

Parallele Programmierung auf dem Raspberry Pi
Seite 2: MapReduce
Einführung in MapReduce
Google präsentierte das MapReduce-Programmiermodell bereits im Jahr 2004. Das Verfahren kommt normalerweise bei Berechnungen mit großen Datenmengen auf Clustern zum Einsatz, lässt sich aber im kleinen Maßstab auf Raspberry Pi ebenso gut nutzen wie auf einem anderen Multicore-Rechner. Bei dem Verfahren werden die Daten in den drei Phasen Map, Shuffle und Reduce verarbeitet, wobei die Entwickler Map und Reduce selbst spezifizieren können.
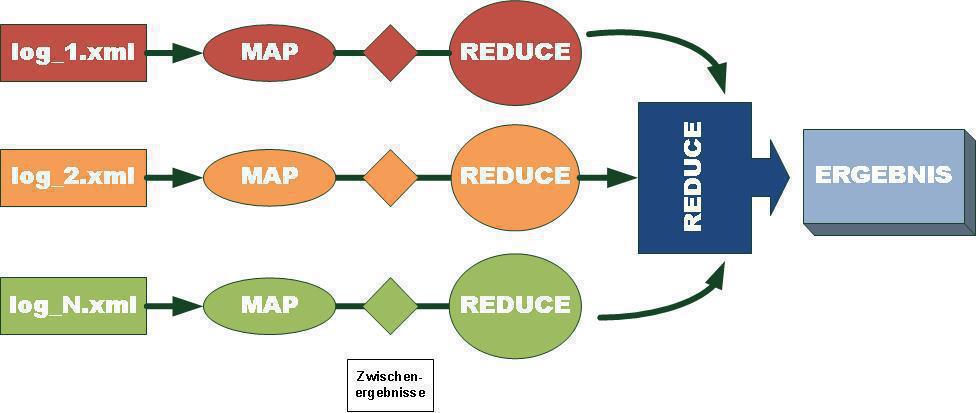
In der Map-Phase bildet der Algorithmus eine Liste von Paaren, die jeweils aus einem Schlüssel und einem Wert bestehen. Während der Shuffle-Phase sortiert das Programm die Zwischenergebnisse und/oder tauscht die Resultate zwischen den Servern im Cluster. Das Summieren oder Gruppieren der Zwischenergebnisse und Erstellen einer Liste mit Endergebnissen (ähnlich wie in Abb. 2) findet in der Reduce-Phase statt. Die Map- und die Reduce-Funktion arbeiten idealerweise parallel. Abbildung 3 zeigt das MapReduce-Muster, das im behandelten Fall tatsächlich zum Einsatz auf Raspberry Pi kam.
Parallel mit Python
Python verfügt über einige Module für die parallele Programmierung. Das multiprocessing-Modul ist dabei wirklich plattformunabhängig. Es verfügt über verschiedene Klassen und Funktionen. Eine davon ist die Klasse Pool, mit der sich die Implementierung der Parallelität vergleichsweise einfach abbilden lässt.
Die Abbildung 4 zeigt im Groben die wichtigsten Schritte der parallelen Programmierung mit dem multiprocessing-Modul. Als Erstes sollten Entwickler die Anzahl der Prozesse definieren (Zeile 4), einen multiprocessing-Pool für ihre Verwaltung instanziieren (Zeile 7) und eine Funktion wie die Mapper-Methode für die Map-Phase implementieren, die zusammen mit der Liste der Eingabeparameter an den Pool übergeben wird (Zeile 10). Den Rest erledigt das Modul multiprocessing. Es liest die Liste der Parameter ein, nimmt einen, übergibt ihn an die Funktion und startet Letztere als einen unabhängigen Python-Prozess. So geht es weiter, bis der Pool mit den parallelen Prozessen voll ist.
Wenn ein Prozess im Pool fertig ist, übergibt das System den nächsten Parameter aus der Liste an die Funktion und startet einen neuen Prozess, bis die Liste der Parameter komplett abgearbeitet ist. Das Ergebnis der parallelen Verarbeitung ist eine Liste der Rückgabewerte der benutzerdefinierten Funktion. Beim MapReduce-Verfahren wird die Liste sortiert und danach an die von den Entwicklern implementierte Reduce-Funktion übergeben. Letztere kann ebenso gut parallel ablaufen.

Im Test verarbeitete der kleine Zwerg 30 GByte XML-Dateien auf vier CPU-Kernen in 49 Minuten. Die kleinen Tricks (s. Abbildung 5) wie das Setzen des Read Buffer (Zeile 11), der Einsatz der join-Funktion für Zeichenketten (Zeile 27) und das Verkleinern der Ausgabe-Collection (Zeile 36) sowie Experimente mit verschiedenen SD-Karten von Klasse 4 bis Klasse 10 brachten nur eine bedingte Beschleunigung von etwa fünf Prozent. Zum Vergleich erledigte der Standard-Laptop mit Intel i7 auch auf vier CPU-Kernen dieselbe Aufgabe in 18 Minuten. Selbstverständlich ist Python als eine Interpreter-Sprache langsam und der Raspberry Pi ist kein High-Performance-Computer, aber es stellt sich die Frage, ob es vielleicht schneller geht – möglichst ohne wesentlichen Änderungen im Code. Die Antwort ist: "Ja, es geht – zum Beispiel mit Cython."

