

KI erklärt Bilder: Kosmos-1 von Microsoft löst visuelle Rätsel
Microsoft hat ein multimodales KI-Modell vorgestellt, das Bildinhalte erfasst und in natürlicher Sprache Fragen zum Dargestellten beantwortet: Kosmos-1.

(Bild: Gerd Altmann, gemeinfrei)
- Silke Hahn
Microsoft hat Kosmos-1 vorgestellt, ein multimodales großes Sprachmodell (Multimodal Large Language Model, kurz: MLLM) mit visuellen und sprachlichen Fertigkeiten. Kosmos-1 soll Bildrätsel lösen, bildlich dargestellten Text erkennen, visuelle Intelligenztests bestehen und natürliche Sprachanweisungen befolgen können. Die Eigenschaft multimodal bezeichnet die Fähigkeit eines Modells, Input mehrerer unterschiedlicher Wahrnehmungs- und Darstellungsarten zu erkennen und im Kontext sinngemäß zu erfassen.
Einzelne Modalitäten wären etwa geschriebener Text, mündliche Rede, Bilder, Klänge, haptische Eindrücke sowie motorische Bewegungen im Raum. Auch das "Riechen", Interpretieren und Übersetzen olfaktorischer Eindrücke wäre eine Modalität, deren Repräsentation vereinzelt Projekte im Machine Learning erforschen. Kosmos-1 verbindet zwei dieser Modalitäten: neben natürlicher Sprache die Bildebene und deren kontextuelle Verknüpfung.
MLLM: eine Art Weltmodell erstellen
Zurzeit finden die spannendsten Entwicklungen im Bereich Künstlicher Intelligenz an der Schnittmenge der unterschiedlichen Modalitäten statt, die inzwischen sukzessive zusammengeführt werden: Für sich genommen sind diese Fähigkeiten in Machine-Learning-Modellen nicht neu. So gab es bislang Modellklassen wie DALL·E von (Microsoft-)OpenAI, Stable Diffusion oder Midjourney, die auf Textanweisung Bilder erstellen, und Textgeneratoren wie die nun zahlreicher werdenden KI-Chatbots unterschiedlicher Anbieter, die Sprache auf menschenähnlichem Niveau verarbeiten, "verstehen" und erzeugen. Neu ist die zunehmende Verbindung mehrerer solcher Modalitäten in einem Modell. Die Rede ist dann manchmal von Weltwissen und "Weltmodellen", da diese künstlichen neuronalen Netzwerke zunehmend Facetten unserer Welt abbilden. Den Begriff World Model greift auch das Microsoft-Team in seinem Bericht auf, um Kosmos-1 zu beschreiben (die Namensgebung der neuen Modellreihe ist entsprechend gewählt).

(Bild: Microsoft)
Computervision mit den breit gefächerten Fähigkeiten großer Sprachmodelle zu verbinden, gilt als Schritt hin zu transformativer Künstlicher Intelligenz, die mit statistischen Methoden zunehmend in Bereiche menschlicher Wahrnehmungsfähigkeit vordringt. Auch das Erzeugen von Bildern, Stimmen, Klang und Musik auf Textanweisung fällt in diesen Bereich. Dazu hatte Microsoft-OpenAI Anfang des Jahres VALL·E vorgestellt, Google trat mit AudioLM und MusicLM hervor, und zahlreiche weitere Projekte im Bereich der Klang- und Sprachsynthese sowie -Analyse und Audio-Erzeugung mittels KI treten dieses Jahr in Erscheinung.
Videos by heise
Fähigkeiten zusammenführen für Multitasking
Anbieter wie Google und DeepMind forschen ebenfalls stark in Richtung Multimodalität: Die Google-Tochter DeepMind hatte im Mai 2022 den Multitasking-fähigen KI-Agenten Gato vorgestellt. Gato greift räumliche und haptische Aspekte auf, die perspektivisch das Steuern eines Roboters im Raum ermöglichen könnten. Beworben hatte DeepMind den Agenten mit dem Symbolbild einer Roboterkatze, um Multitasking geht es bei den verstreuten Ansätzen. Um natürlicher Intelligenz nahezukommen, bedarf es mehr "Wahrnehmungs"-Fähigkeiten als lediglich der Sprache, und auch die Orientierung sowie das Befolgen von Anweisungen im Raum mit haptischen und motorischen Elementen dürfte langfristig für viele Bereiche wie die Industrie von Belang sein. Beim Training dieser Modelle kommt es zu "cross-modalem" Wissenstransfer, wenn etwa sprachlich Informationen auf den bildlichen oder haptischen Bereich übertragen werden.
Forschungsunternehmen wie der Microsoftpartner OpenAI streben laut eigenen Angaben nach "allgemeiner künstlicher Intelligenz" (AGI). Wer in Richtung solch einer weit gefassten General-Purpose-KI zielt, arbeitet zurzeit daran, verschiedene Wahrnehmungskanäle in Modellen zu kombinieren. Multimodalität ist dabei keine Erfindung von Microsoft oder OpenAI. Andere Anbieter wie das deutsche KI-Unternehmen Aleph Alpha haben mit MAGMA und ihrer Luminous-Serie bereits Modelle vorgestellt, die Bilder und Texte in jeglicher Kombination und im Kontext "verstehen", erklären, auswerten und weiterbearbeiten. Deren Modellfamilie ist ein "MLLM" im von Microsoft-Team verwendeten Sinne.
(Bild: Microsoft, "Language is not all you need: Aligning Perception with Language Models")
Kosmos-1: Trainingsdaten und Raven-IQ-Test
Die Trainingsdaten von Kosmos-1 umfassen laut Microsoft-Team multimodale Datensammlungen wie Textcorpora, Wort-Bild-Paare und Material, das Bild und Text kombiniert. Auf der Bildseite kamen unter anderem LAION-Datensätze zum Zuge, wobei offenbar nur englischsprachig gelabelte Bilder Berücksichtigung fanden. Auf der Textseite waren es unter anderem Auszüge aus einer 800 GByte großen englischsprachigen Textbasis namens "The Pile" und den bei großen Sprachmodellen üblichen Common Crawl aus dem Internet. Details zu den Trainingsdaten stehen im Anhang des arxiv-Papers.
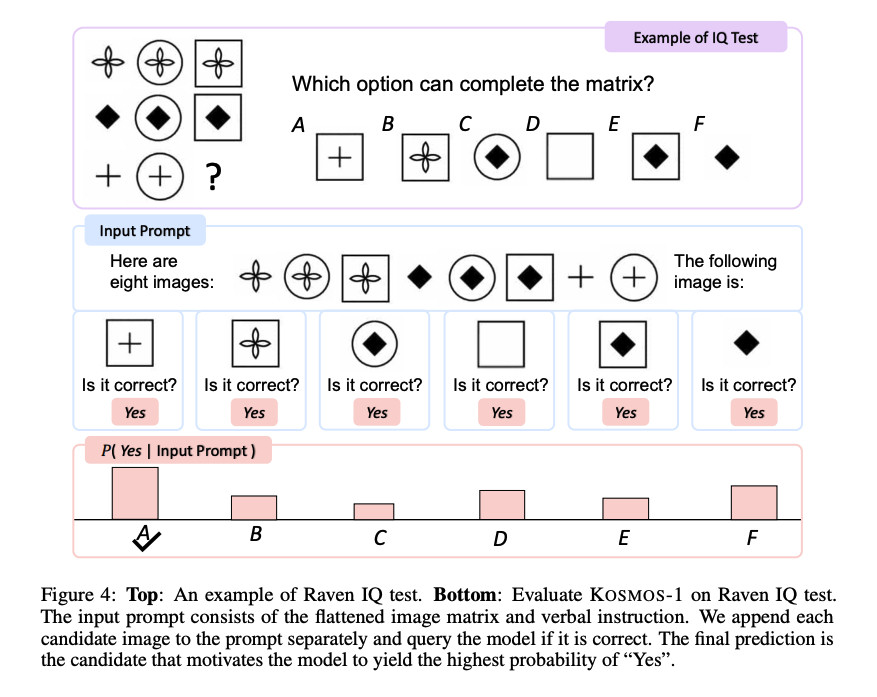
Das Team habe das fertig vortrainierte Modell verschiedenen Tests unterzogen, ist dem Bericht zu entnehmen, bei dem es gute Ergebnisse im Klassifizieren von Bildern, Beantworten von Fragen zu Bildinhalten, dem automatisierten Labeln von Bildern, optischer Texterkennung sowie Aufgaben der Spracherzeugung erzielt habe. Auffällig ist laut Team dabei das eher mäßige Abschneiden von Kosmos-1 bei Raven's Progressive Reasoning (RPR), einer Art visuellem IQ-Test. Dabei müssen Testteilnehmer Folgen von Formen logisch sinnvoll ergänzen. Hier lag Kosmos-1 nur in 22 Prozent der Fälle richtig. Das Team sei noch dabei, die Gründe dafür zu untersuchen, heißt es im Paper.

Bildliches Reasoning vertiefen
Bildliches Reasoning, also das Ziehen von Schlüssen über Bilder ohne Zwischenschritt über die Sprache, scheint hierbei ein Schlüssel zu sein, wie die Forschungsteams in ihren Berichten darlegen. Der aktuelle Forschungsbeitrag von Microsoft "Language Is Not All You Need: Aligning Perception with Language Models" bietet Einblick in die Techniken, die beim Zusammenführen der visuellen und sprachlichen Fähigkeiten des Modells zum Einsatz kamen.
2021 erschienen grundlegende Vorarbeiten zu dem Thema: DeepMind brachte "Multimodal Few-Shot Learning with Frozen Language Models" heraus (Tsimpoukelli et. al.), und Heidelberger Forscherinnen und Forscher aus dem Umfeld der damaligen ComputerVision Group (der unter anderem auch Stable Diffusion entspringt) sowie von Aleph Alpha veröffentlichten eine Methode, mit der sich generative KI-Modelle um multimodale Fähigkeiten anreichern (augmentieren) lassen: "MAGMA – Multimodal Augmentation of Generative Models through Adapter-based Finetuning". heise Developer hatte über das zugehörige KI-Forschungsmodell berichtet, dessen Quellcode, Modellkarte und Gewichte seit letztem Frühjahr als Open Source auf GitHub zur Verfügung stehen.
(sih)