

Python: Richtige JIT-Optimierung – damit nichts schiefgeht
Seite 4: Schnell und präziser: C++
Und welche Ergebnisse bekommen Programmierer, die lieber C++ als Python einsetzen? Dieser Ansatz ist zwar eher unhandlich und sicher nicht so populär wie die Verwendung von Python. Das Ergebnis ist jedoch erstaunlich. Listing 9 zeigt den Code (der komplette Code steht ebenfalls auf GitHub zum Download bereit).
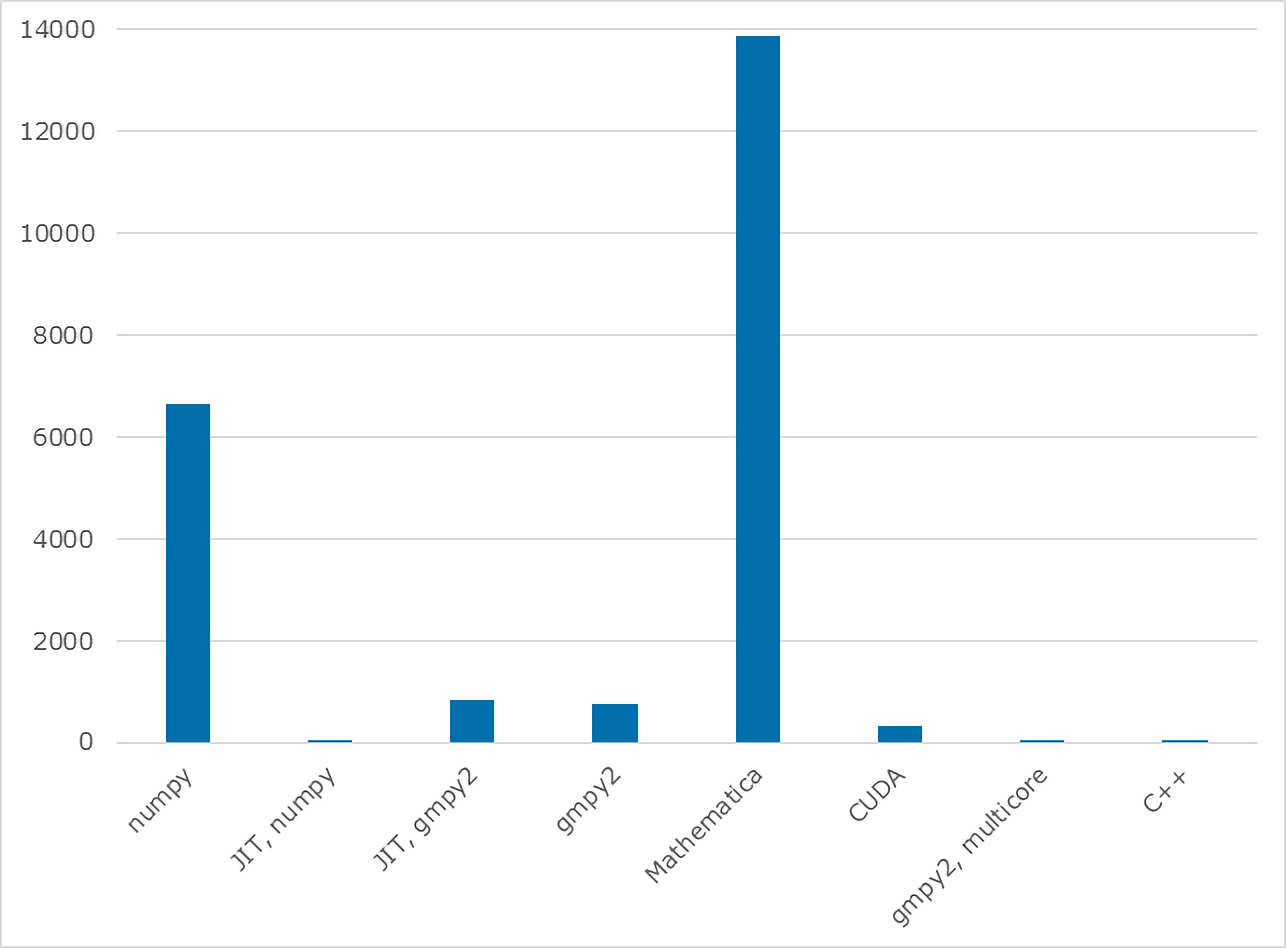
Um Präzisionsverlust zu vermeiden, kam bei diesem Beispiel die Bibliothek GMP (The GNU Multiple Precision Arithmetic Library) zum Einsatz. Das Programm hat dann auf einem Surface 6 Pro binnen sieben Sekunden die korrekten Lösungen gefunden und dabei nicht eine einzige Falschlösung ausgespuckt. Hierbei waren insgesamt nur acht Threads beteiligt.
int main(int argc, char ** argv) {
uint64_t const gbegin = std::stoll(argc >= 2 ? argv[1] : "0"),
gend = std::stoll(argc >= 3 ? argv[2] : "0");
size_t const nthreads = std::thread::hardware_concurrency();
std::cout << "Num threads: " << nthreads << std::endl
<< "Begin: " << gbegin << ", End: " << gend << std::endl;
auto stime = Time();
if (gbegin < gend) {
std::mutex cout_mux;
std::vector<std::future<void>> threads;
for (size_t ithread = 0; ithread < nthreads; ++ithread)
threads.emplace_back(std::async(std::launch::async, [&, ithread]{
uint64_t const block = (gend - gbegin + nthreads - 1) / nthreads,
begin = gbegin + ithread * block,
end = std::min<size_t>(gbegin + (ithread + 1) * block, gend);
mpz_class x, t0, t1, y, root, rem;
for (uint64_t ix = begin; ix < end; ++ix) {
x = uint32_t(ix >> 32); x <<= 32; x |= uint32_t(ix);
mpz_pow_ui(t0.get_mpz_t(), x.get_mpz_t(), 6);
mpz_pow_ui(t1.get_mpz_t(), x.get_mpz_t(), 2);
y = t0 - 4 * t1 + 4;
mpz_sqrtrem(root.get_mpz_t(), rem.get_mpz_t(), y.get_mpz_t());
if (rem == 0) {
std::lock_guard<std::mutex> lock(cout_mux);
std::cout << "[" << mpz_to_str(x) << ", " << mpz_to_str(root)
<< ", " << mpz_to_str(y) << "]" << std::endl;
}
}
}));
}
stime = Time() - stime;
std::cout << "Time " << std::fixed << std::setprecision(3)
<< stime << " sec" << std::endl;
}
Listing 9: Die Routine aus Listing 5 wurde hier in C++ umgesetzt.
JIT, CUDA oder C++ für mehr Performance
Das konsistente rechenintensive (aber nicht komplizierte) Beispiel legt dar, welche Präzisionseinbußen eine wirklich starke Beschleunigung nach sich zieht. Aber auch, mit welchen Performance-Einbußen Entwickler rechnen müssen, wenn Präzision an erster Stelle steht. Zusammenfassend lässt sich sagen, dass Python mittels JIT- oder CUDA-Optimierung zwar eine hoch performante Implementierung erlaubt, Programmierer sich aber in sehr hohen Zahlenregionen mit Überläufen konfrontiert sehen. Der beste Kompromiss zwischen Performance und Präzision ist der Einsatz von gmpy2 (ohne JIT-Optimierung aber mit multiprocessing). Denn in dieser Konstellation sind keine Überläufe und damit einhergehend Falschlösungen entstanden und die Laufzeit betrug etwa 15 Minuten (mit multiprocessing 49 Sekunden) und keine Stunden wie im Falle der (präzisionsverlustfreien) Variante NumPy oder Mathematica.
Als unschlagbar hat sich die Implementierung in C++ herausgestellt: Sie lieferte auf einem Surface 6 Pro nur korrekte Lösungen ohne Präzisionsverlust. Wenn es also ausschließlich um Präzision und Performance geht, werden Programmierer nicht um den Einsatz C oder C++ herumkommen.
Eldar Sultanow
ist Architekt bei Capgemini. Seine Schwerpunkte sind moderne Softwarearchitekturen, Data Science und Unternehmensarchitekturmanagement.
(fms)
