

Datenverarbeitung: Apache Flink Table Store 0.2 bietet einheitlichen Speicher
Das Team hinter dem Framework hat mit Flink Table Store einen Speicher zum Aufbau dynamischer Tabellen für die Streaming- und Batch-Verarbeitung vorgestellt.

(Bild: Elli Stattaus, gemeinfrei (Creative Commons CC0))
- Frank-Michael Schlede
Mit Flink Table Store wollen die Entwicklerinnen und Entwickler des Stream-Processing-Frameworks einen einheitlichen Speicher zur Verfügung stellen, der sich zum Aufbau dynamischer Tabellen für die Streaming- und Batch-Verarbeitung in Flink einsetzen lässt. Zudem unterstützt die Software eine schnelle Datenaufnahme und Datenabfragen.
Videos by heise
Vielseitige Methode zum Lesen/Schreiben
Laut der Beschreibung auf der Flink-Webseite handelt es sich bei Flink Table Store um eine neue Art von aktualisierbarem Data Lake, der die folgenden Merkmale aufweist:
- Hoher Datendurchsatz bei guter Abfrageleistung.
- Abfrage mit Primärschlüsselfiltern, die bis zu 100ms schnell sein sollen.
- Streaming-Reads sind ebenfalls auf Lake Storage verfügbar. Lake Storage ist dabei auch mit Apache Kafka integrierbar, um Streaming-Reads auf zweiter Ebene bereitzustellen.
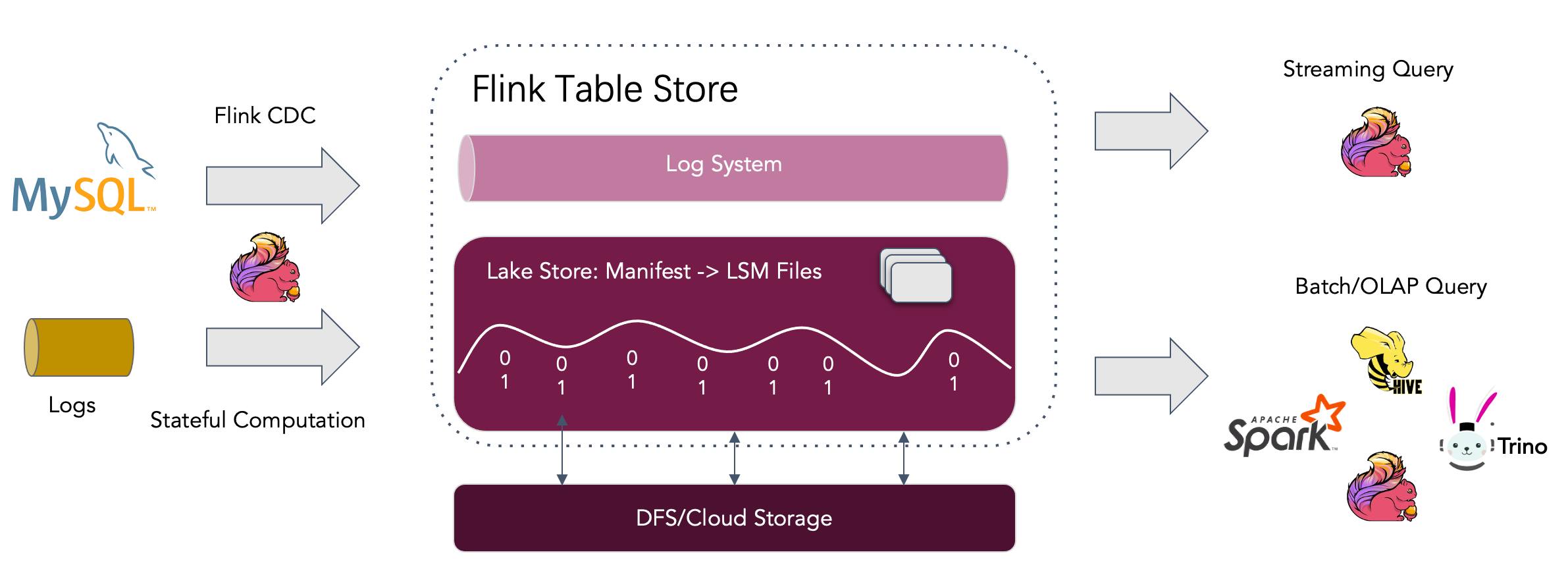
(Bild: Apache Software Foundation)
Flink Table Store verwendet zum Lesen und Schreiben der Daten und zum Durchführen von OLAP-Abfragen eine vielseitige Methode. So können die Daten beispielsweise bei Leseoperationen im Batch-Modus aus historischen Snapshots oder im Streaming-Modus aus dem letzten Offset gelesen werden. Als dritte Möglichkeit unterstützt Flink auch das Lesen inkrementeller Snapshots auf hybride Weise.
Bei Schreibvorgängen unterstützt die Software sowohl die Streaming-Synchronisierung aus dem Änderungsprotokoll von Datenbanken (CDC) als auch das Einfügen/Überschreiben von Offline-Daten im Batch-Modus. Weiterhin unterstützt Table Store nicht nur Apache Flink, sondern auch andere Computing-Engines wie Apache Hive, Apache Spark und Trino.
Entwickler und Entwicklerinnen, die Flink Table Store mit diesen Features einsetzen wollen, finden auf der Apache-Flink-Webseite eine umfassende Anleitung zum schnellen Einstieg.
(fms)
