

Herausforderungen und Fallstricke bei der Entwicklung für Multi-Core-Systeme
Parallelisierung von Anwendungen verspricht bessere Performance und kürzere Laufzeiten. Bei der Programmierung gilt es aber, einige Hürden zu überwinden.

- Sebastian Bindick
Parallelrechner finden sich heutzutage in zahlreichen Mehrkernprozessorsystemen vom Smartphone über Tablets und PCs bis hin zu Industriesteuerungsanlagen und Computerclustern im Rechenzentrum. Die Nutzung dieser Rechenleistung stellt große Herausforderungen an die Softwareentwicklung – zudem sind parallele Programmierparadigmen zu berücksichtigen.
Anders als bei klassischen Anwendungen mit sequenziellem Programmfluss werden beim Parallel Computing mehrere Teilaufgaben gleichzeitig ausgeführt. Dies wird auch als Nebenläufigkeit (concurrency) oder Parallelität (parallelism) bezeichnet. Die Vorteile liegen auf der Hand: Durch eine parallele Bearbeitung lassen sich Mehrkernsysteme effizient auslasten und komplexe Problemstellungen in angemessener Zeit lösen. Allerdings gehen damit auch eine deutlich höhere Komplexität und eine schlechtere Nachvollziehbarkeit des Programmcodes sowie eine höhere Fehleranfälligkeit einher.
Dieser Artikel geht auf Konzepte, Techniken und Herausforderungen paralleler Programmierung mit Java-Threads ein und will Antworten auf die folgenden Fragen geben:
- Wie lässt sich eine hohe Auslastung über viele CPU-Kerne erreichen?
- Wie ist mit Race Conditions und Data Races umzugehen?
- Welche Fallstricke lauern beim Einsatz von Synchronisationstechniken?
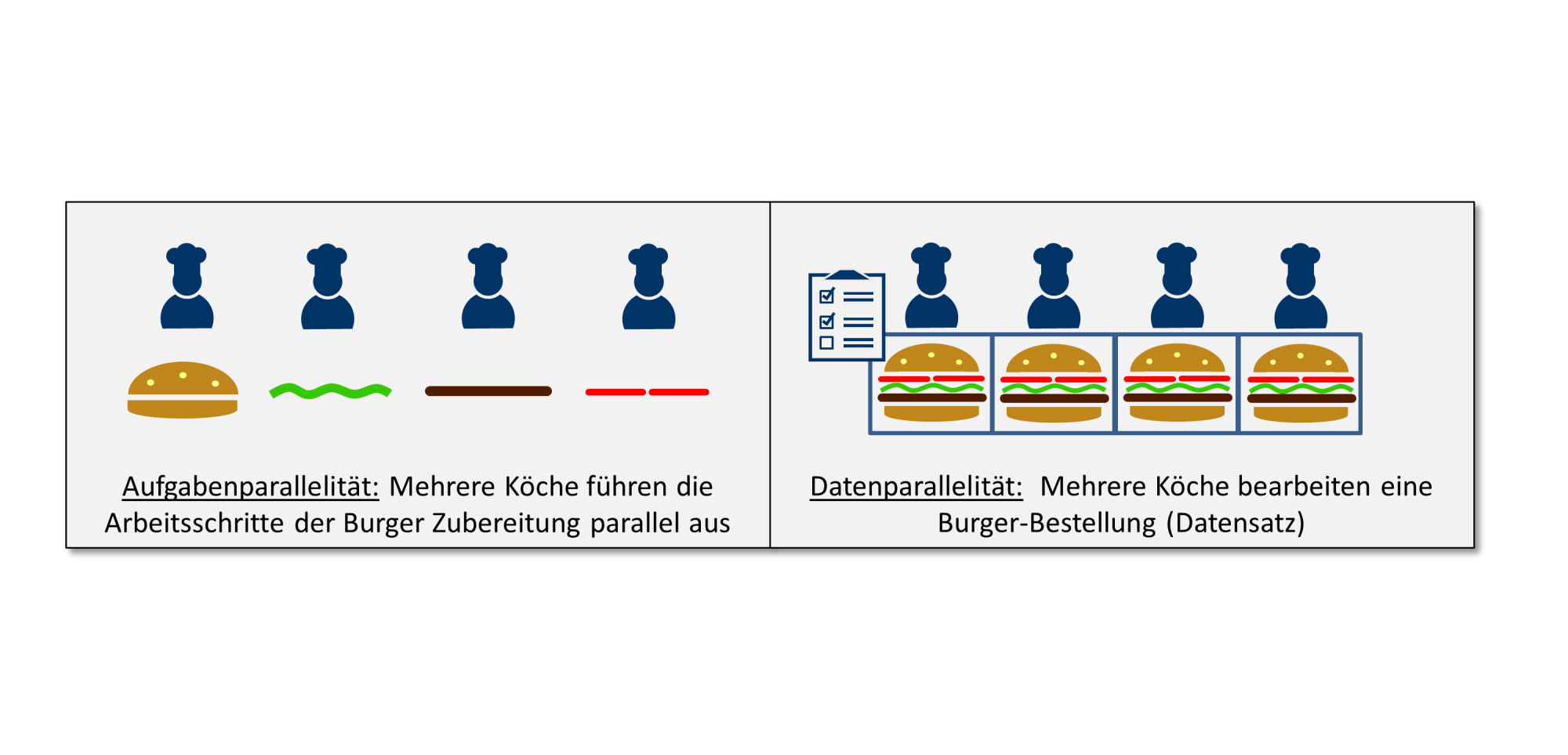
Bei der Parallelverarbeitung unterscheiden Entwickler häufig zwischen Aufgabenparallelität (task parallelism) und Datenparallelität (data parallelism). Bei der Task-Parallelität wird eine Reihe unterschiedlicher Aufgaben parallel und unabhängig voneinander auf den gleichen oder unterschiedlichen Daten bearbeitet. Im Prinzip ein ähnlicher Vorgang, wie wenn mehrere Köche einen Burger zubereiten und dabei die einzelnen Arbeitsschritte wie die Zubereitung von Salat, Tomaten, Brötchen und Bulette parallel ausführen (s. Abb. 1).
(Bild: Volkswagen AG)
Bei der Datenparallelität wird dieselbe Aufgabe auf unterschiedlichen Bereichen eines Datensatzes parallel ausgeführt. So, als würden mehrere Köche eine Burger-Bestellung (Datensatz) bearbeiten und gleichzeitig die Burger zubereiten.
Parallele Ausführung beschleunigt Anwendungen – aber in Grenzen
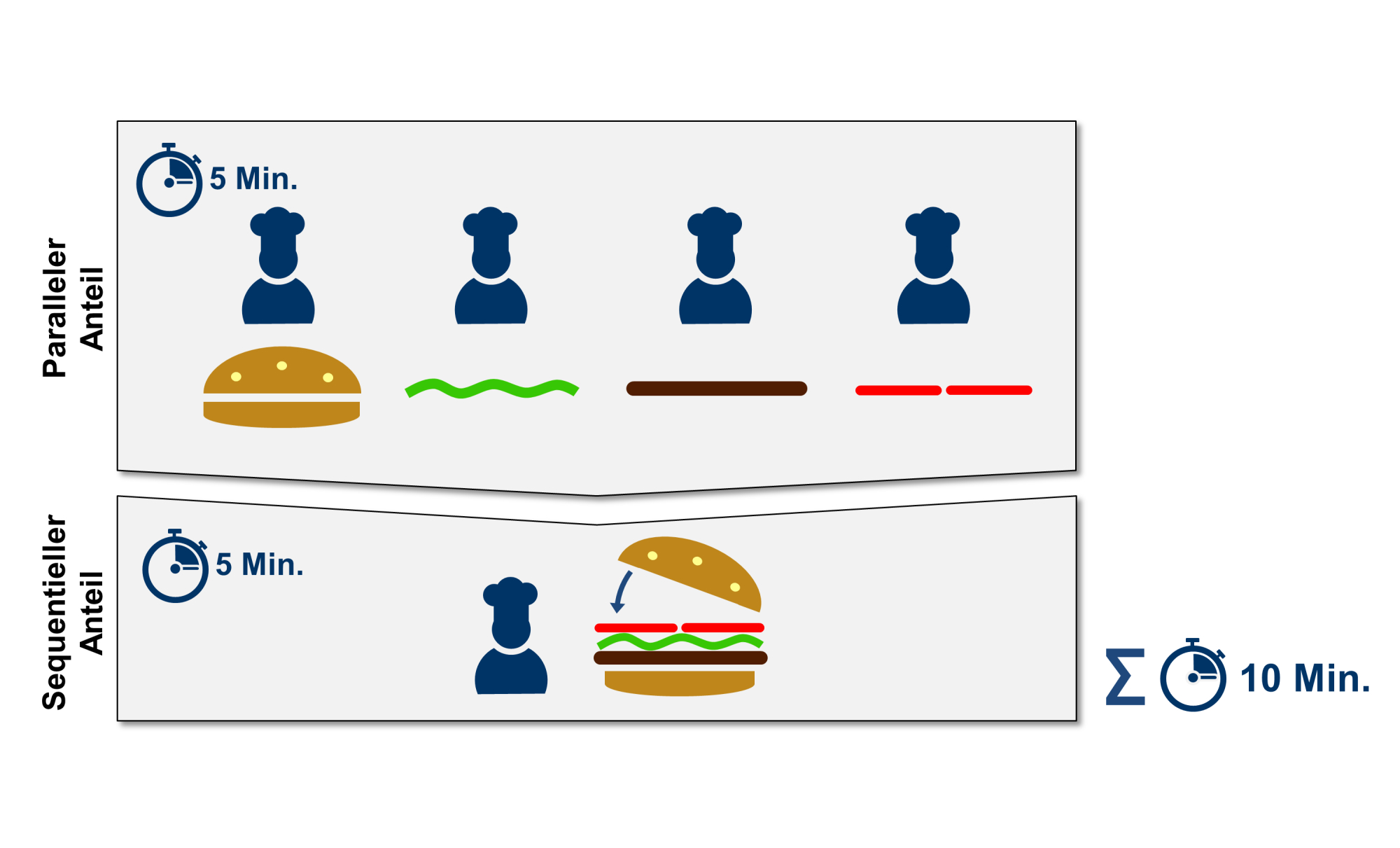
Wie sehr sich eine Anwendung durch parallele Ausführung beschleunigen lässt, ist nach dem Amdahlschen Gesetz abhängig von dem sequenziellen (also dem nicht parallelisierbaren) Anteil einer Applikation. So bereiten mehrere Köche die einzelnen Zutaten des Burgers vor, aber nur ein Koch fügt sie sequenziell zusammen (s. Abb. 2).
(Bild: Volkswagen AG)
Die gesamte Zubereitungszeit hängt also von den fünf Minuten ab, die ein einzelner Koch benötigt, um die Zutaten zusammenzufügen. Auch wenn sehr viele Köche mitkochen und die Zubereitung der Zutaten (paralleler Anteil) beschleunigen, fällt die Gesamtzeit niemals unter fünf Minuten.
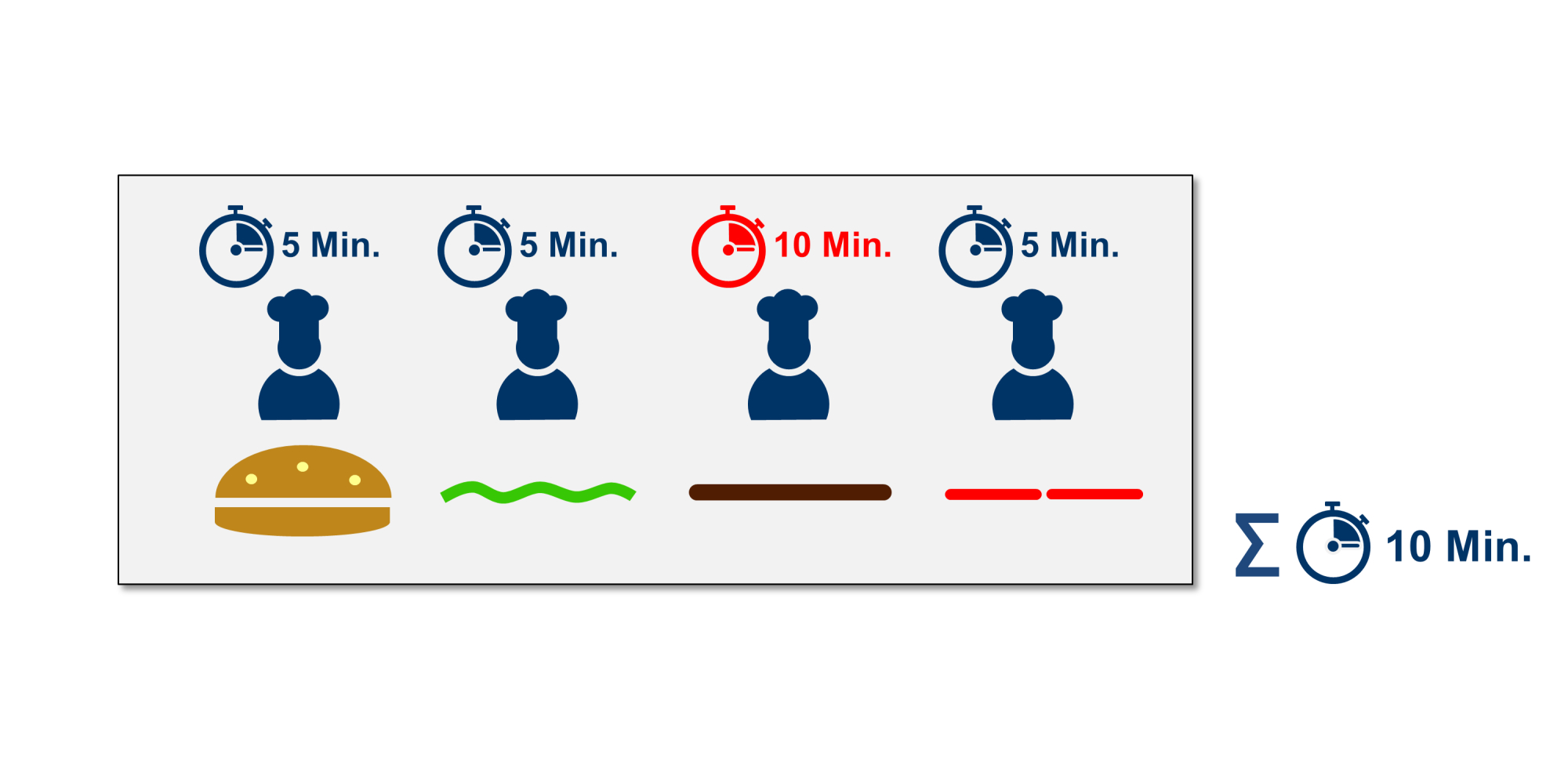
Eine hohe parallele Effizienz lässt sich erzielen, wenn die Problemstellung gut parallelisierbar ist und einen möglichst geringen sequenziellen Anteil besitzt. Gute Parallelisierbarkeit heißt auch, dass sich die einzelnen Teilaufgaben in der gleichen Ausführungszeit erledigen lassen. Andernfalls kommt es zu dem in Abbildung 3 dargestellten Problem.
(Bild: Volkswagen AG)
Der Koch, der die Bulette zubereitet, benötigt deutlich mehr Zeit als die anderen drei Köche. Dies erhöht nicht nur die Bearbeitungszeit des parallelen Anteils, sondern führt auch dazu, dass die anderen drei Köche fünf Minuten warten müssen und nichts zu tun haben, bis der letzte Koch fertig ist.
Um ein Multi-Core-System effizient auszulasten, ist somit eine Problemstellung mit einer hohen Parallelisierung notwendig. Insbesondere Problemstellungen, die denselben Algorithmus auf unterschiedliche Bereiche eines Datensatzes anwenden (Datenparallelität), eignen sich hierfür gut. Anwendungsgebiete wie die Simulation physikalischer Prozesse oder das Training neuronaler Netze sind besonders prädestiniert. Hingegen lassen sich Anwendungen wie Office-Applikationen oder Webserver oftmals kaum parallelisieren.
