

AMD Zen: Weitere Details zu AMDs neuer Prozessor-Architektur
Auf der Hot-Chips-Konferenz in Cupertino erfährt man ein paar weitere Einzelheiten zu Zen.

Auf der Hot-Chips-Konferenz in Cupertino, die am heutigen Montag beginnt, wird AMDs CPU-Architekt Mike Clark weitere Details zur Zen-Architektur vortragen. Die Präsentation dazu, die Clark am Dienstag halten wird, wurde bereits vorab verteilt. Das wichtigste davon hatte AMD allerdings schon vorab auf dem Event parallel zu Intels IDF veröffentlicht.. Demnach ist Zen in der Architektur eine Art Weiterentwicklung des alten K10-Designs, so, wie es vor dem Bulldozer zum Einsatz kam. Auch den Urvater K10 (Barcelona) hatte damals Mike Clark bei AMD entscheidend mitgestaltet.
Als wichtige Erweiterung kam bei Zen wie bei Intel ab Sandy Bridge nun ein spezieller Cache für den bereits dekodierten Code hinzu. Die Befehle aus den Dekodern beziehungsweise dem Microop-Cache gelangen dann in die Microop-Queue. Die Größen von Microop-Cache und -Queue wurden noch nicht bekannt gegeben. In der Queue wird vermutlich ebenso wie bei Intel eine Erkennung kleiner Schleifen stattfinden. Im Trefferfall kann dann das Frontend energiesparend abgehängt werden.

(Bild: AMD)
Nach dem Dispatcher gehen bei Zen die Integer- und Gleitkommabefehle in alter K8/K10-Tradition getrennte Wege, bei Intel kommen sie hingegen in einen gemeinsamen Reorder Buffer. 6 Mikroinstruktionen kann der Dispatcher pro Takt an den Integer-Pfad verteilen, 4 an den Gleitkomma-Pfad. Mit 168 physischen Integer- und 160 Gleitkommaregistern, stehen genügend viele physische Register für das Registernaming zur Verfügung. Dadurch können viele Abhängigkeiten aufgelöst werden. Eines der häufigsten Befehle, der MOV zwischen zwei Registern, kann hier bereits einfach durch Renaming erledigt werden – so machts der Skylake-Prozessor auch. Wie bei jenem gibt es vier parallele Integer-ALUs. Hinzu kommen für die Adressberechnung zwei AGUs.
AVX2 mit 1xFMA
Im Gleitkommapfad befinden sich zwei 128-bittige FP-MUL- und zwei FP-ADD-Einheiten. Die lassen sich für 256-bittiges AVX2 zusammenschalten. Ob Fused Multiply Add (FMA) im Durchsatz mit einem Takt funktioniert, ist noch unklar. Intel hat hingegen ab Haswell gleich zwei 256-bittige FMA-Einheiten vorgesehen. Im Linpack-Benchmark dürfte Zen daher nicht so toll aussehen, eher auf Sandy-Bridge-Niveau liegen.
Wie bei Intel auch, fährt Zen zweifaches „Hyper-Threading“. Das gesamte Out-Of-Order-Fenster, beträgt 192 Instruktionen „on flight“, just so viele wie Haswell (Skylake hat 224).
Der L1-Instruktionscache ist wieder 64 KByte groß, und damit doppelt so groß wie bei Skylake. Der L1-Datencache beträgt bei beiden 32 KByte . Anders als bei Bulldozer arbeitet er wieder mit Write Back. Der gemeinsame L2-Cache ist mit 512 KByte doppelt so groß wie bei Skylake. Alle Caches sollen im Vergleich zu Bulldozer deutlich schneller sein: die L1/L2-Bandbreite doppelt so hoch, die vom L3-Cache gar bis zu fünfmal so hoch.
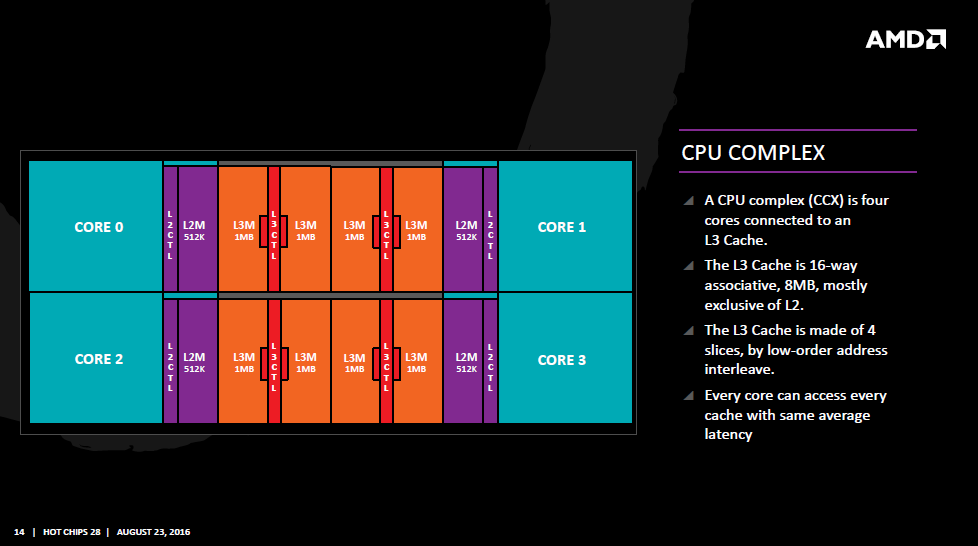
4 Kerne bilden zusammen mit ihren Caches und zwei L3-Cache-Segmenten von jeweils 1 MByte einen CPU-Complex. Den Zeppelin-Chip mit zwei solchen CPU-Komplexen hat AMD noch nicht beschrieben. Von durchgesickerten Roadmaps weiß man, dass er zwei DDR4-Speicherkanäle und 32 PCIe-Lanes haben soll. Der Serverchip Naples mit bis zu 32 Kernen hat dann vier solcher Zeppelin-Dice auf einem Multichipmodul, die über ein weiterentwickeltes Hyper-Transport miteinander kommunizieren. Der gesamte Naples-Chip mit über 5000 Pins bietet dann insgesamt 128 PCIe-Lanes und 8 Speicherkanäle.
(Bild: AMD)
(as)
