China und Japan dominieren. Hier der in Tanks mit Flüssigkühlung untergebrachte japanische Gyoukou mit 8 Pezy-SC2-Beschleunigerkarten pro Node.
(Bild: ExaScaler)
Lesezeit:
7 Min.
Von
Andreas Stiller
Inhaltsverzeichnis
So hatte sich das der amerikanische Präsident Donald Trump sicherlich nicht vorgestellt: Nur wenige Tage nach seinem Besuch bei den chinesischen Freunden zeigt die zum Auftakt der Supercomputing 2017 (SC17) in Denver veröffentlichte 50. Top500-Liste, dass China die USA nicht nur in der Wirtschaft, sondern auch bei den Supercomputern an die Wand spielt.
Weiterlesen nach der Anzeige
Dank 94 neuer Systeme, fast alles Industriesysteme von Inspur oder Sugon, die im Mittelfeld zwischen Platz 100 und 300 landeten, können die USA mit nur 19 Neulingen jetzt wieder wie im Juni 2016 lediglich "America Second" skandieren. Im Juni 2017 hatten sich die Amerikaner die Spitzenposition zwar zurückgeholt, aber eben nur kurz. Sowohl bei der Stückzahl (202 zu 143) als auch bei der aggregierten Performance (35 % zu 30 %) liegt China deutlich vorne.
Top Three
Auf dem Treppchen der drei schnellsten Rechner stehen dabei dieselben drei nicht-amerikanischen Systeme wie schon in der letzten Liste vom Juni 2017. Mit 93 PFlops dominiert weiterhin der chinesische Sunway TaihuLight vor dem Tianhe 2, der noch in alter Xeon-Phi-Bestückung mit 33 PFlops in der Liste steht, die inzwischen aber zum großen Teil durch schnellere Beschleuniger ersetzt worden sind. Danach folgt der schnellste Europäer, der schweizerische Piz Daint (19,6 PFlops), ein Cray-System mit Nvidia Tesla P100.
Und dann hat sich jetzt auch noch der japanische Rechner Gyoukou mit ZettaScale-2.2-Architektur auf Platz vier geschoben, der aufgerüstet auf fast 20 Millionen Rechenkerne durch den Beschleuniger Pezy SC2 auf 19,1 PFlops kommt. Er steht in Tanks mit Flüssigkeitskühlung an der Agentur für Meeres- und Erdforschung, die früher mal den "Earth Simulator" beheimatete. Als Allzweck-Prozessor kommt hier interessanterweise der sparsame Xeon D-1571 zum Einsatz.
Die amerikanische Speerspitze, der Veteran Titan an den Oak Ridge National Labs, ist mit seinen 17,6 PFlops somit auf Platz 5 verdrängt; so schlecht standen die Amerikaner in den 25 Jahren Top500-Liste noch nie.
Von dem mit Power9 und Nvidia Volta bestückten Coral ist noch nichts zu sehen und der einst mit Xeon Phi Knights Hill für 2018 vorgesehene Aurora ist auf 2021/22 verschoben und soll auch auf eine andere Architektur wechseln.
Neulinge
Weiterlesen nach der Anzeige
Richtig große Neusysteme gab es diesmal gar nicht. Der Schnellste ist der Tera 1000 von Bull bei der französischen Atomenergie-Behörde, der in erster Ausbaustufe mit knapp 5 PFlops Platz 23 erreicht.
Deutschland trägt mit keinem einzigen neuen System dazu bei, während Japan (+7), sowie die europäischen Nachbarn wie Frankreich und Großbritannien (je +3), die Niederlande (+2) und die Schweiz (+1) zugelegt haben.
Allerdings findet man etliche bemerkenswerte Aufrüstungen beziehungsweise Erweiterungen, neben dem schon erwähnten japanischen Gyoukou vor allen den um 14.144 Xeon-Phi-Knoten erweiterten Trinity (nun 14,1 TFlops, Platz 7) und den Stampede 2 Phase 2 des Texas Advanced Computing Center (TACC), der knapp 1500 Knoten mit Xeon Platinum 8160 (Skylake-SP) dazubekommen hat und nun mit 8,3 PFlops auf Platz 13 liegt.
Mischlinge
Unter den erweiterten Systemen sind auch einige deutsche. Hier ragen der Jureca des Jülicher Supercomputer Centers und der Mogon II der Johannes Gutenberg-Universität Mainz heraus, beides Mischsysteme verschiedener Hersteller und Prozessorgenerationen.
Die Jülicher haben mit Hilfe von Intels russischen Linpack-Spezialisten das Kunststück vollbracht, das mit Intel-Haswell-Prozessoren und Nvidia-Tesla-GPUs bestückte System von T-Platform mit dem Xeon-Phi-Booster von Dell mit ordentlicher Effizienz zu verheiraten, wobei sie auch noch mit EDR-Infiniband hier und Omnipath da zu kämpfen hatten – das geht also. Mit 3,8 PFlops konnte der Booster den Jureca auf Platz 29 boosten.
Der Spitzenreiter Sunway TaihuLight (China) (Bild: Fu H H, Liao J F, Yang J Z, et al.)
Die Mainzer hatten es ebenfalls nicht ganz leicht, das im letzten Jahr aufgestellte Megware-System auf Broadwell-Basis mit AVX2 mit dem neu hinzugekommenen System von NEC mit Xeon Gold 6130 und AVX512 zum Fliegen zu bringen. Mogon II ist somit das zweite deutsche System in der Liste mit Intels neuem Xeon SP -- nach dem Quriosity von HPE bei BASF. Mit fast 2 PFlops auf Platz 65 ist er Deutschlands schnellster Uni-Rechner und erreicht in der „akademischen Liste“ weltweit immerhin Platz 13.
Insgesamt stehen jetzt über die Hälfte aller Systeme in Asien (251) vor Nordamerika (149) und Europa mit 93.
Dominanzen
Genau 100 Prozent der 136 neu in die Liste eingezogenen Systeme – 30 Prozent mehr als beim letzten Mal – sind mit Intel-Prozessoren bestückt. Vergleichsweise wenig Scalable Xeons sind dabei (13) und dem Xeon Phi bleibt mit gerade mal 2 Neusystemen (ohne den Booster in Jülich) eine Nischenrolle.
Mit 24 wurden noch erstaunlich viele alte Haswell-Rechner installiert, es dominiert aber Broadwell mit 94. Von Power9, ARM und AMD Epyc ist nichts zu sehen. Insgesamt halten sich in der Liste noch ein paar alte Bulldozer-, Power8-, BlueGene- und SPARC-Systeme; Intels Anteil steigt von 92,8 auf 94,2 Prozent.
Bei den Beschleunigern baut Nvidia seine Führung weiter aus. 101 Systeme sind mit Beschleunigerkarten bestückt, 10 mehr als zuvor. 86 verwenden Nvidia Tesla, 12 Xeon Phi und 5 Pezy.
Bei den Herstellern machten sich die vielen Neusysteme von Inspur und Surgon bemerkbar, die anderen haben entsprechend verloren. HPE bleibt aber mit 123 vorne (zuvor 144), vor Lenovo mit 81 (88), Inspur mit 56 (20), Cray mit 53 (57) und Sugon mit 51 (44).
Berücksichtigt man die Leistungsfähigkeit, so ist weiterhin Cray mit 19,5 Prozent der Gesamtperformance vorne, vor HPE mit 15,2 Prozent und dem Hersteller des Spitzensystems TaihuLight NRCPC mit 11,1 Prozent.
Die Gesamtperformance ist dabei gegenüber der Liste vom Juni um 27 Prozent auf 845 PFlops gestiegen – weniger als 1 Exaflops. Man braucht jetzt mindestens 548 TFlops, um überhaupt in die Liste zu kommen.
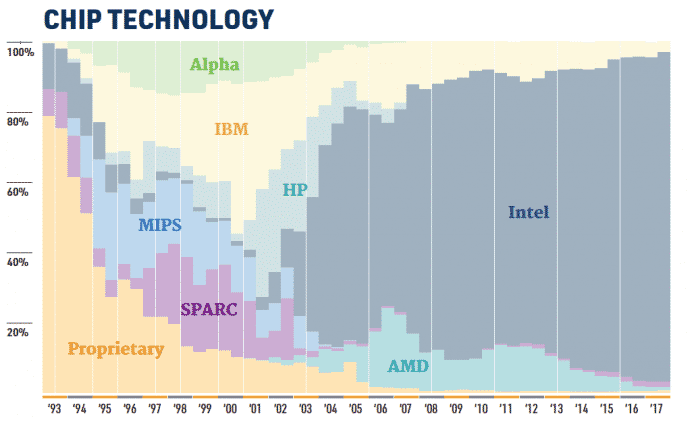
Wer beherrscht hier wohl den Markt?
(Bild: Top500)
Green500 und HPCG
Die 50. Liste enthält auch die Ergebnisse der Green500 und des HPCG-Benchmarks, sofern eingereicht. In der Energieeffizienz setzt dabei der Pezy SC2 neue Maßstäbe. Damit bestückt liegen drei japanische ZettaScale-Systeme mit bis zu 17 GFlops/Watt vorne. Auf Platz 4 folgt dann der DGX SaturnV mit Nvidia V100 (Volta) mit 15,1 GFlops/Watt.
Für den im Wesentlichen von der Speicherbandbreite abhängigen HPCG-Benchmark haben bislang insgesamt nur 61 Betreiber Werte eingereicht, darunter nur eine Handvoll Neusysteme. Unter den Top 10 hat sich gegenüber der letzten Liste somit nichts geändert, es führt der japanische K-Computer mit 603 TFlops vor dem chinesischen TaihuLight mit 580 und dem amerikanischen Xeon-Phi-System Trinity mit 542 TFlops.