Perfekter Mix: Kotlin und Python kombinieren für Machine Learning

(Bild: Willyam Bradberry/Shutterstock.com)
Im Machine Learning dominiert Python, doch auch Kotlin ist für einige ML-Bereiche besonders geeignet. Mischarchitekturen nutzen die Stärken beider Sprachen.
Im Machine Learning ist Python als Programmiersprache absolut dominant – dennoch bietet es sich an, auch hier und da über den Tellerrand zu schauen. In den letzten Jahren hat sich rund um Kotlin ein interessantes und lebhaftes Ökosystem im Bereich Data Science und Machine Learning (ML) entwickelt. Zeit für eine Bestandsaufnahme der Möglichkeiten zur Verwendung von Kotlin für drei Bereiche des Machine-Learning-Lifecycles: die Datenerkundung in Jupyter, Modell-Architekturen und das Model Serving.

(Bild: Hauke Brammer)

Bevor es ans Erkunden der Möglichkeiten und Einsatzgebiete für Kotlin im Machine Learning geht, gilt es, einen kurzen Exkurs über Machine Learning im Allgemeinen und speziell im Business Context zu unternehmen. Die Ausgangsfrage dabei ist: "Was wollen wir mit Machine Learning erreichen?"
Das Ziel ist, ein Modell mit Daten zu füttern, damit es bestimmte Vorhersagen über die Welt treffen kann. In einer Hinsicht unterscheidet sich Machine Learning im Geschäftskontext von Machine Learning zu Forschungszwecken: Ein ML-Modell allein ist nutzlos. Das ist zunächst eine überzeichnete Aussage, die aber dennoch einen realen und etwas beunruhigenden Kern hat: Etwa 90 Prozent der ML-Modelle schaffen es nicht in die Produktion [8]. Für kommerzielle Zwecke sind die meisten ML-Projekte offensichtlich wenig brauchbar.
Zwar werden einige Data-Scientists spannende Erkenntnisse gewonnen haben und auch die Marketing-Abteilung freut sich, da sie ja auch "etwas mit KI" machen. Messbarer Mehrwert entsteht jedoch nur durch ML-Modelle, die sich in konkreten Anwendungen zur Verfügung stellen lassen.
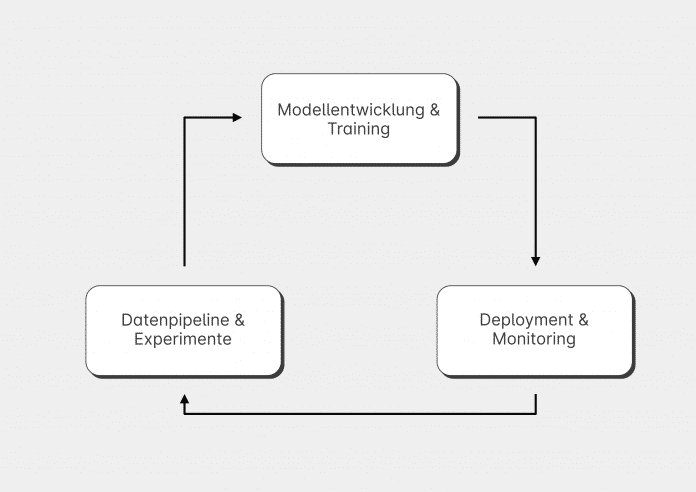
Nur in einer produktiven Umgebung ist ein Modell nützlich. Das bedeutet aber, dass wir eigentlich nicht nur Modelle, sondern ganze "Machine-Learning-Systeme" bauen wollen (siehe Abbildung 2).
Also nicht nur ein einzelnes Artefakt, sondern eine ganze Reihe von Komponenten, die es ermöglichen, zu experimentieren, zusammenzuarbeiten und kontinuierlich neue Versionen der Modelle zu erstellen und diese dann in produktive Umgebungen zu heben. Dort angekommen müssen Unternehmen sich Gedanken über den Betrieb und die Überwachung des Modells und vor allem über ein potenzielles Nachfolgemodell machen.
Mehr als nur ein Modell
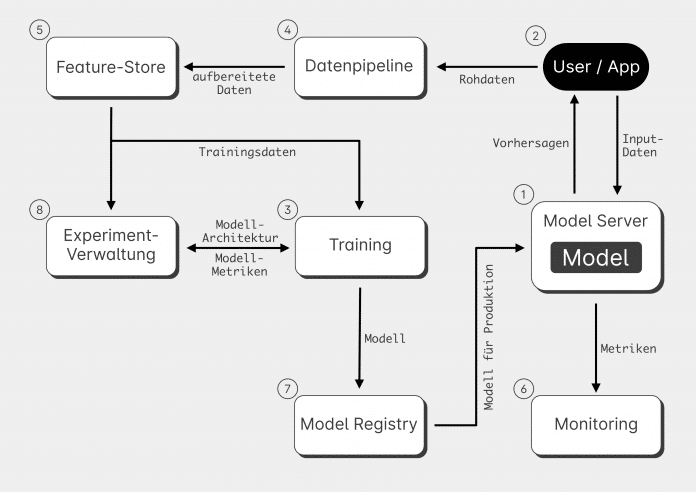
Viele unterschiedliche und komplexe Teile müssen für den erfolgreichen Produktivbetrieb ineinandergreifen, und im Kern steht das Modell selbst. Aber damit ein Team es ausliefern kann, muss es das Modell in einen Webservice oder in eine App einbetten (Abbildung 2, 1).
(Bild: Hauke Brammer)
Anschließend gehen von den Nutzern oder von den Umsystemen Daten ein und darauf aufbauend lassen sich Vorhersagen ausliefern (Abbildung 2, 2). Die Qualität eines Machine-Learning-Modells verschlechtert sich aufgrund sich verändernder äußerer Bedingungen und Input-Daten mit der Zeit. Daher genügt es nicht, nur ein einziges Modell zu trainieren, das für lange Zeit in Verwendung bleibt, sondern es gilt, eine Infrastruktur zu schaffen, um kontinuierlich neue Modelle zu trainieren.
Gerade das Entwickeln großer oder tiefer Deep-Learning-Modelle findet in der Regel nicht auf dem Laptop statt, sondern in einer Cloud-Umgebung oder auf einem GPU-Cluster im Rechenzentrum, wofür eine kontinuierliche Trainings-Pipeline nötig ist (Abbildung 2, 3). Die Daten für das Training stammen aus den Produktivsystemen – allerdings sind sie erst aufzubereiten, zu filtern und zu labeln. Dafür ist eine Data- oder ETL-Pipeline nötig (Abbildung 2, 4).
Wer in größeren Teams oder über mehrere Teams hinweg arbeitet, sollte die aufbereiteten Daten den anderen Teammitgliedern ebenfalls zur Verfügung stellen. Dafür ist bei kleinen Datenmengen noch ein Versionskontrollsystem ausreichend, bei größeren Projekten kommt ein Feature-Store zum Einsatz (Abbildung 2, 5). Wer kontinuierlich und mit immer neuen Daten weiter trainiert, kann auch laufend neue Modelle in Produktion bringen. Diese sind allerdings zu erfassen und zu versionieren, um einen einfachen Wechsel zwischen den Modellversionen zu ermöglichen. Würde man etwa erst in Produktion im Monitoringsystem (Abbildung 2, 6) feststellen, dass ein neues Modell schlechte Ergebnisse liefert, wäre das fatal. Kein Team kann es sich erlauben, darauf zu warten, bis die Vorgängerversion des Modells noch einmal neu trainiert wurde, während das Produktionsmodell falsche Daten liefert.
Richtig versioniert
Je nach Größe stehen für die Versionierung geeignete Versionskontrollsysteme wie Git oder DVC bereit, auch eine zentrale Model Registry ist eine Option (Abbildung 2, 7).
Zur kontinuierlichen Weiterentwicklung von ML-Modellen gehört es, Experimente durchzuführen: Versuche, mit einer spezifischen Modell- und Algorithmus-Konfiguration und einem Datensatz bestimmte Ergebnisse zu erzielen. Nur wenige dieser Experimente werden es in eine produktive Umgebung schaffen. Dennoch ist die Versionierung notwendig, um sich einen Überblick darüber zu verschaffen, welche Experimente man bereits durchgeführt hat und was die Ergebnisse waren, um sie in Zukunft reproduzieren und weiterverwenden zu können.
Dafür ist ein Tool erforderlich, um die Experimente zu tracken und zu verwalten (Abbildung 2, 8). Es verhindert, dass die Data Scientists die gleichen Experimente mehrfach durchführen oder Ergebnisse verloren gehen. Für erfolgreiche und produktive Machine-Learning-Projekte ist ein Satz an Tools nötig, den man sich im Verlauf eines Projekts langsam aufbaut.
Gerade beim Zusammenspiel von Kotlin und Machine Learning ist wichtig zu bedenken, dass es am Ende nicht nur darum geht, mit TensorFlow ein Deep-Learning-Modell zusammenzustecken: Es geht darum, wie sich verlässliche, reproduzierbare und skalierbare Machine-Learning-Systeme bauen und betreiben lassen.
Mit Kotlin in Jupyter arbeiten
Am Anfang jedes Machine-Learning-Projekts steht eine umfangreiche Datenanalyse. Anschließend beginnt das Design erster Modell-Architekturen und Experimente lassen sich durchführen. Für dieses iterative Vorgehen sind Jupyter-Notebooks ideal: In ihnen können Teams Daten, Notizen, Code und Visualisierungen in einem gemeinsamen Dokument darstellen und der Code lässt sich direkt und interaktiv ausführen. Das Ausführen von Python-Code ist Teil der Standard-Installation von Jupyter. Dank dessen modularer Architektur ist durch das Installieren zusätzlicher Kernel aber auch das Verwenden anderer Sprachen in den Jupyter-Notebooks möglich.
So gibt es neben Kernels für Julia, Go, Rust und Fortran auch einen für Kotlin. Mit dem Befehl conda install -c jetbrains kotlin-jupyter-kernel lässt der Kotlin-Kernel sich in einer laufenden Jupyter-Installation installieren.
Eine alternative Möglichkeit ist das Erstellen eines Jupyter-Docker-Images mit Kotlin-Kernel, wie folgendes Listing zeigt:
FROM jupyter/base-notebook
USER root
# Install OpenJDK-8
RUN apt-get update && \
apt-get install -y openjdk-8-jre && \
apt-get clean;
# Setup JAVA_HOME for docker commandline
ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/
RUN export JAVA_HOME
# Switch back to unprivileged user
USER $NB_UID
ENV JUPYTER_ENABLE_LAB=yes
# Install kotlin kernel
RUN conda install -c jetbrains kotlin-jupyter-kernel=0.11.0.95
Listing 1: Docker-Image für Jupyter mit Kotlin-Kernel
Nun lässt sich Kotlin im Jupyter-Notebook verwenden und mit dem %use-Keyword steht eine Reihe vorinstallierter Libraries bereit [9]. Neue Libraries lassen sich mit dem Befehl @file:DependsOn(LIBRARY) herunterladen und installieren.
Arbeiten mit Tabellen und Dataframe
Die Library dataframe gehört zu den bereits vorinstallierten Libraries [10]. Sie ermöglicht das Arbeiten auf strukturierten Daten, wie es aus der Tabellenkalkulationen und von Datenbanken her vertraut ist. Daten wie in diesem Beispiel die Passagierdaten der Titanic lassen sich mit einem einfachen df = DataFrame.read("titanic.csv") aus einer CSV-Datei laden.
Andere Dateiformate wie Excel und JSON lassen sich ebenso einlesen, und es ist auch möglich, hierarchische Strukturen abzubilden, also Zellen und Spalten ineinander zu verschachteln. Während die Daten in einer CSV-Datei zunächst untypisiert sind, weil sie als reine Textdaten vorliegen, werden sie beim Laden in einen Dataframe on-the-fly typisiert.
Dieses automatisch generierte Schema lässt sich mit df.schema() abfragen. Den Dataframe können Teams bereits dazu verwenden, um ihre Daten zu erkunden.
Dazu bietet die dataframe-Library eine mächtige, aber dennoch einfach verständliche API, die in Teilen an bekannte Befehle aus Datenbanken angelehnt ist.
Der Befehl df.select{name and age}.take(10) fragt die Spalten "name" und "age" ab und gibt dabei mit .take(10) nur die ersten zehn Zeilen aus. Jede Operation erzeugt einen neuen Dataframe und gibt ihn zurück. Der Dataframe selbst ist hingegen unveränderlich (immutable), um ein unbeabsichtigtes Verändern der Daten zu verhindern. Folgendes Listing führt weitere Operationen auf dem Dataframe auf:
// Welche Passagiere heissen 'Jones'?
df.filter{name.contains("Jones")}
// Wieviele Passagiere sind wo zugestiegen?
df.groupBy { embarked }
.aggregate {
count() into "count"
}
// Fehlende (Null) Daten fuer den Ticket-Preis und das Alter
// auffuellen und dann sortieren
df.fillNulls{ fare and age }
.perCol{ mean() }
.sortBy { fare.desc() }Listing 2: Datenanalyse mit Kotlin dataframe
dataframe ist ein nützliches Werkzeug zum Erkunden, Analysieren und Säubern von Daten in Jupyter-Notebooks oder auch in regulärem Kotlin-Code.
Schöne Grafiken mit Lets-Plot
Viele Zusammenhänge in Daten lassen sich in einer tabellarischen Darstellung gut erkennen. Für manche Trends und Muster gibt es jedoch schnellere und einfachere Wege der Datenvisualisierung [11] wie Lets-Plot.
Diese Plotting-Library für Kotlin verwendet einen Schichten-Ansatz, um Plot-Grafiken zu definieren. Mit jeder hinzugefügten Schicht wird ein anderer Aspekt der Grafik definiert: die verwendeten Daten, die Auswahl der Art des Plots oder die Farben und Formen im Plot.
Um beispielsweise für die Darstellung des Zusammenhangs zwischen Wohnfläche und Preisen von Häusern einen Punkte-Plot zu erstellen, lässt sich folgender Befehl verwenden:
letsPlot(data) {x = "size"; y = "price"} + geomPoint(size=5) + geomSmooth() + ggsize(500, 250)
Dabei gilt es, zunächst die Daten festzulegen und die verwendeten x- und y-Achsen zu definieren.
Mit geomPoint legen wir den Typ des Plots als Punkte-Plot fest, der die Punkte mit einer Größe von 5 Pixel plottet. Um einen geglätteten Mittelwert mit Abweichungen einzuzeichnen, ist noch die geomSmooth-Schicht hinzuzufügen. Als Letztes ist die Größe des Plots mit ggsize(500,250) festzulegen.
Lets-Plot bietet eine Vielzahl an Plot-Typen und Konfigurationsoptionen. Einige Beispiele zur Verwendung sind im folgenden Listing aufgeführt.
// Scatter Plot
letsPlot(data) {
x = "size";
y = "price"
} +
geomPoint(size=5) +
geomSmooth() +
ggsize(500, 250)
// Dichte Plot mit Kategorien
letsPlot(moreData) +
geom_density(alpha=.3) {
x="rating";
fill="category"
}
// Linienplot mit Fehlerbalken
letsPlot(study_data) {
x="learning";
color="group"
} +
geomErrorBar(width=.1) {
ymin="points_min";
ymax="points_max"
} +
geomLine {y="points"} +
geomPoint {y="points"}Listing 3: Plot-Grafiken mit Lets-Plot
Die Integration mit der dataframe-Library ermöglicht eine einfache Verwendung in Data-Exploration-Workflows oder in anderen Kotlin-Projekten.
Modelle erstellen und trainieren mit KotlinDL
Als zweiten Aspekt nach dem Erkunden von Daten geht es nun um das Erstellen von Modellarchitekturen und das Training von Modellen mit Kotlin. Die Voraussetzung dafür ist KotlinDL in der aktuellen Version 0.4.0. Die Codebasis ist Open Source und auf GitHub verfügbar [12].
KotlinDL beschreibt sich selbst, als High-Level-Deep-Learning-API, ist in Kotlin geschrieben und stark von der Python-Library Keras inspiriert. Unter der Haube verwendet es die TensorFlow Java-API und die ONNX-Runtime-API für Java. Dadurch ist auch ein einfaches Training auf Grafikkarten möglich, allerdings derzeit nur auf NVIDIA-Modellen.
KotlinDL bietet einfache APIs für das Training von Deep-Learning-Modellen von Grund auf. Auch der Import bereits trainierter KotlinDL-, Keras- und ONNX-Modelle für die Inferenz ist möglich. Importierte und vortrainierte Modelle lassen sich mit Transfer-Learning an eigene Aufgaben anpassen.
Modelltraining mit Kotlin
Das folgende Beispiel trainiert mit KotlinDL ein einfaches Modell, das Bilder in Kategorien einteilt. Der fertige Code dazu ist im folgenden Listing dargestellt:
import org.jetbrains.kotlinx.dl.api.core.layer.reshaping.Flatten
import org.jetbrains.kotlinx.dl.api.core.optimizer.Adam
import java.io.File
// Laden der Trainings- und Testdaten
val (train, test) = fashionMnist()
// Model Architektur
val net = Sequential.of(
Input(28L,28L,1L),
Flatten(),
Dense(300),
Dense(100),
Dense(10)
)
with(net){ // this: net
// Einstellungen fuer Training festlegen
compile(
optimizer = Adam(),
loss = Losses.SOFT_MAX_CROSS_ENTROPY_WITH_LOGITS,
metric = Metrics.ACCURACY
)
printSummary()
// Training des Modells
fit(
dataset = train,
epochs = 5,
batchSize = 100
)
// Evaluierung des Modells mit den Testdatensatz
val accuracy = evaluate(dataset = test, batchSize = 100)
.metrics[Metrics.ACCURACY]
println("Accuracy: $accuracy")
}Listing 4: KotlinDL: Ein einfaches Klassifizierungsmodell
KotlinDL liefert auch einige Datensätze mit, so auch den Fashion MNIST-Datensatz von Zalando. Er enthält 70.000 Bilder von Kleidungsstücken aus zehn Kategorien. Über die Hilfsfunktion val (train, test) = fashionMnist() lässt er sich importieren und direkt in 60.000 Trainingsbeispiele sowie 10.000 Testbeispiele aufteilen.
Als Nächstes gilt es, die Architektur des neuronalen Netzes festzulegen. Hier bietet sich sequenzielle Architektur an, bei der die Daten alle Schichten der Reihe nach durchlaufen. Die Input-Daten haben eine Bildgröße von 28 mal 28 Pixeln: Das erfordert einen Input-Layer entsprechender Größe, festzulegen mit Input(28L, 28L, 1L).
Die zweidimensionalen Bilddaten lassen sich mit einem Flatten()-Layer in einen eindimensionalen Vektor der Länge 784 umwandeln, damit die folgenden Layer die Daten verarbeiten können.
Es folgen zwei vollverknüpfte Dense-Layer, in denen die eigentliche Lernleistung des Modells stattfindet. Am Ende steht noch ein Output-Layer (ebenfalls Dense), der zehn Outputs hat, was der Zahl der zu unterscheidenden Kategorien entspricht. Damit ist die einfache Modellarchitektur fertig.
Im nächsten Schritt gilt es, die Einstellungen zum Training des Modells festzulegen. Als Optimierungsalgorithmus steht der Adam-Optimizer bereit und die loss function ist auf SOFT_MAX_CROSS_ENTROPY_WITH_LOGITS festzulegen. Die Metrik, die der Algorithmus optimieren soll, lautet metric = Metrics.ACCURACY.
Insgesamt sind das gewöhnliche Werte, mit denen in der ersten Iteration eines Klassifizierungsmodells nichts schiefgehen kann. Beim Training eines echten Machine-Learning-Modells wären jedoch genau auf die Aufgabe abgestimmte Parameter auszuwählen.
Eigentliches Training mit Aufruf der fit-Funktion
Das eigentliche Training findet mit dem Aufruf der fit-Funktion statt. Sie nimmt den Trainingsdatensatz zusammen mit der Anzahl der Iterationen über den Trainingsdatensatz (epochs) entgegen. Mit batchSize lässt sich festlegen, wie viele Beispiele auf einmal verwendbar sind, um die Parameter des Modells zu aktualisieren. Nach dem Training des Modells können Entwicklerinnen und Entwickler mit dem Testdatensatz und der evaluate-Funktion die Qualität der Modellvorhersage bestimmen.
Wie das Beispiel verdeutlich, lässt sich ein Machine-Learning-Modell bereits mit wenigen Zeilen Kotlin-Code trainieren und evaluieren. Dabei ist eine Vorhersagegenauigkeit von mehr als 85 Prozent erreichbar. In einem realen Projekt wäre das jedoch nur der erste Schritt in einer ganzen Reihe von Experimenten, um die optimale Vorhersagequalität eines Modells zu bestimmen.
Model Serving mit dem Framekwork Ktor
Das trainierte Modell muss man in einen Webservice oder eine App verpacken, damit Nutzer damit interagieren können und es auf der Basis von Daten Vorhersagen treffen kann. Mit KotlinDL und dem Framework Ktor [13] lässt sich in wenigen Zeilen ein ML-Modell-Server erstellen.
Ktor ist ein Kotlin-Framework auf Basis von Kotlin-Coroutines, das es ermöglicht, schlanke Webapplikationen und APIs zu bauen. Im Beispielprojekt (siehe folgendes Listing) geht es darum, ein Objekterkennungsmodell über eine REST API zur Verfügung zu stellen:
package modelserver
import io.ktor.http.*
import io.ktor.http.content.*
import io.ktor.serialization.jackson.*
import io.ktor.server.application.*
import io.ktor.server.routing.*
import io.ktor.server.engine.*
import io.ktor.server.netty.*
import io.ktor.server.plugins.contentnegotiation.*
import io.ktor.server.request.*
import io.ktor.server.response.*
import org.jetbrains.kotlinx.dl.api.inference.loaders.ONNXModelHub
import org.jetbrains.kotlinx.dl.api.inference.onnx.ONNXModels
import java.io.File
import java.util.*
fun main() {
val modelHub =
ONNXModelHub(cacheDirectory = File("cache/pretrainedModels"))
val model =
ONNXModels.ObjectDetection.SSD.pretrainedModel(modelHub) //(1)
embeddedServer(Netty, port = 8089) { // (2)
install(ContentNegotiation) {
jackson()
}
routing {
post("/detect") { // (3)
// Bilddatei empfangen und speichern (4)
val multipartData = call.receiveMultipart()
lateinit var imageFile: File
val newFileName = UUID.randomUUID()
multipartData.forEachPart { part ->
when (part) {
is PartData.FileItem -> {
val fileName = part.originalFileName as String
val fileBytes = part.streamProvider().readBytes()
call.application.environment.log.info(
"Received file: \"$fileName\"")
imageFile=File("uploads/$newFileName")
imageFile.writeBytes(fileBytes)
}
else -> TODO()
}
}
// Inferenz: Objekte erkennen (5)
val detectedObjects =
model.detectObjects(imageFile = imageFile, topK = 3)
call.application.environment.log.info(
"Found: $detectedObjects")
// Erkannte Objekte zurueckgeben // (6)
call.respond(detectedObjects)
}
}
}.start(wait = true)
}Listing 5: Model Serving mit Ktor und KotlinDL
Als Grundlage dient ein bereits fertig trainiertes Modell, das mithilfe von KotlinDL aus dem ONNXModelHub (1) zu laden ist. Einen Ktor-Server zu starten, ist kein Hexenwerk: Alles, was man dafür benötigt, ist folgender Code (2):
fun main() {
embeddedServer(Netty, port = 8089) {
//...
}.start(wait=true)
}In diesem Server-Grundgerüst lassen sich verschiedene REST-API-Endpunkte im Bereich routing festlegen. Hier gilt es, eine Route mit der post-Funktion zu definieren (3). Die Funktion kann Bilddaten entgegennehmen, sie verarbeiten und zur Inferenz an das Modell übergeben (4). Der Versand der Bilddaten erfolgt über Multipart-Formdata.
Dazu iteriert der Code über die gesamten Multipart-Daten und überprüft, ob das entsprechende Feld ein FileItem enthält. Ist das der Fall, ist der Dateiname auszulesen und für ein späteres Debugging zu loggen.
Die eigentlich Daten sind mit streamProvider().readBytes() auszulesen und in einer neuen Datei zu speichern, die eine eindeutige ID benötigt. Im Beispiel ist dafür UUID.randomUUID() als ID zuzuweisen.
Sind die Bilddaten aus der Anfrage eingelesen, kann das Modell eine Objekterkennung durchführen (5): Mit model.detectObjects(imageFile = imageFile, topK = 3) erhält es die gespeicherte Bilddatei zur Erkennung. Dabei legen die Zuständigen mit topK = 3 fest, dass sie nur an den drei wahrscheinlichsten Ergebnissen interessiert sind. Die erkannten Objekte lassen sich mit call.respond(detectedObjects) zurückgeben (6).
Auf diese Weise entsteht in nur wenigen Zeilen Code mit Ktor und KotlinDL ein einfacher Modellserver. Die Grundlage kann jedes fertig trainierte Keras- oder ONNX-Modell sein.
Für den produktiven Betrieb fehlen noch einige Schritte wie das Erfassen essenzieller Metriken, die Dauer der Inferenz und die Vorhersagequalität. Auch würde das Modell in einem produktionsreifen Modellserver nicht dynamisch vom Modellhub geladen, sondern aus einem statischen Ordner gelesen, in dem es seit dem Build-Prozess liegt.
Pythons Dominanz im Machine Learning
Zurzeit ist Python die dominierende Sprache im Machine Learning. Die Frage, warum Entwickler und ML-Ingenieurinnen sich mit anderen Programmiersprachen beschäftigen sollten und wofür sich das lohnt, steht im Raum. Dabei ist es hilfreich, die Frage einmal umzudrehen: Warum ist Python so beliebt für Machine Learning?
Zum einen ist Python eine großartige Programmiersprache und hat seit ihrem Erscheinen im Jahr 1991 eine rasante Entwicklung durchgemacht. Vor allem ist rund um Python ein ausgereiftes Ökosystem entstanden – von Bibliotheken für wissenschaftliche Anwendungen über Vektor- und Matrix-Mathematik bis hin zum Data Processing.
Da Machine Learning neben dem tatsächlichen Einsatz für Geschäftsanwendungen zunächst auch ein umfangreiches Forschungsfeld ist, sind viele der Bibliotheken in einer Sprache geschrieben, die den Entwicklern dieser Bibliotheken aus dem wissenschaftlichen Umfeld vertraut war. So kam es zu einem sich selbst verstärkenden Zyklus.
Es gibt jedoch auch noch einen anderen Grund für die Beliebtheit von Python im Machine Learning und in der Data Science: Python ist eine großartige Skriptsprache. Python-Code sieht fast aus wie Pseudo-Code, aber er funktioniert. Bei der Diskussion rund um das Für und Wider verschiedener Programmiersprachen darf aber nicht aus dem Blick geraten, dass viele Data Scientists keine Softwareingenieure sind.
Data Scientists versus Software Engineers
Im Job eines Data Scientists geht es nicht darum, eine Low-Level-Programmiersprache zu lernen, um optimalen, auf Performance getrimmten Code zu schreiben. Wenn es darum geht, ein kleines Skript zu bauen, um Daten zu analysieren, ist der Anspruch ein anderer. Ein Data Scientist muss tiefes Wissen in Statistik haben und Algorithmen entwickeln können: Dafür ist Python ideal. Es ist einfach zu nutzen und lässt sich zudem einsetzen, um auf High-Performance-Bibliotheken zuzugreifen, die unter anderem in C geschrieben sind wie NumPy und TensorFlow.
Gründe, sich mit Kotlin für ML zu befassen
Es gibt jedoch andere Gründe, sich mit Kotlin für ML zu beschäftigen. Das Deployment in die Produktion ist nicht der Abschluss eines Machine-Learning-Projekts, sondern lediglich eine weitere Phase. Die meiste Zeit verbringen Machine Learning Engineers mit der Maintenance und dem Erweitern von Komponenten. Aber je mehr Code entsteht, desto unübersichtlicher wird das Ganze. Wenn die Projekte größer werden, kann ein starkes Typsystem helfen, den Überblick zu behalten. Python ist stark typisiert, aber auch dynamisch. Das hilft bei flexiblen ad-hoc-Analysen. Mit Python lassen sich ohne großen Aufwand Datenstrukturen zusammenbauen, die sogar noch während der Laufzeit definierbar sind.
Im Gegensatz dazu ist Kotlin statisch typisiert. Typen werden zur Compilezeit an Typen gebunden. Das bedeutet, dass viele Typfehler, die in Python zu einem Runtime Error führen könnten, in Kotlin bereits zur Compilezeit auffallen. Das hilft insbesondere Teams, in denen viele gemeinsam an großen Projekten arbeiten.
Ein weiteres Problem in Bezug auf die Wartung und Skalierbarkeit von Projekten ist die Reproduzierbarkeit von Builds und eine vernünftige Verwaltung der Dependencies. In Python sind Builds und Dependencies stark von der Laufzeitumgebung des Codes beeinflusst. Das macht es schwierig, eine Reproduzierbarkeit herzustellen, wenn man nicht das ganze Environment in Docker verpacken will. Mit Kotlin ist es etwas einfacher, stabile Dependency Trees zu bauen.
Was Kotlin Python außerdem voraus hat: Bewegt man sich in Python außerhalb der gekapselten C-Libraries, wird Python ausgesprochen langsam. Im Vergleich hat Kotlin deutlich die Nase vorn.
Kotlin und Python: Machine Learner können Stärken geschickt kombinieren
Wie lässt sich Kotlin ganz konkret für das Machine Learning nutzen? Kotlin-Liebhaber wie der Verfasser dieses Artikels würden in einer idealen Welt Kotlin für jeden Schritt in ihren ML-Projekten einsetzen. Die Realität ist differenzierter: Im Bereich Daten-Pipelines und Datenaufbereitung lässt sich Kotlin hervorragend einsetzen. Null-Safety, Typsicherheit und eine Einbindung des unendlichen Java-Universums machen Kotlin hier zu einer praxisnahen und empfehlenswerten Wahl. Im Bereich des Modell-Buildings und der Experimente mit Modellarchitekturen ist es zurzeit ratsam, weiterhin auf Python zu setzen. Hier gibt es zwar mit KotlinDL gute Ansätze, aber Python ist in diesem Umfeld flexibler, und die vorhandenen Bibliotheken sind deutlich umfangreicher. Zudem weisen sie einen höheren Reifegrad auf.
Im Bereich des Model Serving, also im Produktivbetrieb von Machine-Learning-Modellen, gilt zurzeit eine klare Empfehlung für Python. Die vom Verfasser mit Python gebauten und trainierten Modelle exportiert er als ONNX-Modelle, die er ohne Probleme mit KotlinDL und Ktor als API oder Webservice zur Verfügung stellen kann. Zum jetzigen Zeitpunkt läuft es darauf hinaus, ein ML-System aus mehreren Komponenten zusammenzubauen, die sowohl mit Python als auch mit Kotlin gebaut werden.
Durch die Vielzahl an Komponenten, die für erfolgreiche Machine-Learning-Projekte nötig sind, und durch die Wahl modularer Architekturen ist es möglich, die Stärken beider Programmiersprachen an den jeweils passenden Stellen einzusetzen. So lässt sich Kotlin dort einsetzen, wo tendenziell langlebigerer und stabilerer Code nötig ist. Flexible und experimentelle Ansätze lassen sich in Python gut abbilden.

Hauke Brammer
ist Senior Software Engineer bei der DeepUp GmbH. Er arbeitet im Bereich von MLOps und ML-Engineering und hält dazu regelmäßig Vorträge. Seine Leidenschaft ist es, das Beste aus dem Software Engineering in die Welt des Machine Learning zu bringen.
(sih [14])
URL dieses Artikels:
https://www.heise.de/-7263729
Links in diesem Artikel:
[1] https://www.heise.de/hintergrund/KI-in-DevSecOps-Vom-Copiloten-zum-Autopiloten-9640331.html
[2] https://www.heise.de/hintergrund/Chancen-fuer-Quereinsteiger-wie-IT-Neulinge-und-erste-Projekte-zusammenfinden-9590255.html
[3] https://www.heise.de/news/We-Are-Developers-Das-Herbstmagazin-2023-kostenlos-herunterladen-9570659.html
[4] https://www.heise.de/hintergrund/Praktische-Barrierefreiheit-in-der-Webentwicklung-9279097.html
[5] https://www.heise.de/news/We-Are-Developers-Die-englische-Ausgabe-2023-ist-kostenfrei-verfuegbar-9201013.html
[6] https://www.heise.de/hintergrund/Webentwicklung-Detaillierte-Linkvorschauen-von-Websites-automatisiert-erstellen-7770614.html
[7] https://www.heise.de/developer/young-professionals-6065678.html
[8] https://www.redapt.com/blog/why-90-of-machine-learning-models-never-make-it-to-production
[9] https://github.com/Kotlin/kotlin-jupyter#list-of-supported-libraries
[10] https://github.com/Kotlin/dataframe
[11] https://github.com/JetBrains/lets-plot-kotlin
[12] https://github.com/Kotlin/kotlindl
[13] https://ktor.io/
[14] mailto:sih@ix.de
Copyright © 2022 Heise Medien