aufgaben zusammen.
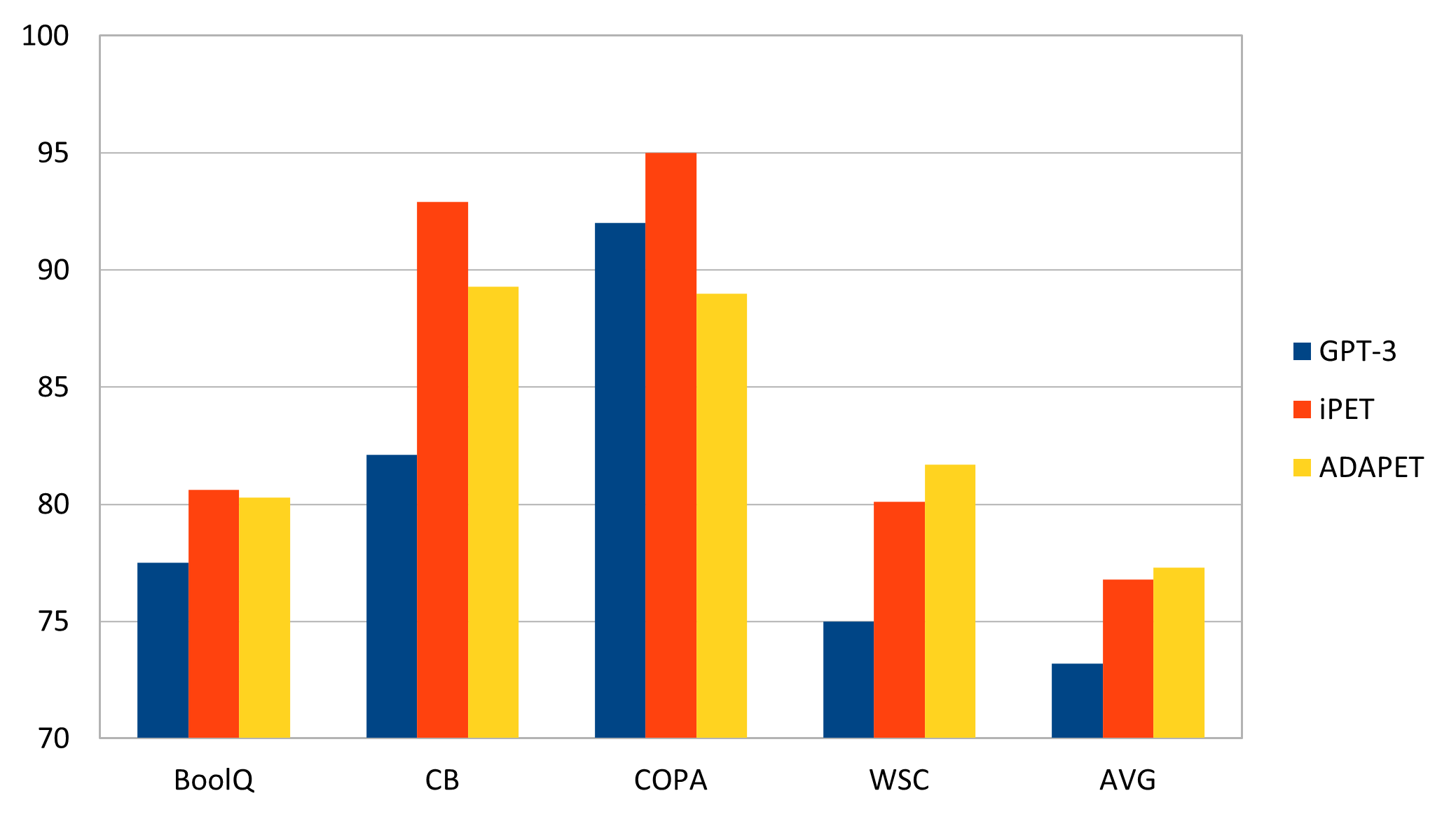
Das darunterliegende Modell hat bedeutend weniger Parameter als GPT-3 – 355 Millionen statt 175 Milliarden –, was den mit dem Training verbundenen Zeit- und Kostenaufwand erheblich reduziert. Da die Modelle über Hugging Face verfügbar sind, können Unternehmen sie im eigenen Rechenzentrum betreiben und müssen nicht für den Zugriff auf eine API bezahlen.
