

Software-Upgrade: Migration von Hibernate nach EclipseLink
Seite 2: Upgrade mit Modellen
Upgrade auf Basis von Modellen
Ein Upgrade darf keinesfalls die Semantik der Applikation verändern. Die Logik des Modells muss folglich unangetastet bleiben. Deshalb ist es wünschenswert, ein System zu haben, das den Code, im konkreten Fall den von JPA 1, in ein Modell einliest, um hieraus wiederum Quelltext in JPA 2 zu erzeugen.
Beim Generieren von Quelltexten aus Modellen spielen herkömmliche UML-Werkzeuge ihre Stärke aus. Über Templates kann man für jegliche Aspekte der UML eine Repräsentation im Quelltext definieren. Da die Logik der zu konvertierenden Applikation aber nicht modelliert, sondern programmiert wurde, muss die Software das Modell aus dem bestehenden Quelltext erzeugen. Die Unterstützung von Modellierungswerkzeugen für die Rückgewinnung eines Modells aus handgeschriebenem Quelltext ist jedoch unzureichend. Gewöhnliche Reverse-Engineering-Techniken bieten keine Möglichkeit, über Templates auf die Generierung des Modells Einfluss zu nehmen, womit sie unflexibel und nicht an eigene Bedürfnisse (wie sie gerade bei gewachsenen Legacy-Systemen regelmäßig vorkommen) anpassbar sind. Außerdem abstrahieren diese Techniken nicht in hinreichendem Maß, sodass das resultierende Modell von rein technisch motivierten Implementierungsdetails überfrachtet wird. Die Migration auf einen neuen technischen Standard wäre somit genauso umfangreich wie diese direkt im Quelltext selbst vorzunehmen.
Dadurch waren die Anforderungen an ein Tool für das Projekt klar definiert: Der Quelltext war in ein Modell einzulesen, dem ein allgemeines Datenbankmetamodell zugrunde liegt. Es musste im Modell von Implementierungsdetails abstrahieren können, um im Anschluss aus dem Modell den Quelltext für die Zieltechnik zu generieren. Das ist ein Anwendungsfall für UML Lab, eine in Eclipse integrierte Modeling IDE, die einen automatischen Abgleich zwischen Quelltext und Modell ermöglicht.
Yatta Solutions bezeichnet die Technik als Round-Trip Engineering. Beim Reverse Engineering wird – anders als bei anderen Tools – ein Template-Ansatz verfolgt. Dabei kommen dieselben Templates, die üblicherweise bei der Codegenerierung (Forward Engeneering) genutzt werden, auch für das Reverse Engineering zum Einsatz. Der Vorteil hierbei ist, dass Konzepte aus dem Modell, die die Templates auf vielen Quelltextfragmenten (auch über Dateigrenzen hinweg) abbilden, beim Einlesen wieder als einzelnes Konzept erkannt werden.
Ein Beispiel hierfür ist ein Datenbankobjekt. Modellseitig handelt es sich um eine einfache Klasse, die durch einen UML-Stereotyp als Entität qualifiziert ist. In Java stößt man für diese Klasse jedoch auf mehrere Repräsentationen. Zunächst gibt es neben der DO- auch drei weitere DTO-Klassen, mit entsprechenden Konstruktoren und Transformations-Factories. Auch innerhalb der DO-Klasse finden sich rein technisch motivierte Aspekte wieder: Neben den Annotationen an der Klasse selbst gibt es weitere Methoden wie toString(), hashCode() und equals() sowie Factory-Methoden zum Erstellen der beiden DTOs. Diese Implementierungsdetails sind immer wiederkehrende Muster, die sich in allen DOs der Applikation wiederfinden. Durch Template-basiertes Reverse Engineering werden die Details als ein zusammenhängendes Konzept erkannt und modellseitig durch die einzelne Klasse mit Entitätsstereotyp repräsentiert – ganz so, wie man es erwarten würde.
Soll man also einen Implementierungsstil (hier JPA 1) in einen anderen (JPA 2) umwandeln, sind entsprechende Templates zu erstellen, sofern sie nicht im Lieferumfang von UML Lab enthalten sind. Nach dem Reverse Engineering wird dann im Modell für die betroffenen Elemente der Code-Stil geändert. Nach erneuter Generierung liegt der Quelltext anschließend gemäß dem neuen Implementierungsstil vor. Als Templatesprache verwendet UML Lab das aus dem Eclipse-Projekt M2T bekannte Xpand. Somit lassen sich auch Xpand-Templates für das Round-Trip Engineering verwenden.
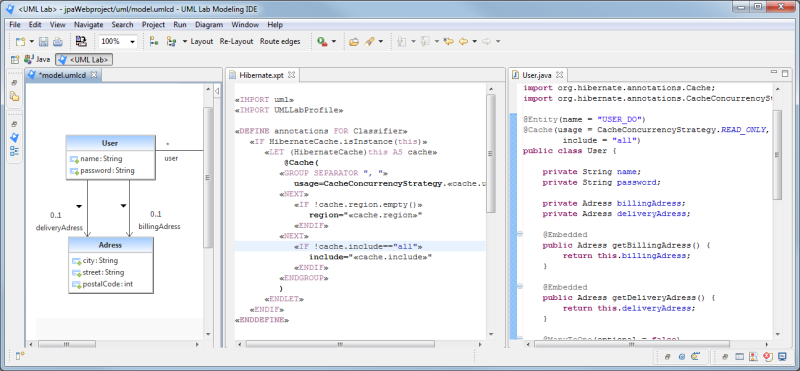
Die Aufgabe von Micromata war es nun, Xpand-Templates zu entwickeln, mit deren Hilfe UML Lab das Modell der zu überarbeitenden Software erstellt. Um im Anschluss Quelltext mit den für JPA 2 benötigten Implementierungsdetails zu generieren, erzeugten die Entwickler hierfür entsprechende Templates.
UML an eigene Bedürfnisse anpassen
Die UML (Unified Modeling Language) hat sich als Beschreibungssprache für die Softwareentwicklung etabliert. Um sie an eigene Bedürfnisse anzupassen, stehen sogenannte UML-Profile zur Verfügung. Damit lassen sich Konzepte der UML einschränken oder erweitern.
Im konkreten Micromata-Projekt musste ein abstraktes Modell den mit JPA 1 konformen Quelltext repräsentieren. Hieraus sollte der JPA-2-konforme Quelltext generiert werden. Dazu war es erforderlich, die UML an Anforderungen aus der Datenbank-Mapping-Domäne anzupassen. Das erfolgte mit einem UML-Profil. Im Profil ist beispielsweise ein Stereotyp Entity definiert, der modellseitig eine Datenbank-Entität repräsentiert. Mit zusätzlichen Attributen wie entityName oder cacheable lassen sich auch weitere Details der Datenbankdomäne modellieren. Abbildung 3 zeigt einen Auszug aus dem resultierenden UML-Profil zur Modellierung der Datenbank-Entitäten.

