

Hazelcast Jet erhält neue API für die Batch-Verarbeitung
In der neuen Version 0.5 bringt das Hazelcast-System neben der Java 8 Stream API auch eine Pipeline API mit, die eine Batch-Verarbeitung mit Hilfe von Filtern, Aggregatoren und Joiners erlaubt.

Hazelcast Jet bietet seit der vorangegangenen Version erweiterte Funktionen zur Event-Zeit-Verarbeitung. Die Entwickler des Hazelcast In-Memory Data Grid (IMDG) haben sich in der nun vorgestellten Version 0.5 von Jet auf die Integration einer neuen API konzentriert. Die Pipeline API soll – neben der bereits vorhandenen Java 8 Stream API – vor allem Java-Entwickler ansprechen und erweiterte Fähigkeiten bei der Batch-Verarbeitung bereitstellen, die über den Umfang der Core API hinausgehen.
Die Pipeline API bringt eine Reihe von Tools mit, die als Bausteine für unterschiedliche Batch-Verarbeitungsprozesse herangezogen werden können – darunter Filter, Aggregatoren und Joiner. Dadurch sollen sich Anwendungen für die Sensordatenerfassung im Internet der Dinge, der Fraud Detection in Echtzeit, E-Commerce-Systemen oder Social-Media-Plattformen einfacher erstellen und betreiben lassen.
Um die Fehlertoleranz bei der Verarbeitung paralleler Datenströme zu erhöhen, verfügt Hazelcast Jet ab sofort über eine In-Memory-Snapshot-Funktion. Die regelmäßig erzeugten Snapshots lassen sich im Cluster verteilen und in mehreren Replicas speichern, um höhere Redundanz zu gewährleisten. Den Ausfall von Knoten, Netzwerkpartitionen oder laufenden Jobs kann Jet dadurch einfach kompensieren. Versagt beispielsweise ein Knoten, greift Jet auf den zuletzt gespeicherten Snapshot zurück und startet automatisch alle unterbrochenen Jobs neu. Auf zusätzlichen externen Snapshot-Storage oder ein Distributed File System könne daher verzichtet werden.
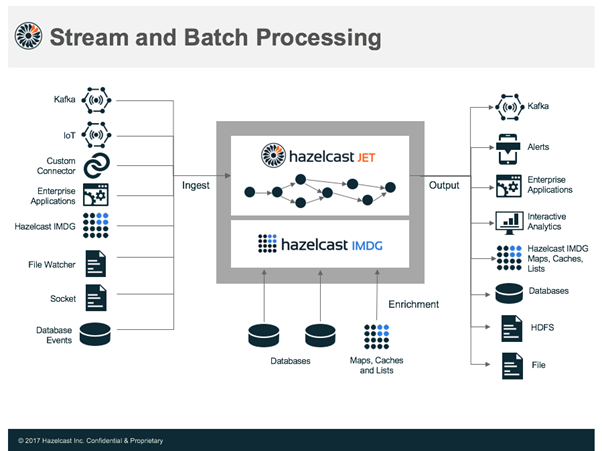
(Bild: Hazelcast)
Ab Version 0.5 soll Jet außerdem nahtlos mit dem Hazelcast IMDG zusammenarbeiten. Anwender profitieren damit auch von Geschwindigkeitsvorteilen bei der Verarbeitung von Daten aus dem Grid-Speicher heraus. Von konkurrierenden Produkten wie Apache Spark und Flink unterscheidet sich Hazelcast Jet durch die sogenannte One-record-per-time-Architektur, die Datensätze direkt verarbeitet und auf Micro Batches verzichtet.
Hazelcast Jet ist unter der Apache-2-Lizenz quelloffen auf GitHub verfügbar. (map)
