

Die Verknüpfung von Data Analytics und Supercomputing
Die jüngsten Hacker-Angriffe auf Telekom-Router in ganz Deutschland haben erneut eine Debatte über neue Standards in der Cybersicherheit ausgelöst. Selbst wenn der ganz große Schaden ausblieb, stellt sich die Frage, wie sich derartige Angriffe früher erkennen lassen. Hier können High Performance Data Analytics eine Lösung sein.

- Dominik Ulmer
Fest steht, dass der Faktor Zeit entscheidend ist. Bei der Telekom wie auch in vielen anderen Fällen sind Daten innerhalb kürzester Zeit oder sogar in Echtzeit zu verarbeiten und zu analysieren, um überhaupt richtungweisende Entscheidungen treffen beziehungsweise Zusammenhänge erkennen zu können. In diesen Fällen wird Big Data zu Fast Data und braucht Infrastrukturen, die Datenberge schnell verständlich machen und in einer skalierbaren Umgebung erfolgreich anwendbar sind. Ein Cloud-Angebot reicht hier oft nicht mehr aus, denn schnelle Einblicke benötigen entsprechend große Rechenleistung. Sind dann noch geringe Latenzzeiten nötig, verschmilzt Big Data mit Supercomputing. Experten sprechen hier von High Performance Data Analytics (HPDA) oder von der Konvergenz von Big Data und Supercomputing.
Der Begriff Konvergenz
In Branchenkreisen ist diese Konvergenz seit circa 2011 ein Thema. Das hängt mit der Entwicklung des weltweiten Datenaufkommens und der Tatsache zusammen, dass herkömmliche Techniken bei bestimmten Algorithmen schlicht an ihre Grenzen gestoßen sind. Folglich kam die Frage auf, ob sich Supercomputing-Techniken nicht auf den Data-Analytics-Bereich übertragen lassen. Seither finden regelmäßig Vorträge zum Thema statt, seit 2014 tauschen sich Experten darüber auch auf der Technologie-Plattform Big Data Value Association aus, welche die Europäische Kommission bei der Umsetzung technischer Projekte mit Ausschreibungen und Konzepten unterstützt. Mittlerweile existieren die ersten greifbaren Anwendungen, etwa für den Bereich Deep Learning beziehungsweise Machine Learning.
Letzteres hat in den letzten 18 bis 24 Monaten deutlich an Bedeutung gewonnen, was unter anderem auf die Beschäftigung mit breit angelegten kommerziellen Anwendungen wie Spracherkennung, selbstfahrenden Autos und neuronalen Netzen zurückzuführen ist. Erst jetzt können die großen Mengen an Daten überhaupt zusammenfließen, die etwa für das Training eines neuronalen Netzes nötig sind.
Im Grunde verändert Big Data die Art und Weise, wie Supercomputer genutzt werden, und Supercomputer wiederum beeinflussen den Umgang mit Big Data. Sei es nun bei der Analyse von Baseballspielen, Wetter- und Klimamodellierungen mithilfe von IoT-Sensordaten oder auch der Analyse von Social-Media-Daten zu einem bestimmten Thema.
Cloud und Big Data
Cloud oder nicht Cloud?
Ob für die genannten Anwendungsfälle auch eine Cloud-Anwendung in Frage kommt, hängt von mehreren Faktoren ab. Zum einen der finanzielle Aspekt, nämlich im Hinblick auf die sogenannte "Utilisation": Wird aufgrund vieler Workloads und Anfragen ein gewisser Auslastungsgrad überschritten, ist eine On-Premise-Anwendung schlicht billiger.
Der zweite Aspekt betrifft das Transferieren von Daten. Ist eine gewisse Datenmenge erreicht, das heißt, bewegt sie sich im Terabyte- oder Petabyte-Bereich, kommen Anwender mit der Cloud nicht mehr weiter. Ein gutes Beispiel hierfür – und somit für die Big-Data-HPC-Konvergenz – ist Petroleum Geo-Services (PGS). Das norwegische Unternehmen ist im Erdöl- und Erdgassektor tätig und bietet weltweit meeresgeophysikalische Dienste zur Entdeckung von Erdölfeldern an. Um seismische Daten zu analysieren und künftig detailliertere Aufnahmen und mehrdimensionale Modelle der geologischen Strukturen am Meeresgrund zu ermöglichen, setzt das Unternehmen nun auch auf Machine-Learning-Algorithmen. Die hierbei generierten Daten bewegen sich aber in der Größenordnung mehrerer Zehner von Petabytes. Das kann keine Cloud-Anwendung.
Zudem spielen in manchen Branchen Geschwindigkeit und Latenzzeit die entscheidende Rolle, beispielsweise im High Frequency Trading, im Bereich Maschinensteuerung oder auch bei der Cyber-Überwachung wie im Fall Telekom.
Drittens sind schließlich regulatorische Aspekte wie Datensicherheit zu nennen: Eine Versicherung etwa wird Daten nur ungern in die Cloud verlagern wollen. Es ist letztlich eine Frage des Anwendungs- und Geschäftsszenarios, ob eine Cloud-Anwendung dazu passt oder nicht. Grundsätzlich lässt sich feststellen, dass die Cloud gegenüber einer Data-Analytics-Plattform auf Hardwarebasis Schwächen bezüglich Latenzzeit und Datenbewegung hat.
Anwender müssen also abwägen, wie schnell sie Ergebnisse zu bestimmten Abfragen brauchen und wie viele Daten sie verarbeiten müssen. Liegt die Auslastung der Analytics-Plattform mit Supercomputing-Techniken unter 50 Prozent, lohnt sich die Investition meist nicht. Dann ist ein Cloud-Service sinnvoller. Wenn ein Anwender jedoch sofort Ergebnisse braucht, die Maschine regelmäßig ausgelastet wird, es auf eine möglichst geringe Latenzzeit sowie einen kurzfristigen Turnaround ankommt und geschäftskritische Anwendungen betroffen sind, sollte über eine lokale Data-Analytics-Anwendung nachgedacht werden.
Dimensionen von Big Data
Unter dem Begriff Big Data ist in den letzten Jahren viel subsumiert worden. Im Endeffekt sind zwei Dimensionen entscheidend: erstens das Data Management, das heißt, wohin man die Daten schiebt. Zweitens: Wie lässt sich Sinnvolles in den Daten finden? Angefangen hat alles mit dem MapReduce-Algorithmus von Google und Hadoop. Auf einmal war verteiltes Rechnen für alle zugänglich. Allerdings kostete die Datenverarbeitung über die auf hohe Verfügbarkeit ausgelegten, dreifach redundanten Server viel Zeit und stellte eher Ballast dar. Um in puncto Geschwindigkeit einen Schritt nach vorne zu machen, entstand dann Apache Spark. Anwender sollten nicht mehr nur Korrelationen zur Verfügung haben, sondern Zusammenhänge innerhalb unstrukturierter Daten aus verschiedensten Quellen erkennen können.
Um große Mengen unstrukturierter Daten analysieren zu können, werden heute überwiegend Graphenanalysen eingesetzt. Sie machen Zusammenhänge erkennbar, die vorher nicht bekannt waren. In der Medizin lassen sich Graphen beispielsweise dazu einsetzen, über die Analyse von Nebenwirkungen und deren Verknüpfung mit anderen Patientendaten Hinweise zu erhalten, also wie existierende Medikamente für andere Krankheiten wiederverwendet werden können.
Graphdatenbanken finden, genauso wie Spark und Hadoop, in zunehmend mehr Industrien Verwendung, sind aber schwer zu parallelisieren. Das liegt daran, dass als Voraussetzung für die sogenannte "Locality", also das parallele Rechnen auf verschiedenen Knoten, die Struktur der Daten bekannt sein muss. Das ist aber bei unstrukturierten Daten eben nicht der Fall. Herkömmliche Cluster haben demnach nicht die nötige Skalierbarkeit, um schnelle Graphenanalysen zu ermöglichen. Auf normalen Rechnern können Graph Analytics deshalb mehrere Stunden oder sogar Tage dauern.
Als Methode im Zentrum der Aufmerksamkeit im Bereich Big Data standen in letzter Zeit Machine Learning beziehungsweise Deep Learning. Hierbei ist zu unterscheiden, ob es sich um rechenintensive Tasks zum Trainieren des neuronalen Netzes oder reine Abfragen handelt. Die Abfragephase ist nicht rechenintensiv. Das können zum Beispiel einfach Kaufvorschläge eines Online-Händlers basierend auf getätigten Käufen sein.
Das Training eines neuronalen Netzes hingegen ist rechenintensiv. Die Fragen sind, wie viele Daten verschoben werden müssen, wie tief das neuronale Netz ist, wie oft Trainings anfallen, wie oft Updates des neuronalen Netzes anstehen et cetera. Auf der NIPS-Konferenz 2016 (Neural Information Processing Systems) in Barcelona wurden kürzlich die Ergebnisse einer Zusammenarbeit zwischen Microsoft, Cray und dem Schweizer Nationalen Hochleistungsrechenzentrum CSCS gezeigt. Dabei wurde das Microsoft Cognitive Toolkit auf die Architektur des schnellsten europäischen Supercomputers "Piz Daint" portiert und demonstriert, wie sich die Dauer rechenintensiver Machine-Learning-Aufgaben von Wochen und Monaten auf Minuten bis Stunden reduzieren ließ.
Big Data und Supercomputer
Big Data und Supercomputing wachsen zusammen
Um den grundsätzlichen Problemen Datenmanagement, Analysegeschwindigkeit und Komplexität zu begegnen, arbeitet man an neuen Analytics-Ansätzen. Eine Möglichkeit ist die Kombination aus Supercomputing und Data Analytics in einer Hardware-Appliance mit HPC- und Big-Data-Software. Nutzern stehen dadurch einerseits die Rechengeschwindigkeit sowie Skalierungs- und Durchsatzraten eines Supercomputers und andererseits eine standardisierte Enterprise-Hardware sowie eine Open-Source-Softwareumgebung (etwa OpenStack für das Datenmanagement und Apache Mesos für die dynamische Konfiguration) zur Verfügung. Im Gegensatz zur oft zitierten "Schatten-IT", bei der unterschiedliche Cluster Architekturen jeweils für verschiedene Workloads eingesetzt werden und damit ein Problem für die Integration von Applikationen darstellt, wird mit diesem Modell auf die Verwendung einheitlicher und offener Quasi-Industriestandards gesetzt. Das ermöglicht die zeitgleiche Durchführung anspruchsvoller Analyse-Workloads – sei es Hadoop, Apache Spark oder Graph – auf einer einzigen Plattform.
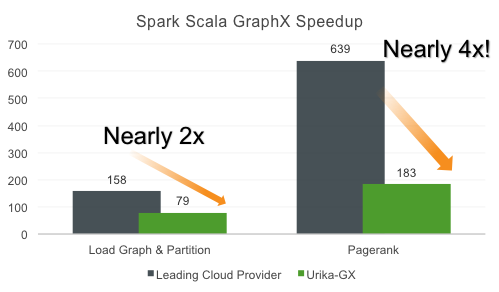
Bei einem Benchmark, bei dem die Performance von AWS EC2 mit jener der Cray Urika-GX Data Analytics Appliance verglichen wurde, lagen die Ergebnisse bei Graph-Workloads (Graph Load/Partitioning) bei der Urika-GX zwei- beziehungsweise viermal schneller vor (PDF). Der sogenannte LUBM25K-Graph-Benchmark zeigte sogar eine zwanzigfache Performancesteigerung gegenüber anderen Big-Data-Plattformen.
Anwendern im Enterprise-Bereich steht durch die Fusion von HPC-Technik und Open-Source-Software ein neues Instrument zur Verfügung, um schnell Einblicke in riesige Mengen unstrukturierter Daten zu bekommen.
HPC-Komponenten für Data Analytics
Ein wichtiges Element dieser Fusion ist im Fall von Cray der proprietäre Aries-Verbindungschip ("Aries Interconnect"), der auch in den Supercomputern eingesetzt wird. Dieses interne Netzwerk ist auf niedrige Latenz sowie hohe Bandbreiten ausgelegt und auf hohe Messaging-Raten ausgerichtet. Netzwerkabhängige Workloads wie Spark oder graphenbasierte Analysen laufen schneller, da sich die Datenpakete ständig einspeisen lassen ("in-flight"), ohne erst eine Rückmeldung abwarten zu müssen. Darunter versteht man die Fähigkeit des Netzwerks, große Mengen an Datenpaketen gleichzeitig auf dem Netz aktiv zu halten. Das ist eine Voraussetzung, um die sogenannte "einseitige" Kommunikation zu ermöglichen, bei der Sender nicht mehr auf eine Bestätigung der Empfänger warten, bevor sie das nächste Datenpaket verschicken, womit sich Kommunikationsströme überlappen lassen. Das drückt sich in hohen Raten an kleinen Datenpaketen auf dem Netz aus.
Zudem präsentiert der Aries-Chip den verteilten Hauptspeicher der einzelnen Rechnerknoten als einen globalen Adressraum und unterstützt sogenannte Atomic Memory Operations, mit denen sich nichtlokale Speicheradressen nutzen lassen. Der Aries-Verbindungschip (PDF) ersetzt Verbindungen per Ethernet- oder InfiniBand-Knoten, sodass die Notwendigkeit entfällt, eine Netzwerk-Fabrik zwischen einzelnen Knoten aufzubauen, die unnötig Zeit, Support und Kapital verschlingt.
Die Konvergenz von Supercomputing und Big Data in der Wissenschaft
Ein Projekt, das maßgeblich von der HPC-Big-Data-Konvergenz profitieren wird, ist das Human Brain Project des Jülich Supercomputing Centre und der Eidgenössischen Technischen Hochschule Lausanne. Hierbei handelt es sich um eine 10-Jahres-Initiative, die das gesamte Wissen über das menschliche Gehirn zusammenfassen und mittels computerbasierter Modelle und Simulationen die dort ablaufenden Prozesse nachbilden soll. Im Mittelpunkt des Projekts steht unter anderem die Entwicklung von Speicherlösungen, die auf die immensen Datenmengen ausgelegt sind, die im Zuge einer Hirnsimulation anfallen.
Auch die Argonne Leadership Computing Facility in den Vereinigten Staaten arbeitet mit datenzentrierten Anwendungen, zum Beispiel in den Bereichen Life Science, Materialwissenschaften und Machine Learning. Das Institut widmet sich der Erforschung und Optimierung verschiedener Rechenmethoden, welche die Grundlage für datengestützte Erkenntnisse in allen wissenschaftlichen Disziplinen bilden. Das Projekt Aurora hat zum Ziel, bis Ende 2018 eine neue, datenzentrische Supercomputer-Architektur zu entwickeln und zu installieren, die sich durch großen Gesamthauptspeicher und extreme Memory-Bandbreiten auszeichnet.
Ein weiterer Anwendungsfall ist die Analyse von Genomdaten und die Genomsequenzierung in der Krebsforschung, zum Beispiel beim Non-Profit-Forschungsinstitut Broad Institute in den Staaten, das sich um ein größeres Verständnis von Krankheiten und den Fortschritt bei deren Behandlung bemüht. In einem Benchmark-Test übertrug das Institut sein Genom-Analyse-Toolkit GATK4, das zuvor in der Cloud lief, eins zu eins auf die Urika-GX-Plattform und erhielt die Recalibration-(QSR-)Ergebnisse aus dem Analyse-Toolkit und der Spark-Pipeline mehr als viermal schneller als zuvor: in neun statt 40 Minuten (PDF).
Fazit
Um das Potenzial von Big Data effektiv nutzen zu können und auch dessen Risiken abzudecken, werden neue Ansätze benötigt, große Mengen an Daten schnell aufnehmen, analysieren und speichern zu können. Das erfordert die Konvergenz von Supercomputing und Big Data Analytics sowie die Verwendung einer einheitlichen Plattform für die Aufnahme, Analyse und das Abfragen von Daten.
Zentrale Frage ist das Geschäftsszenario: Können es sich Unternehmen, Organisation oder Forschungsinstitut et cetera leisten, auf Ergebnisse zu warten, oder brauchen sie Resultate sofort? Die Tendenz geht ganz klar dahin, dass zunehmend mehr Daten vorhanden sind, die in Echtzeit verarbeitet werden sollen. Um sich für kritische Entscheidungen in unbekannten Situationen vorzubereiten und bislang ungelöste Fragen zu beantworten, spielt die Latenzzeit damit eine zunehmend größere Rolle.
Dominik Ulmer
ist seit 2013 für Cray tätig. Vorher leitete er das Swiss National Supercomputing Centre (CSCS) – zuerst in der Rolle des COO, dann als Geschäftsführer. Unter seiner Leitung wurde eines der weltweit größten Supercomputingzentren aufgebaut, das eines der Top-10 HPC-Systeme hostet. Auch dient Ulmer seit 2012 der Europäischen Kommission als Experte und Gutachter für High Performance Computing.
(ane)
