

Gemini: Google stellt neues KI-Modell vor und zielt auf ChatGPT
Google hat sein neues KI-Modell "Gemini" vorgestellt. Das bislang größte und leistungsfähigste KI-Modell des Konzerns gibt es in drei unterschiedlichen Größen.

(Bild: Google)
Google hat offiziell sein neues KI-Modell "Gemini" in der Version 1.0 vorgestellt. Es kann der Mitteilung zufolge Text, Code, Audio, Bild und Video "gleichzeitig verstehen und nahtlos kombinieren". Googles neue Künstliche Intelligenz soll in drei Größen für unterschiedliche Aufgaben und Systeme konzipiert sein und es kommt laut Google CEO Sundar Pichai "keinen Moment zu früh". Das Modell werde "in Googles Suchmaschine, Werbeprodukte, den Chrome-Browser und mehr auf der ganzen Welt integriert" werden.
Gemini für Smartphone und Unternehmen
Das vorerst in englischer Sprache – weitere sollen folgen – verfügbare KI-Modell erscheint in drei Versionen: "Gemini Nano" soll als effizientes Modell lokal und auf mobilen Endgeräten wie etwa dem Smartphone Google Pixel 8 laufen. Das leistungsstärkere "Gemini Pro" ist laut Google ab sofort für Bard im Einsatz und soll in Kürze in weitere KI-Dienste von Google Einzug halten. Hinter "Gemini Ultra" verbirgt sich demnach das größte und leistungsfähigste Modell für hochkomplexe Aufgaben, ist aber auch das ressourcenintensivste und langsamste. "Ultra" soll im kommenden Jahr erscheinen.
Videos by heise
Entwickler und Unternehmenskunden werden ab dem 13. Dezember über Google Generative AI Studio oder Vertex AI in Google Cloud auf Gemini Pro zugreifen können, berichtet The Verge.
Benchmarks und Training
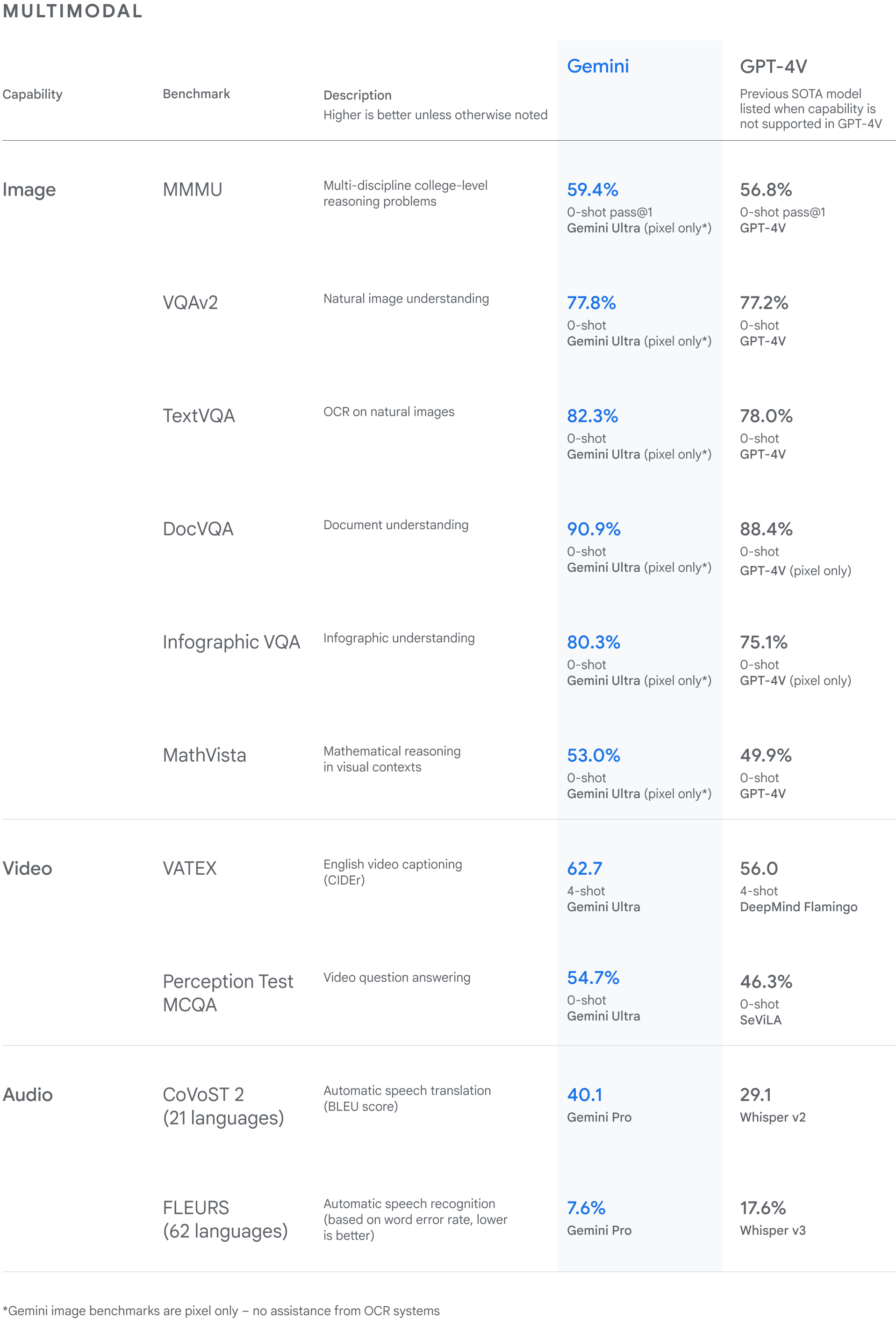
Dadurch, dass Gemini "von Haus aus multimodal und von Beginn an auf verschiedene Modalitäten trainiert wurde", sei es besser als andere Modelle, behauptet Google in seiner Mitteilung. Internen Tests zufolge übertreffe Gemini Ultra bei der Leistung andere Modelle in 30 von 32 akademischen Benchmarks, die in der Forschung und Entwicklung von großen Sprachmodellen (LLM) verwendet werden. Bei den Bild-Benchmarks sei man laut Mitteilung erfolgreicher als bisherige Modelle, und zwar ohne eine Unterstützung durch OCR-Systeme, bei denen Text aus Bildern für die weitere Verarbeitung extrahiert wird.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes Video (TargetVideo GmbH) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (TargetVideo GmbH) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Beim Massive Multitask Language Understanding-Test (MMLU), der 57 Aufgaben etwa aus Mathematik, US-Geschichte, Informatik und Recht umfasst, erziele Gemini Ultra ein Ergebnis von 90 Prozent und übertreffe so menschliche Experten. Im MMMU-Benchmark erreiche das größte KI-Modell Googles mit 59,4 Prozent ebenfalls einen Spitzenwert. Der Massive Multi-disciplin Multimodal Understanding and Reasoning Benchmark (MMMU) wurde entwickelt, um multimodale Modelle in umfangreichen multidisziplinären Aufgaben zu bewerten, die Fachwissen auf College-Niveau und überlegtes Denken aus den Bereichen Kunst und Design, Wirtschaft, Wissenschaft, Gesundheit und Medizin, Geistes- und Sozialwissenschaften sowie Technik und Ingenieurwesen erfordern.
(Bild: Google)
Gemini wurde bereits im Mai dieses Jahres auf der Google I/O angekündigt, hielt sich damals aber noch etwas bedeckt. Laut Pichai und Demis Hassabis, CEO von Google DeepMind, handelt es sich bei Gemini um einen gewaltigen Sprung nach vorn bei einem KI-Modell, das sich letztlich auf praktisch alle Produkte von Google auswirken wird. "Eines der wichtigsten Dinge in diesem Moment", so Pichai, "ist, dass man an einer zugrundeliegenden Technik arbeiten und sie verbessern kann, und dass dies sofort in alle unsere Produkte einfließt."


(bme)
