

Sinnvoll geclustert: Smarte Suche mit Vektoren
Einsatz und Performance von Vektordatenbanken zur semantischen Suche bei Retrieval Augmented Generation am Beispiel einer Musikdatenbank.

(Bild: whiteMocca/Shutterstock.com)
- Jan Petzold
Vektordatenbanken sind neben den etablierten relationalen, Key/Value-basierten und Graph-Datenbanken noch eine weitere Art der Datenspeicherung. Als Persistenz sind sie nur bedingt interessant doch die Strukturierung der Daten nach Ähnlichkeit macht sie besonders. In der Praxis kommen sie daher oft für Retrieval Augmented Generation (RAG) im Zusammenspiel mit den vor allem durch ChatGPT bekannt gewordenen Large Language Models (LLMs) zum Einsatz. Vektordatenbanken sind attraktiv, da sie es erlauben, ein generisch trainiertes LLM um domänenspezifisches Wissen anzureichern, ohne dieses Wissen öffentlich im Internet mit OpenAI und Co. zu teilen. Der Artikel zeigt anhand eines konkreten Beispiels die Möglichkeiten und Grenzen gängiger Vektordatenbanken.
Die Musikdatenbank als Beispiel
Dieser Artikel nimmt Fragen zum Inhalt von Songtexten als Beispiel, um die semantische Suche auf Basis von Vektordatenbanken zu demonstrieren. Anhand des im Rahmen des Artikels entstandenen Sourcecodes sollte sich bei jedem der etablierten Hyperscaler ein performanter Chatbot mit Antwortzeiten im Millisekundenbereich implementieren lassen.
Videos by heise
Als Grundlage für das "Domänenwissen" dient ein Datensatz mit Songtexten, der frei über Kaggle herunterladbar ist. Er besteht aus ca. 60.000 Songs mit ihren Texten. Die Größe der Rohdaten als Plaintext liegt bei etwa 62 MByte (das entspricht ungefähr 13 Millionen Wörtern oder 27.000 DIN-A4-Seiten Text). Verglichen mit Produkten der BigTech-Unternehmen, die häufig mehrere Terabyte umfassen, ist der Datensatz klein, die Ergebnisse der Untersuchung sollten sich dennoch auf viele gängige Use Cases übertragen lassen, deren bereinigte Daten ähnlichen Umfang haben (was nicht selten der Fall ist). Das Beispiel bleibt zudem auf einem handelsüblichen Laptop nachvollziehbar.

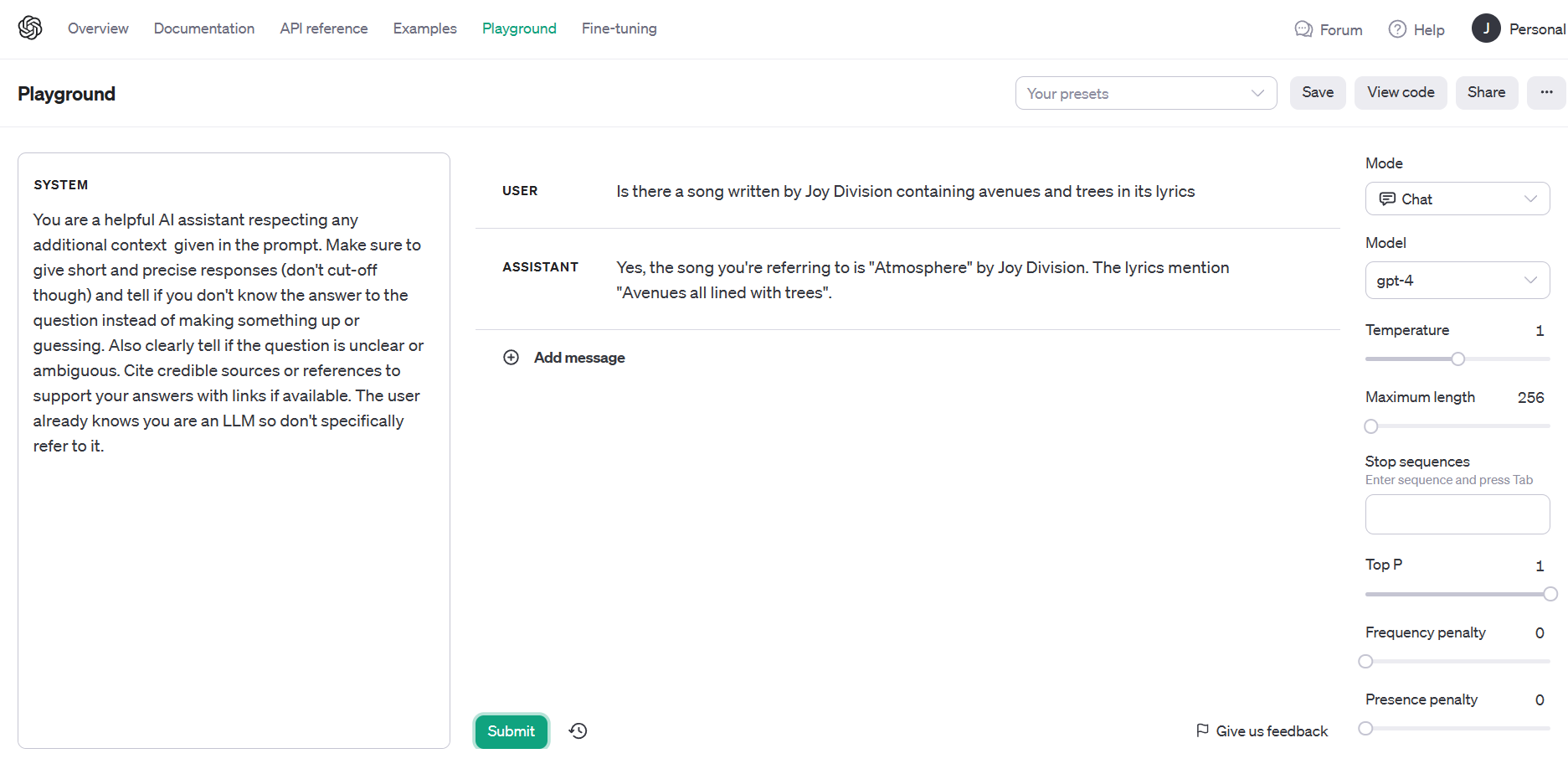
Wie lässt sich der Datensatz als Domänenwissen praktisch nutzen? Dazu ein kurzes Beispiel auf Basis von GPT4 mit dem OpenAI Playground (Abbildung 1). Die Frage nach einem Song von Joy Division, in dem die Worte "Avenues" und "Trees" vorkommen, beantwortet das Modell scheinbar schlüssig, aber dennoch falsch. Denn die Worte kommen in dem in der Antwort genannten Song gar nicht vor.
Zieht man nun eine Vektordatenbank mittels RAG hinzu, gelangt man zum richtigen Ergebnis, dem Song "Ceremony", von Joy Division geschrieben und der Nachfolge-Band New Order aufgenommen (Der Weg dorthin ist weiter unten im Artikel genauer beschrieben). Man füttert die Datenbank mit den Daten aus dem Kaggle-Datensatz und injiziert das Ergebnis der Suche in den Prompt. GPT-4 muss dann quasi nur noch die Antwort formulieren – die nun korrekt ausfällt (Abbildung 2).
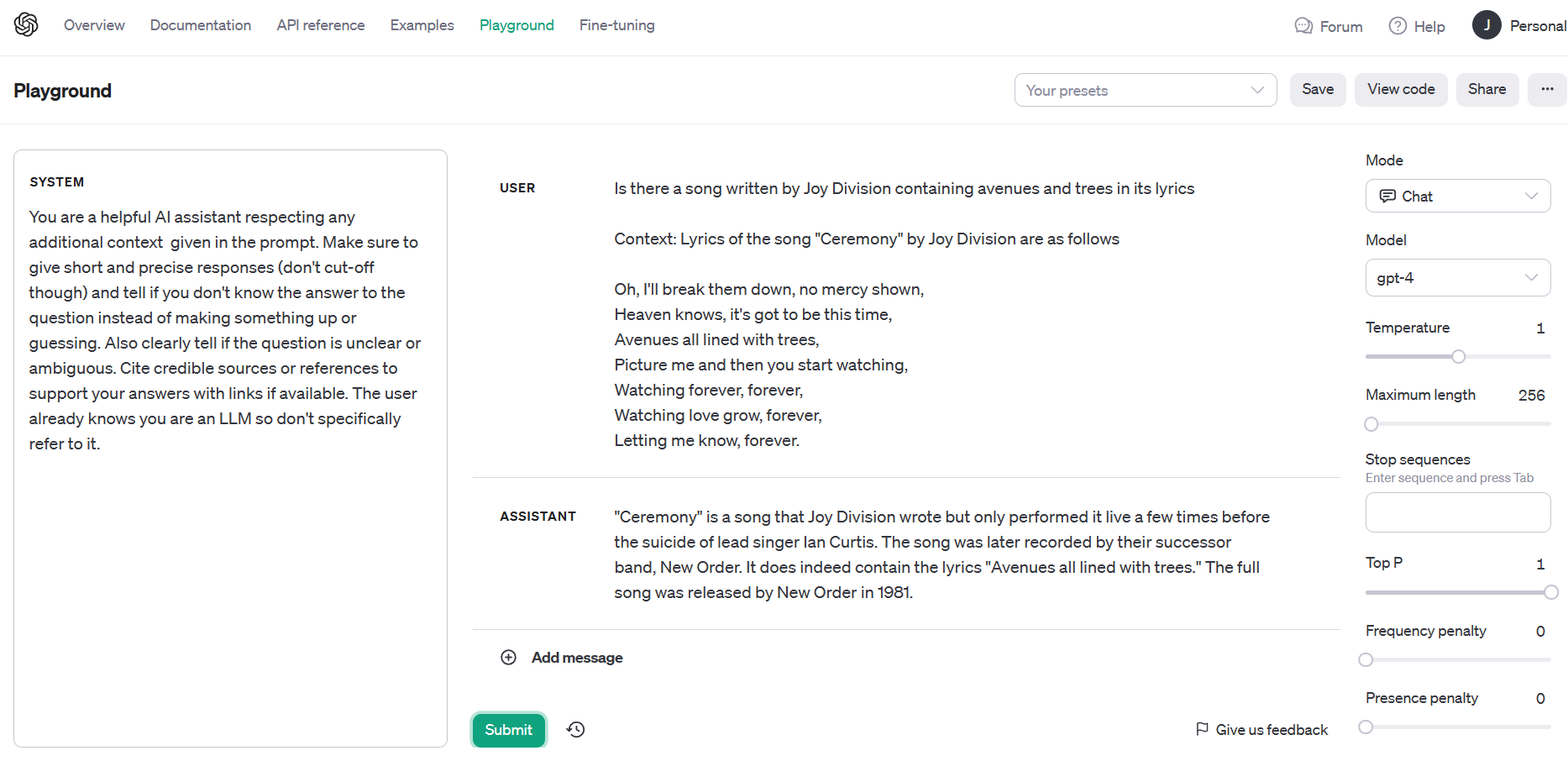
Das Beispiel macht einen wesentlichen Vorteil von RAG deutlich: erweitertes Domänenwissen reduziert das Risiko von Halluzinationen bei LLMs erkennbar.
Für die generelle Anwendbarkeit und eine Implementierung in Azure empfiehlt sich an dieser Stelle der weiterführende Beitrag von Rainer Stropek zu Embeddings mit Azure OpenAI, Qdrant und Rust. In diesem Artikel soll es eher darum gehen, verschiedene Lösungsansätze der Vektorisierung und Indexierung zu vergleichen und hinsichtlich Geschwindigkeit und Suchqualität zu bewerten. Der Fokus richtet sich dabei primär auf semantische Suchen, das heißt Suchoperationen, die sich auf ein Verständnis respektive die Bedeutung der Inhalte fokussieren, statt nur übereinstimmende oder ähnliche Wörter zu finden. Zunächst aber ein paar Grundlagen zu Vektordatenbanken.
Rückschau: Wie suchen (andere) Datenbanken?
Vektordatenbanken sind nicht neu, bei Geodaten kommen sie bereits seit den 1960er-Jahren zum Einsatz. Durch den Boom der LLMs (Large Language Models) rücken sie wieder stärker in den Fokus. Im Prinzip kann man sich Daten in einer Vektordatenbank wie eine räumliche Anordnung von Punkten in einem mehrdimensionalen Raum vorstellen. Sie eignen sich besonders dazu, Werte zu clustern: Zusammenhänge liegen nah beieinander, Duplikate überdecken sich. Dieser Ansatz hebt sich grundlegend von dem klassischer Datenbanken ab. Er eignet sich besonders für eine semantische Suche.
Relationale Datenbanken haben ihre Wurzeln bei Anwendungen im Finanzwesen und bilden Transaktionen wie Überweisungen, ab, die sich im Fall von Fehlern rückgängig machen lassen. Die Suche ist hier meist auf Volltext oder Platzhalter (%ART% findet "Start" und "Artist" aber nicht "Ast") beschränkt. Die vor allem im Web etablierten Schlüssel-Werte-Datenbanken (Key/Value Store) haben flexible Datenstrukturen, um etwa die Daten einer Kleinanzeige in einem Portal mit Titel, Beschreibung und einer variablen Anzahl von Bildern zu erfassen. Die Suche in den Daten unterscheidet sich technisch meist kaum von der bei relationalen Datenbanken. Häufig ist sie jedoch in einen separaten Service ausgelagert, dem das auf Textsuche optimierte Open Source-Projekt Apache Lucene zugrunde liegt (Apache Solr, ElasticSearch, Cloudera Search). Lucene eignet sich für diesen Zweck gut, da es schon vor der Indexierung die Daten verarbeitet und bereinigt, zum Beispiel Satz- und Sonderzeichen sowie Stoppwörter wie "und" oder "also" entfernt, Stammform eines Wortes bildet und vieles mehr. Für die exakte oder unscharfe Suche (z. B. Fehlertoleranz, also Suche nach "Vektor" findet auch "Vector") empfiehlt sich Lucene. Eine echte semantische Suche, die über Wörtervergleich beziehungsweise Ähnlichkeiten hinausgeht, ist damit hingegen schwer umsetzbar da Lucene nicht inhaltsbezogen clustern kann.
Von den Daten zur Suche
Wie im verlinkten Git-Projekt erkennbar lässt sich eine vektorbasierte Suche rudimentär in weniger als 20 Zeilen Code umsetzen. Ein paar Schritte sind aber ausgehend vom Musikdatenbank-Beispiel vorab nötig:
- Quelldaten übertragen und aufbereiten: Da die Texte bereits in Form einer CSV-Datei vorliegen, genügt eine simple Bereinigung (Zeilenumbrüche).
- Vektorisierung: Die Quelldaten sind in einen Vektor umzuwandeln (ein Wort/Satz wird (vereinfacht) letztlich zu einem Array von Fließkommazahlen wie z.B. [0.27364571,0.65308426,0.12844638]). Zum Umwandeln dienen verschiedene Transformer. Der Vektor ist hinsichtlich der maximalen Länge eingeschränkt, das heißt, der Eingabetext würde bei Überschreiten der Maximallänge abgeschnitten.
- Alle Vektoren werden in einem Index gespeichert und persistiert, die Anordnung der Daten erfolgt entsprechend vorher festgelegter Algorithmen/Optimierungen (nähere Details folgen weiter unten).
- Die Suchanfrage (Input des Users) wird nun ebenfalls in einen Vektor umgewandelt und die passenden Treffer (= naheliegende Vektoren) aus der Datenbank gesucht.
Durch die Transformation sind alle möglichen digitalen Daten als Quelle denkbar, abhängig vom Transformer lässt sich also beliebig nach Texten, Bildern und Videos suchen.
Was sind Token – und warum sind sie wichtig?
Bei der Verarbeitung (bzw. generell bei LLMs) von Textdaten ist zwischen Token und Wörtern zu unterscheiden. Jedes System, das auf Vektordaten arbeitet, hat Einschränkungen hinsichtlich der Maximalzahl an Token, etwa bei der Eingabe eines Prompts. ChatGPT-4 erlaubte initial maximal 4096 Token bei der Eingabe, ChatGPT-4 Turbo akzeptiert bis zu 128.000 Token. Auch andere LLMs wie Claude erlauben bis zu 100.000 Token.
Um analytische Operationen (Vergleiche) zu ermöglichen, müssen die Wörter der Texteingabe zur Verarbeitung in Teile aufgeteilt werden. Ein Wort wie "unbreakable" beispielsweise resultiert je nach Algorithmus in bis zu drei Token (un / break / able). Daher ist es bereits vor, spätestens jedoch während der Verarbeitung wichtig, die Anzahl der aus einer Zeichenkette resultierenden Token zu berücksichtigen und den Text gegebenenfalls aufzusplitten, um keine Informationen zu verlieren.
Im vorliegenden Beispiel umfasst der längste Songtext "Hello" von Eminem eine Gesamtzahl von 807 Wörtern – daraus ergeben sich 1034 Token. Der Transformer all-mpnet-base-v2 erlaubt maximal 384 Token pro Datensatz. Damit würde ein Großteil des Songtextes wegfallen, sofern man die Daten nicht aufteilt – wie sich im auf GitHub hinterlegten Beispiel anschaulich nachvollziehen lässt.
Transformer: Semantisch clustern
Die Transformation der Quelldaten in Vektoren ist der erste Schritt der Verarbeitung, dabei wird der Datensatz beziehungsweise der Text in Token gewandelt und als Array von Fließkommazahlen ausgegeben. Ähnliche Informationen sind anschließend gemäß ihrer Semantik geclustert. Abbildung 3 zeigt eine über das Web-Interface von QuantDB visualisierte Darstellung für die Beispieldaten.

(Bild: QuantDB)
Transformer sind in der Regel vortrainiert (zum Teil auch auf verschiedene Sprachen optimiert), um anhand der Textbestandteile möglichst genau den Kontext und Zusammenhang von Textsequenzen oder Sätzen einzuordnen.
Die Wahl des Transformers hat entscheidenden Einfluss auf Performance und Qualität der semantischen Suche. Die Tabelle 1 fasst ein paar Ergebnisse zur Performance und Indexgröße auf Basis des Quelldatensatzes (62 MByte) zusammen.
| Tabelle 1: Ergebnisse zu Performance und Indexgröße | |||||
| Transformer | all-MiniLM-L6-v2 | multi-qa-MiniLM-L6-cos-v1 | all-mpnet-base-v2 | text-embedding-ada-002 | ELSER v2 |
| Lizenz | Apache 2.0 (frei verfügbar) | Apache 2.0 (frei verfügbar) | Apache 2.0 (frei verfügbar) | Proprietär | Proprietär |
| Max. Anzahl an Input-Token | 256 | 512 | 384 | 1536 | 512 |
| Testsystem CPU/GPU | Azure FSv2 (4 GB RAM) / nVidia T4 | Azure FSv2 (4 GB RAM) / nVidia T4 | Azure FSv2 (4 GB RAM) / nVidia T4 | OpenAI API | Elastic Cloud (gcp.es.ml.n2.68x32x45, 4GB RAM) |
| Dauer Generierung Vektoren CPU/GPU | 34 min / 3 min | 35 min / 5 min | 178 min / 20 min | 48 min | 346 min |
| Kosten Generierung Vektoren | 0 € | 0 € | 0 € | 1,48 € | 0 € |
| Datengröße Vektordaten | 86 MByte | 86 MByte | 173 MByte | 345 MByte | - |
Die Unterschiede hinsichtlich Dauer und Speicherbedarf sind deutlich: das Generieren auf einem System mit leistungsfähiger GPU erfolgt fast zehnmal schneller als auf einem CPU-only-System.
Index – nicht zwingend nötig, aber empfehlenswert
Nach der Transformation liegen die Daten in vektorisierter Form vor. Wie bei klassischen Datenbanken bedarf es für die Suche noch eines Index. Er ist bei Vektordatenbanken zwar nicht zwingend erforderlich, aber speziell bei großen Datenmengen sinnvoll. Für die Indexierung stehen verschiedene Ansätze zur Auswahl, die es genauer zu betrachten gilt.
Flat-Index: Hier werden alle Vektoren gespeichert und im "Brute Force"-Modus nacheinander durchsucht. Damit erreicht das System höchste Präzision (die ganze Datenbank wird durchsucht), aber die Suche ist tendenziell langsamer als bei anderen Ansätzen.
Inverted File Index (IVF): Der Ansatz basiert auf einem partitionierten (z. B. auf Basis von Voronoi-Diagrammen) Suchindex. Bei der Suchabfrage wird für den Such-Vektor der nächste Mittelwert einer Region ermittelt und die Suche somit nur noch auf einer Teilmenge fortgesetzt. Das beschleunigt die Suche – allerdings auf Kosten der Qualität.
Hierarchable Navigatable Small World (HNSW): In einem Graph wird bei diesem Ansatz ausgehend von einem Startpunkt der jeweils passendste Nachbar ausgewählt, bis der am besten passende gefunden ist. Ausführlicher beschrieben ist HNSW bei Pinecone.
Der weitere Vergleich beschränkt sich auf folgenden Datenbankprodukte, um die verschiedenen Ansätze abzubilden:
- FAISS gibt es bereits seit 2017. Es ist eher eine Bibliothek und weniger eine Vektordatenbank. FAISS beherrscht aber alle genannten Indexierungsmethoden.
- Qdrant ist eine Vektordatenbank, die in Rust geschrieben ist. Sie unterstützt im Unterschied zu FAISS fortgeschrittene Operationen wie Filterung. Qdrant nutzt die hnswlib (Open Source). Auf dem HNSW-Algorithmus als Basis bauen auch Produkte wie Chroma, pgvector (PostgreSQL und duckdb), Milvus und Redis – sie sollen daher an dieser Stelle im Vergleich nicht gesondert betrachtet werden.
- Weaviate bietet als Cloud-Dienst ein vergleichsweise attraktives Preismodell und nutzt laut Hersteller eine eigene HNSW-Implementierung.
- ElasticSearch ELSER v2: Hierbei handelt es sich um eine Erweiterung von ElasticSearch für die semantische Suche. ELSER greift auf bestehende Indizes zu und generiert die Vektoren bereits auf Bestandsdaten. Dies ist auch interessant für Use Cases die bereits die Standard-Suchfunktionen von Elastic einsetzen und nun eine vektorbasierte Suche ergänzen wollen, ohne neue Systeme aufzusetzen.
ELSER unterscheidet nicht zwischen Transformer und Index, der Aufbau des Index passiert hier in einem einzigen Schritt. Dies lässt sich anhand der Elastic Console-Kommandos nachvollziehen.
Einige weitere kommerzielle Anbieter wie beispielsweise MongoDB springen auf den Vektor-Zug auf, erweitern dazu ihr Bestandsprodukt aber nur minimal, sodass sich etwa zusätzliche (vorgenerierte) Vektoren persistieren und durchsuchen lassen. Die verwendeten Algorithmen sind je nach Anbieter gleichwertig oder schlechter als bei den oben genannten Produkten.
