

100 Millionen US-Dollar für Exaflops-Rechentechnik
Supercomputer für Wissenschaft, Rüstung und Atomtechnik sollen nach 2020 über 1000 PFlops Rechenleistung erreichen. Die US-Regierung schiebt die Entwicklung mit weiteren Fördermitteln an.

Der schnellste Superrechner der aktuellen Top500-Liste leistet knapp 34 Petaflops, also 33,862 Billiarden Gleitkomma-Operationen pro Sekunde. Dabei schluckt der 17,8 Megawatt (MW) Leistung. Damit Exascale-Supercomputer realisierbar werden, die mehr als 1000 PFlops Rechenleistung liefern, müssen Rechenwerke, Arbeitsspeicher, Interconnects und Storage-Systeme deutlich effizienter werden – grob geschätzt um den Faktor 20 bis 25. Die neue Technik dafür sollen IT-Firmen möglichst innerhalb der nächsten sechs bis acht Jahre entwickeln, sodass Exaflops-Supercomputer ab etwa 2023 gefertigt werden können.
Um die Entwicklung zu beschleunigen und in die gewünschten Bahnen zu lenken, vergibt das US-Department of Energy (DoE) in Kooperation mit der National Nuclear Security Administration (NNSA) Fördermittel. Ziel ist es, den USA den Zugriff auf die schnellsten Supercomputer für Wissenschaft, Rüstung und (nukleare) Energietechnik zu sichern.
(Bild: Nvidia)
Nach Voruntersuchungen hatte das DoE 2012 Fördermittel von rund 62 Millionen US-Dollar an AMD, IBM, Intel und Nvidia ausgeschüttet sowie an den 2012 von Intel übernommenen Lustre-Spezialisten Whamcloud. Nun steht die Vergabe von etwa 100 Millionen US-Dollar für das Folgeprojekt FastForward2 an. Auf mehreren Treffen haben wieder AMD, IBM, Intel und Nvidia ihre Ideen vorgestellt. Die Koordination erfolgt durch das Lawrence Livermore National Laborory (LLNL).
"Joule pro Bit"
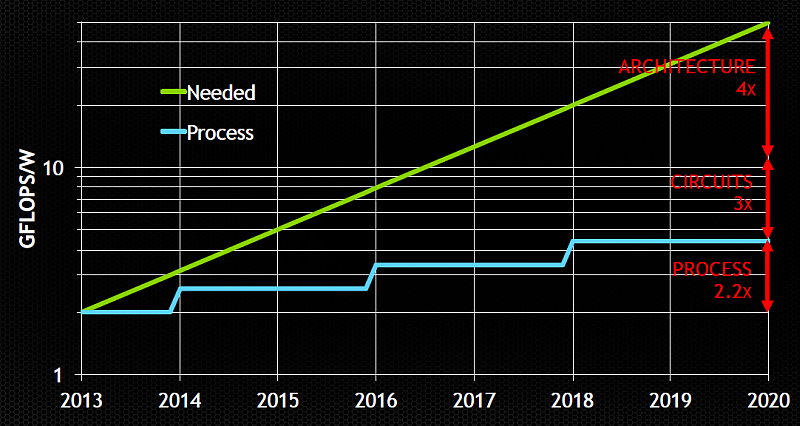
Eine große Rolle bei der Effizienzsteigerung spielt der Transport der Daten sowohl innerhalb von Chips – also zwischen verschiedenen Rechenwerken und Caches – als auch zwischen Prozessor und RAM sowie auf Bus- und Interconnect-Systemen für Cluster und zur Anbindung von Storage. Nach einer Abschätzung von Stanford-Professor William (Bill) Dally, der auch für Nvidia tätig ist, verlangen Exascale-Rechner eine veränderte Architektur und andere Programmiermodelle. Nur ein Bruchteil der nötigen Effizienzsteigerung lässt sich jeweils aus dem Moore'schen Gesetz – also verbesserten Fertigungsprozessen für CPU, GPU und Speicher – und aus optimierten Interconnects (Circuits) ziehen.

(Bild: AMD)
AMD schlägt optimierte CPU-GPU-Kombiprozessoren – APUs – vor, also die hauseigene Hybrid System Architecture (HSA). Zu den Optimierungen gehören direkt angebundene Speicherchips beziehungsweise RAM-Die-Stacks, wie sie etwa auch Intel, Nvidia und Micron (HMC) entwickeln. In den Präsentationen der FastForward-Projektteilnehmer entdeckt man überhaupt viele Hinweise auf deren jeweilige Forschungsthemen, etwa die Effizienzsteigerung bei AMD oder Intels Multi-Core-Chip SCC oder den Omni-Scale-Interconnect. (ciw)
