Nachhaltige Softwarebereitstellung in Kubernetes

(Bild: iX)
Serverless Deployments mit Knative ermöglichen einen bedarfsgerechten, nachhaltigen Softwarebetrieb. Eine Migration ist herausfordernd, aber gut machbar.
Nachhaltigkeit in der Softwareentwicklung wird immer wichtiger – insbesondere im Kontext der Anwendungsbereitstellung in der Cloud. Steigende Energiepreise motivieren immer mehr Unternehmen, über nachhaltigere Softwarearchitektur nachzudenken und ihre auf Computing zurückzuführenden CO2-Emissionen detaillierter zu überwachen.
Im Cloud-Native-Umfeld gibt es immer mehr Werkzeuge und Methoden, um beispielsweise die Nachhaltigkeit einer Software durch nachfrageorientierte, bedarfsgerechte Skalierung zu verbessern. Der Artikel zeigt anhand eines konkreten Fallbeispiels, wie Entwicklerinnen und Entwickler mithilfe der Open-Source-Software Knative [1] eine containerisierte Anwendung in Kubernetes in einen dynamisch skalierbaren Serverless-Dienst überführen können, der sich in Zeiten fehlender Nachfrage sogar komplett abschaltet.
Bedarfsgerecht skalieren für mehr Nachhaltigkeit
Knative basiert auf Kubernetes, das sich als Rückgrat moderner containerisierter Anwendungslandschaften etabliert hat. Kubernetes bietet viele Möglichkeiten zum Automatisieren der Bereitstellung, Skalierung und Verwaltung von Containeranwendungen. Trotz seiner Flexibilität fehlt Kubernetes jedoch die Fähigkeit, Serverless-Anwendungen bereitzustellen. Unter anderem erachtet die Green Software Foundation das zugrunde liegende Bereitstellungsmuster als nachhaltig, bei dem Anwendungen sich basierend auf der aktuellen Nachfrage skalieren und gegebenenfalls auch komplett abschalten lassen.
Soll eine einfache Beispielanwendung aus einem standardmäßigen Kubernetes-Deployment in einen Knative-Service migriert werden, gilt es, die folgenden Qualitätskriterien zu berücksichtigen:
- Die Migration sollte möglichst wenige Anpassungen am Quellcode erfordern. Nur dadurch lässt sich sicherstellen, dass sich größere Anwendungen einfach migrieren lassen, ohne zu hohe Kosten für einen Umbau der Anwendungslandschaft zu verursachen.
- Die in der existierenden Anwendungsumgebung etablierte Praxis für Logging, Monitoring und Tracing sollte weiterhin nutzbar sein. Um eine einfache Migration zu ermöglichen, ist es daher notwendig, die Kompatibilität von Knative mit den vorhandenen Tools sicherzustellen. Das im Folgenden skizzierte Beispiel baut daher auf der weit verbreiteten Monitoringsoftware Prometheus auf.
- Existierende Endpunkte der Beispielanwendung sollen mit Knative nach der Migration unter denselben Routen verfügbar sein. In größeren Anwendungslandschaften sind Routen häufig statische Adressen der Services. Wenn nach einer Migration ein Service plötzlich unter einer anderen URL verfügbar ist, kann dies Probleme verursachen, insbesondere wenn die Kommunikation nicht über ein API-Gateway oder eine Service-Registry entkoppelt ist.
- Das Lastmuster der Beispielanwendung muss längere Zeiträume ausweisen, in denen der Service nicht aufgerufen wird, es also keine Zugriffe durch Nutzerinnen und Nutzer gibt. Nur führt das Herunterskalieren der Anwendung auf null Replikas zu einem nennenswerten Ressourcengewinn.
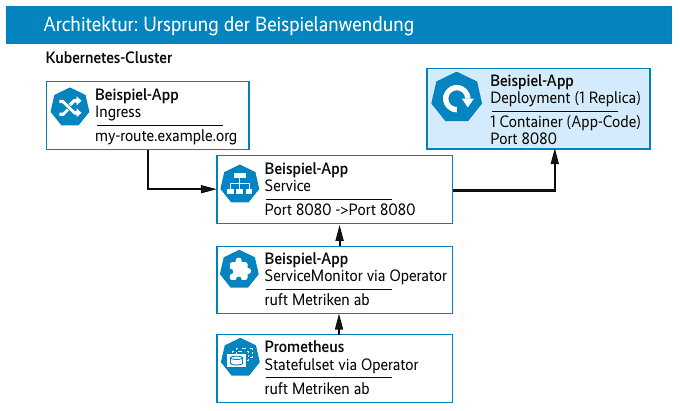
Die zu migrierende Beispielapplikation besteht aus einem einfachen, zustandslosen Kubernetes-Deployment, das eine REST API über einen Ingress bereitstellt. Der Prometheus-Operator soll die Metriken zur Überwachung der Applikation über die Kubernetes Custom Resource ServiceMonitor erfassen – wie Abbildung 1 verdeutlicht.

Knative: Serverless-Dienste in Kubernetes
Das Open-Source-Projekt Knative zielt darauf ab, Serverless Workloads in Kubernetes auszuführen und zu verwalten. Dazu stellt es Funktionen für die automatische Skalierung bereit – bis hin zu der Fähigkeit, Anwendungen auf null Pods herunterzuskalieren, um den Leerlauf von Pods zu vermeiden. Auch wenn die Ersparnisse pro Anwendung klein sein mögen, summiert sich der Effekt über Tausende von Pods und eine Vielzahl von Anwendungen gerade in großen Clustern. Dabei ist zu beachten, dass Knative nur mit zustandslosen Anwendungen umgehen kann, die ausschließlich über HTTP kommunizieren.

Wie Observability, Platform Engineering und andere neue Ansätze Entwicklerinnen und Entwicklern über den gesamten Software Development Lifecycle hinweg zu produktiverem Arbeiten verhelfen, zeigen die Artikel des neuen Sonderheftes iX Developer "Cloud Native" [2].
Um eine Serverless-Laufzeitumgebung innerhalb eines Kubernetes-Clusters zu schaffen, müssen mehrere Komponenten von Knative Serving zusammenarbeiten. Dazu zählen insbesondere Service, Route und Revision:
- Service: Ein Knative-Service definiert eine Serverless-Anwendung und ist daher nicht mit einem Service in Kubernetes zu verwechseln. Beim Anlegen eines Knative-Services wird automatisch eine Route und eine Konfiguration erstellt.
- Route: Sie bestimmt, wie Anfragen an die verschiedenen Revisionen einer Anwendung geleitet werden. Es lässt sich beispielsweise festlegen, dass 90 Prozent der Anfragen an die aktuelle Version der Anwendung und die restlichen 10 Prozent an eine neue Version fließen sollen.
- Revision: Bei jeder Änderung am Knative-Service erstellt Knative eine neue Revision. Jede Revision repräsentiert einen Snapshot des Codes und der zugehörigen Konfiguration.
Migration und Herausforderungen
Die Serverless-Migration erscheint auf den ersten Blick simpel, gilt es doch lediglich, das existierende Deployment in einen Knative-Service zu überführen, den der Knative Serving Operator dann zur Laufzeit in ein Kubernetes-Deployment umwandelt. Hinzu kommen schließlich noch verschiedene Kubernetes-Dienste sowie eine – automatisch erstellte – Ingress-Ressource. Der bereitgestellte Service skaliert nun basierend auf den tatsächlichen Anfragen und schaltet sich vollständig ab, falls Anfragen ausbleiben – in der Standardeinstellung bereits nach 30 Sekunden. Damit wäre die Migration abgeschlossen, sofern man die oben genannten Qualitätskriterien unberücksichtigt ließe. Will man sie hingegen erfüllen, ergeben sich noch einige Herausforderungen.
- Abruf der Applikationsmetriken durch Prometheus: In der Standardkonfiguration sammelt der Knative-Service keine Metriken von Prometheus. Soll er die Daten abrufen, ist dafür ein Start der Applikation erforderlich, da Prometheus die Metriken stets über einen Pull-basierten Ansatz abruft. Prometheus ist standardmäßig darauf ausgelegt, in regelmäßigen Abständen die Metriken der Ziel-Applikationen über einen eigens dafür vorgesehenen Endpunkt abzurufen, zu speichern und für weitere Auswertungen bereitzustellen. Für dauerhaft aktive Anwendungen ist das sinnvoll, aber es würde die angestrebte Nachhaltigkeit bei Serverless-Applikationen konterkarieren.
- Verfügbarkeit des Service unter einem dedizierten Endpunkt: Der Endpunkt, unter dem der Knative-Service bereitstehen soll, lässt sich in der Regel nicht frei festlegen. In der Standardkonfiguration wird der Service immer nach dem folgenden Schema außerhalb des Clusters verfügbar gemacht:
<Service Name>.<ServiceNamespace>.<Cluster Url>Dazu generiert Knative aus der Knative-Service-Definition automatisch Ingress- und Kubernetes-Service-Ressourcen. Daher lässt sich das Schema zwar anpassen, der tatsächliche Endpunkt eines einzelnen Service aber nicht frei bestimmen. - Dynamisches Hochskalieren der Anwendung: Auch das dynamische Hochskalieren einer Serverless-Anwendung aus dem ausgeschalteten Zustand heraus kann Probleme verursachen. Muss eine Anwendung erst noch starten, bevor sie auf eine Anfrage reagieren kann, dauert das Beantworten mindestens so lange wie der Applikationsstart. Dieser Kaltstart dauert je nach verwendeter Programmiersprache und Framework von wenigen Millisekunden bis zu mehreren zehn Sekunden. Die Beispielanwendung ist mit Spring Boot und Java 20 entwickelt. Sie benötigt ohne Optimierungen zwischen einer und zehn Sekunden, bis sie Anfragen beantworten kann – je nachdem, wie viel CPU-Leistung ihr zur Verfügung steht. Für die meisten Anwendungsfälle ist eine Antwortzeit von zehn Sekunden bereits inakzeptabel, etwa wenn Nutzerinnen oder Nutzer eine Anwendung über einen Webbrowser aufrufen.
Herausforderungen meistern
Für die im Zusammenhang mit den definierten Qualitätskriterien auftretenden Probleme gibt es Lösungsansätze. Das Abrufen der Anwendungsmetriken lässt sich sogar auf zwei unterschiedlichen Wegen umsetzen.
Bei einem Pull-basierten Ansatz muss sichergestellt sein, dass ein Abrufen der Metriken nicht zu unnötigen Applikationsstarts führt, wenn die Applikation gerade ruht. Andererseits darf das Abrufen der Metriken nicht dauerhaft verhindern, dass Knative die Anwendung herunterskaliert. Beides lässt sich durch eine geeignete Porttrennung erreichen. Beim Start eines Pods öffnet Knative mehrere Ports in einem separaten Container, dem Queue-Proxy. Knative nutzt diese Ports, um Anfragen an die eigentliche Applikation zu leiten. Hierbei bleibt der durch den Applikationscode geöffnete Port bestehen. Ist eine Anfrage direkt an den Applikations-Port gerichtet, ignoriert Knative diese für die Skalierung.
Beim Monitoring von Knative-Applikationen können Metriken verloren gehen, die zwischen dem letzten Abruf durch Prometheus und dem Skalieren der Applikation auf null geschrieben wurden. Abhängig vom Anwendungsfall kann dieser Verlust verkraftbar sein, da sich das Abrufintervall in Prometheus konfigurieren lässt. Wählt man etwa ein Abrufintervall von 15 Sekunden, verliert man also maximal die Metriken in diesem Zeitfenster, sollte Knative die Anwendung kurz vor Ablauf der 15 Sekunden herunterskalieren. Muss jedoch sichergestellt sein, dass sämtliche Metriken an Prometheus gesendet werden, stößt der Pull-basierte Ansatz an seine Grenzen. Soll Prometheus beispielsweise auch das Auftreten schwerer Fehler überwachen, und ein Fehlerevent tritt zwischen dem letzten Abruf der Metriken und dem Herunterfahren der Applikation auf, bleibt es im Monitoring unsichtbar. Gegebenenfalls notwendige Maßnahmen zur Fehlerbehebung lassen sich nicht einleiten.
Alternativ lassen sich moderne Monitoring-Lösungen – darunter auch Prometheus – zum Abrufen von Metriken auch in einem Push-basierten Modus betreiben. Im Falle von Prometheus bietet sich dazu das Push-Gateway an. Es stellt einen Endpunkt zum Abliefern der Metriken bereit. In der Zielumgebung läuft mit dem Push-Gateway dann zwar dauerhaft eine weitere Komponente, da es aber die Metriken sämtlicher Serverless-Anwendungen entgegennehmen kann, spielt der zusätzliche Ressourcenverbrauch keine nennenswerte Rolle. Der Push-basierte Ansatz lässt sich in der Regel jedoch nicht ohne aufwendige Anpassung des Quellcodes umsetzen – und wird daher hier nicht weiter betrachtet.
Listing: DomainMapping
apiVersion: serving.knative.dev/v1alpha1
kind: DomainMapping
metadata:
name: my-route.example.org
spec:
ref:
name: Beispiel-App
kind: Service
apiVersion: serving.knative.dev/v1Um einen Knative-Service zusätzlich zum standardmäßig generierten Endpunkt auch über einen weiteren bereitzustellen, lässt sich per DomainMapping ein benutzerdefinierter Endpunkt einrichten. DomainMapping ist eine Kubernetes-Ressource (Custom Resource) und steht in Knative bereits seit der Beta zur Verfügung. Ein Beispiel zeigt das Listing oben. Soll der Knative-Service nur unter einem benutzerdefinierten Endpunkt verfügbar sein, lässt sich das Erstellen des automatisch generierten Endpunktes deaktivieren. Dazu genügt es, dem Knative-Service eine Annotation hinzuzufügen, beispielsweise mit folgendem Konsolenbefehl:
kubectl label kservice ${KSVC_NAME} networking.knative.dev/visibility=cluster-localDie Kaltstartproblematik lässt sich in der Regel nicht ohne Anpassungen des Quellcodes beheben. Der erforderliche Aufwand hängt stark von der Programmiersprache und dem gewählten Framework ab. Bei modernen Programmiersprachen und Frameworks ist die Wahrscheinlichkeit hoch, dass die Kaltstartzeit der Anwendung sich in einem akzeptablen Rahmen hält. Das Java-Framework Quarkus [3] beispielsweise ist auf schnelle Startzeiten hin optimiert. Die diesem Artikel zugrunde liegende Beispielanwendung ist in Java 20 mit dem weit verbreiteten JVM-Framework Spring Boot implementiert. Diese Kombination führt in der Praxis regelmäßig zu längeren Startzeiten.
Dieses Problem gehen Entwicklerinnen und Entwickler auf verschiedene Art und Weise an. Zum einen lassen sich die CPU-Limits und gegebenenfalls die Requests so anpassen, dass der Anwendung genügend Rechenleistung zur Verfügung steht, um einen möglichst raschen Applikationsstart zu erreichen. Da die Spring-Boot-Anwendung im späteren Regelbetrieb allerdings mit deutlich weniger CPU-Leistung auskommt, führt diese Vorgehensweise in typischen Kubernetes-Deployments zu einer ineffizienten Ressourcenauslastung. Als effizientere Alternative bietet sich daher an, die seit Spring 6.0 weiter optimierten AoT-Processing-Funktionen [4] (Ahead of Time) zu nutzen und die Anwendung über ein natives Graal-VM-Image bereitzustellen. Für die Beispielanwendung lässt sich dieser Weg einfach umsetzen, bei größeren Anwendungen ist jedoch mit höherem Anpassungsaufwand zu rechnen.

Vor- und Nachteile einer Serverless-Migration
Die aufgeführten Herausforderungen bei der Migration der Beispielanwendung ließen sich in den meisten Fällen einfach und ohne großen Aufwand lösen. Für das Monitoring und das Bereitstellen des Service unter einem bestimmten Endpunkt lassen sich Vorgehensweisen finden, die den gestellten Qualitätsanforderungen genügen. Die Kaltstartproblematik hingegen ist abhängig von der gewählten Programmiersprache und erfordert einen höheren Aufwand.
Ist das Einsparen von Ressourcen das Hauptziel der Migration, ist zu beachten, dass Knative selbst auch CPU- und Arbeitsspeicher-Ressourcen bindet. Laut Dokumentation setzt eine produktive Installation sechs CPU-Kerne und sechs GByte Arbeitsspeicher voraus. Um einen positiven Einfluss auf die Nachhaltigkeit des Gesamtsystems zu erzielen, braucht es also eine kritische Masse an Anwendungen.
Darüber hinaus ist Knative nur für Anwendungen mit volatiler Anfragelast sinnvoll. Dazu bieten sich die im Artikel konkret behandelten Serverless-Anwendungen an, die sich komplett abschalten lassen. Aber auch Anwendungen, die im allgemeinen Betrieb dynamisch und weitgehend unvorhersehbar skalieren müssen, profitieren von der Möglichkeit, Deployments anhand der Rate der HTTP-Requests zu skalieren, statt anhand der CPU-Verbrauchs-Metriken, wie es mit horizontalen Pod-Autoscalern möglich ist. Weist eine Anwendung jedoch ein stabiles, nur seltenen Schwankungen unterworfenes Anfragelastmuster auf, lässt sich der Ressourcenverbrauch durch eine Migration mit Knative nur unwesentlich senken. In solchen Fällen trägt Knative eher dazu bei, die Komplexität des Systems unnötig zu erhöhen.
Neben den bisher genannten Einschränkungen ist zu beachten, dass Knative ausschließlich für zustandslose Anwendungen geeignet ist. Es ist nicht möglich, ein persistentes Volume in einem Knative-Service zu mounten. Außerdem darf die Anwendung ausschließlich über HTTP auf einem bestimmten Port aufgerufen werden. Anwendungen, die Datenverkehr auf mehreren Ports empfangen oder über andere Protokolle kommunizieren, lassen sich nicht mit Knative nutzen.
Fazit: Mehr Nachhaltigkeit mit Knative ist möglich
Aus Sicht von Entwicklerinnen und Entwicklern eignet sich Knative gut für das Tuning von Anwendungen in Richtung Nachhaltigkeit. Es existiert eine umfassende und leicht verständliche Dokumentation sowie ein offizielles CLI-Werkzeug, mit dem sich Knative-Ressourcen verwalten lassen, was zu einer positiven Developer Experience beiträgt. Wer die Kubernetes-Distribution OpenShift einsetzt, profitiert zudem von einer UI-Integration, die die Entwicklungsarbeit mit Knative vereinfacht.
Knative empfiehlt sich als geeignetes Werkzeug, um Anwendungen unter bestimmten Voraussetzungen nachhaltiger zu entwickeln und zu betreiben. IT-Architektinnen und -Architekten, die sich mit dem Thema der Nachhaltigkeit beschäftigen, sollten den Einsatz von Knative in ihren IT-Umgebungen evaluieren. Wer bereits Kubernetes als Grundlage der eigenen internen Entwicklungsplattform im Unternehmen nutzt, dürfte Knative als passende Ergänzung zum Bereitstellen von Serverless-Anwendungen schätzen lernen.
Marius Stein
ist IT-Berater bei viadee mit über 10 Jahren Erfahrung in der Entwicklung Cloud-nativer-Lösungen. Er treibt den Kompetenzbereich Cloud-Architekturen technisch und strategisch mit voran.
(map [5])
URL dieses Artikels:
https://www.heise.de/-9533674
Links in diesem Artikel:
[1] https://knative.dev/docs/
[2] https://www.heise.de/news/iX-Developer-Cloud-Native-ist-da-9357842.html
[3] https://www.heise.de/hintergrund/Quarkus-Der-Blick-ueber-den-Tellerrand-4532556.html?seite=2
[4] https://www.heise.de/hintergrund/Spring-Framework-6-verarbeitet-Native-Images-und-baut-auf-Jakarta-EE-9-oder-10-7342050.html
[5] mailto:map@ix.de
Copyright © 2023 Heise Medien