

Machine Learning im Kubernetes-Cluster
Eine Cluster-Management-Software wie Kubernetes bietet Methoden und Tools, die Data Scientists beim Entwickeln von Machine-Learning-Anwendungen sinnvoll unterstützen.

- Sebastian Jäger
Das Management eines Clusters gestaltet sich komplex. Sollen darauf Machine-Learning-Anwendungen entwickelt werden, kommen weitere Herausforderungen hinzu. Das Training von Modellen ist eine sehr rechenintensive Aufgabe, vor allem wegen der großen Zahl von Trainingsdaten, die benötigt wird. Zur Beschleunigung lässt sich das Training meist horizontal skalieren. Seit dem Siegeszug von den beim Deep Learning eingesetzten künstlichen neuronalen Netzen reicht dies jedoch häufig nicht mehr aus. Das Verwenden von GPUs oder TPUs ist für das Trainieren größerer Netze unabdingbar geworden – beim Anwenden der Modelle kommt man jedoch auch ohne die spezialisierten Prozessoren aus. Der Einsatz heterogener Maschinen erhöht allerdings die Komplexität des Clusters weiter.
Im Bereich des Machine Learning wird eine Vielzahl unterschiedlicher Programmiersprachen, Bibliotheken und Frameworks verwendet. Darunter leiden mitunter die Nachvollziehbarkeit und die Reproduzierbarkeit der Experimente, da unter Umständen nicht nachvollziehbar ist, mit welchen spezifischen Versionen die Ergebnisse erzielt wurden.
In Verbindung mit weiteren Tools kann die Cluster-Management-Software Kubernetes Data Scientists helfen, Machine-Learning-Projekte effizient und erfolgreich umzusetzen.
Was ist Kubernetes?
Kubernetes ist ein Clustermanager, der zum Orchestrieren von Containern dient. Das Mitte 2014 von Google gestartete Projekt lag bereits ein gutes Jahr später in Version 1.0 vor und rückte unter das Dach der neu gegründeten Cloud Native Computing Foundation.
Kubernetes gruppiert ein oder mehrere Container in "Pods", die die kleinste deploybare Einheit darstellen. Diese werden von Kubernetes auf einem "Node" ausgeführt, der alle Anforderungen des Pods erfüllt. Dazu gehören vor allem die verfügbaren Ressourcen. Jeder Pod erhält eine IP-Adresse, über die ihn andere erreichen können. Diese IP-Adressen sind jedoch flüchtig und können sich bei einem Neustart des Pods ändern.

Um eine stabile Kommunikation zu erreichen, bietet Kubernetes sogenannte "Services" an. Ein cluster-interner DNS lässt sich verwenden, um ihren Namen auf eine Adresse aufzulösen. Ein Service dient lediglich als Load Balancer und reicht einkommende Nachrichten an die ihm zugeordneten Pods weiter – er kann also auch als Load Balancer fungieren. Mit Hilfe von "Labels" lassen sich Objekte (Node, Pod, Service etc.) mit Informationen versehen. Die sind einfache Key-Value-Paare. Bei Services werden Labels verwendet, um die zugeordneten Pods zu selektieren. Beim Ausführen von Pods können sie ein Kriterium für die Entscheidung sein, auf welchem Node der Pod ausgeführt wird.
Kubernetes überwacht den Ist-Zustand der Objekte ständig und vergleicht diesen mit dem Soll-Zustand der Objektdefinitionen. Bei Unterschieden ergreift Kubernetes automatisch Maßnahmen, um den Soll-Zustand zu erreichen. Stürzt zum Beispiel ein Pod oder sogar ein ganzer Node ab, erkennt Kubernetes das und startet die fehlenden Pods auf einem anderen Node neu. Kubernetes ist nicht nur fehlertolerant gegenüber dem Ausfall von Nodes, sondern ermöglicht es auch, die Anzahl der Knoten im laufenden Betrieb zu ändern.
ML-Trainingsumgebungen teilen und skalieren
Kubernetes verwendet Container-Technologien wie Docker, um Workloads auszuführen. Container und die damit einhergehende Isolation der Workloads vereinfachen es, nachvollziehbare und reproduzierbare Experimente zu entwickeln. Für jede Trainingsumgebung, also jede Kombination spezifischer Versionen der verwendeten Programmiersprache, Bibliotheken und Frameworks, lässt sich ein dedizierter und wiederverwendbarer Container bauen und wiederholt einsetzen. Dadurch erhalten auch mehrere Data Scientists gleichzeitig die Möglichkeit, auf demselben Cluster zu arbeiten. Die Isolation der Container untereinander stellt sicher, dass sich Experimente mit verschiedenen Trainingsumgebungen zeitgleich ausführen lassen, ohne dass sie sich gegenseitig stören.
Soll das Training von Modellen skalieren, hilft Kubernetes ebenfalls. Dann genügt es, das Training mit mehreren Workern in Form weiterer Pods zu starten. Kubernetes führt diese auf Nodes mit genügend Ressourcen aus und nimmt alle nötigen Anpassungen für die Kommunikation vor, ohne dass weitere manuelle Schritte wie das Verteilen von IP-Adressen für die Kommunikation nötig sind. Kubernetes vereinfacht auch das Skalieren des Clusters. Wenn neue Maschinen hinzukommen, ist lediglich Kubernetes zu installieren. Weitere Software ist nicht erforderlich, da die Ausführungsumgebung der Experimente bereits in den Containern zur Verfügung steht.
Einen Nachteil früherer Kubernetes-Versionen beim Entwickeln von Machine-Learning-Anwendungen auf einem Cluster behebt Kubernetes 1.6: Auch containerisierte Workloads können nun die Rechenkapazität von GPUs nutzen.
Bestehende Umgebungen und Experimente lassen sich jedoch nicht ohne Anpassungen auf einem Kubernetes-Cluster ausführen. Dadurch entsteht ein gewisser Migrationsaufwand beim Wechsel auf Kubernetes. Außerdem erfordert das Arbeiten auf solchen Systemen in der Regel eine Einarbeitungs- und Eingewöhnungszeit.
Durch den Einsatz von Kubernetes ergeben sich die folgenden Vor- und Nachteile gegenüber einem ohne Kubernetes verwalteten Cluster:
- vereinfacht den Umgang mit mehreren Trainingsumgebungen.
- vereinfacht das Teilen des Clusters zwischen mehreren Usern.
- Skalieren des Clusters und der Workloads einfacher, aber Migrationsaufwand sowie Einarbeitungs- und Eingewöhnungszeit nötig.
Kubernetes kann bei der Entwicklung von Machine-Learning-Anwendungen helfen. Jedoch ist es nicht immer ohne weiteres möglich, bestehende Softwareumgebungen sinnvoll zu containerisieren. Auch kann die Implementierung und Verwaltung von Kubernetes-Objekten umständlich sein. Da Kubernetes zurzeit der am weitesten verbreitete Clustermanager ist, bemüht sich eine große Community darum, das Arbeiten mit Kubernetes weiter zu vereinfachen und Kubernetes-native Anwendungen zu entwickeln.
Helm – der Paketmanager für Kubernetes
Helm ist ein Paketmanager für Kubernetes (helm.sh). Damit lassen sich verschiedene Kubernetes-Objekte, die logisch eine Applikation ergeben, zu einem sogenannten Chart zusammenfassen. Charts lassen sich versionieren und mit anderen Entwicklern als Code oder über sogenannte Chart Repositories teilen. Auch eine öffentliche Sammlung von Helm Charts steht Entwicklern zur Verfügung.
Die Template Engine erlaubt es, Kubernetes-Objekte durch Verwendung von Templates zu erzeugen. Dabei ist es nicht nur möglich, einfache Werte in Abhängigkeit einer Konfigurationsdatei oder eines Arguments zu ersetzen, die Engine unterstützt auch komplexere Kontrollstrukturen wie Schleifen und Bedingungen.
Eine kleine Helm-Kunde
Im Rahmen der Artikelserie "Die Werkzeugkiste" stellen Entwickler auf heise Developer nützliche Tools vor.
Die Werkzeugkiste #1 ist dem Paketmanager Helm gewidmet: Helm – Kubernetes-Deployments richtig gemacht.
Ein großer Vorteil von Helm ist die Möglichkeit, die entwickelten Charts einfach wiederverwenden zu können. Das Training von Modellen lässt sich dadurch nicht nur problemlos horizontal skalieren, indem man in Abhängigkeit eines Arguments entsprechend viele Worker Pods erzeugt, sondern es lässt sich durch Austausch des Containers ebenso komfortabel in unterschiedlichen Trainingsumgebungen ausführen. Darüber hinaus kann Helm alle Objekte einer neu gestarteten Anwendung (meist das Training von Modellen) überwachen und gemeinsam wieder beenden.
Helm erleichtert die Arbeit mit Kubernetes unabhängig von der Anwendungsdomäne dadurch, dass sich logisch zusammenhängende Objekte gemeinsam starten oder beenden lassen. Dank der Template Engine lassen sich die Objekte zudem generisch und wiederverwendbar gestalten.
Workflows und Pipelines
Beim Entwickeln von Machine-Learning-Anwendungen greifen Data Scientists häufig auf Pipelines oder Workflows zurück, um Bearbeitungsschritte der Datenverarbeitung zu automatisieren. Ein Workflow ist dabei eine Reihe von Arbeitsschritten, die auf eine Datenmenge angewendet werden, um sie beispielsweise in eine bestimmte Form zu überführen. Auch andere Use Cases wie das Erstellen von Sicherheitskopien, das Erzeugen von Statistiken oder Ähnliches sind denkbar. Die dafür entwickelten Tools Argo und Pachyderm sind speziell für den Einsatz in Kubernetes ausgelegt.
Jeder Verarbeitungsschritt der damit erzeugten Workflows lässt sich sowohl von einem wie auch mehreren Containern abarbeiten. Dem Nutzer bleibt die Entscheidung überlassen, welche Container zum Einsatz kommen. Damit ergibt sich eine hohe Flexibilität, da jede Software, die sich containerisieren lässt, als Workflow-Schritt fungieren kann. Argo und Pachyderm unterscheiden sich hingegen in der Art, wie sich die Workflows und Pipelines implementieren und ausführen lassen.
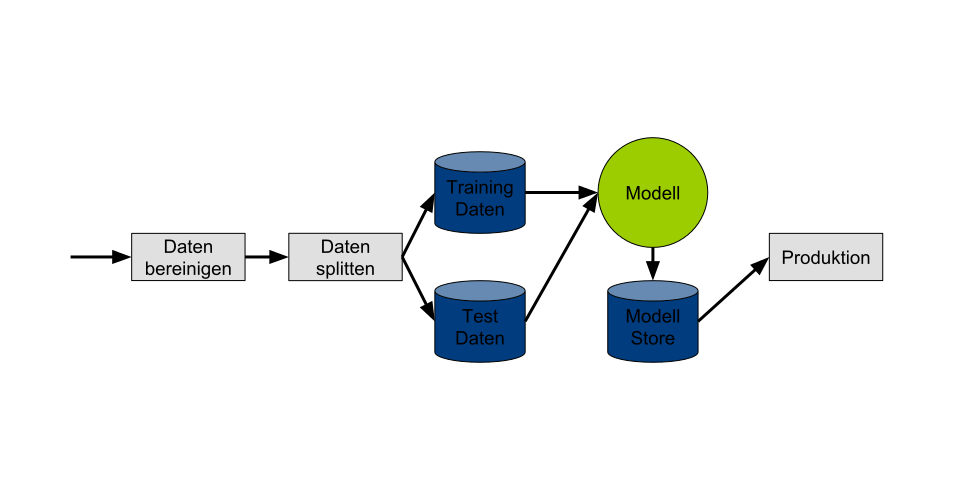
Argo – Workflow Engine für Kubernetes
Mit der Kubernetes CRD (Custom Resource Definition) lässt sich Argo nach der Installation in Kubernetes integrieren. CRDs ermöglichen es, die von Kubernetes zur Verfügung gestellte API um neue Objekte zu erweitern. Argo stellt so den Typen Workflow zur Verfügung. Über das CLI von Argo lassen sich Workflows starten, stoppen und deren Status abfragen. Ein Web-UI bietet die Möglichkeit, die Historie vergangener und aktueller Workflows mit Informationen wie dem Zustand, einem Zeitstempel und deren Parametrisierung zu betrachten. Nach dem Anstoßen eines Workflow startet Argo je nach hinterlegter Definition für jeden Schritt einen oder mehrere parallele Container und beendet sie nach Abschluss der Berechnungen auch wieder.
Workflow Engines bieten Data Scientists generell den Vorteil, wiederkehrende Arbeitsschritte zu automatisieren. Zum Beispiel lassen sich neue Daten aus einer Quelle auslesen, bereinigen, sortieren, aggregieren und schließlich in eine für das Trainieren der Modelle optimale Form ablegen. Argo im Speziellen ist dann sinnvoll, wenn eine einfache Möglichkeit gefragt ist, die das Implementieren von Workflows ermöglicht. Aufgrund seiner Architektur empfiehlt sich Argo besonders für sporadisch ausgeführte Workflows, da sich Worker Pods für den Workflow hoch- und wieder runterfahren lassen.
Pachyderm – reproduzierbare Data Science
Pachyderm versteht sich als moderne und flexible Hadoop-Alternative. Anstelle des verteilten Hadoop-Dateisystems (HDFS) tritt das eigene Pachyderm-Dateisystem (PFS), und Pipelines ersetzen die MapReduce-Jobs. Eine Pachyderm-Pipeline entspricht dabei genau einem Schritt des gesamten Workflows, auch wenn dieser bei Pachyderm nicht als Ganzes definiert wird, sondern sich implizit ergibt. Das Dateisystem von Pachyderm versioniert die Zugriffe und nutzt Git-ähnliche Commits beim Schreiben von Daten. Dadurch lassen sich nicht nur Daten eines früheren Zeitpunkts verwenden, sondern auch iteratives Arbeiten von Pipelines ist möglich. Das bedeutet, Pipelines können ihre Operation auf die Änderungen der Daten beschränken.
Ähnlich wie die MapReduce-Jobs bei Hadoop sind auch Pachyderm-Pipelines stark an das PFS gekoppelt. Eine Pipeline registriert (subscribed) sich für ein Data Repository (Verzeichnis). Sobald ein Commit die Daten des Verzeichnisses ändert, startet die Pipeline. Um dies umzusetzen, nutzt Pachyderm langlebige Worker Pods, initialisiert sie beim Erzeugen der Pipeline und lässt sie so lange laufen, bis die Pipeline abgeschlossen ist.
Als Plattform ermöglicht es Pachyderm, Workflows zu implementieren, auch wenn diese sich implizit dadurch ergeben, dass Pipelines den Output in ein Data Repository schreiben, das andere als Input verwenden. Seine Stärken im Vergleich zu Argo liegen vor allem bei Workflows, die sehr häufig beziehungsweise kontinuierlich ausgeführt werden, da man sich in diesen Fällen das Erzeugen und Zerstören der Worker Pods sparen kann. Darüber hinaus lässt sich anhand der Versionierung des Dateisystems genau nachvollziehen, welcher Output durch welche Pipeline mit welchem Input entstanden ist.
Beim Entwickeln von Machine-Learning-Anwendungen mit den Kubernetes-nativen Workflow Engines wie Argo oder Pachyderm profitieren Entwickler von zahlreichen Vorteilen, müssen aber auch Einschränkungen hinnehmen.
Vorteile und Nachteile von Argo und Pachyderm:
- (+) Automatisierung regelmäßiger Use Cases (z. B. Data Preprocessing).
- (+) Horizontale Skalierung der Workflow-Schritte möglich.
- (+) Flexibilität durch die Verwendung beliebiger Container.
- (+) Fördern Nachvollziehbarkeit und Reproduzierbarkeit.
- (–) Migrationsaufwand bestehender Pipelines.
- (–)Technologieauswahl muss sich am konkreten Use Case orientieren.
Kubeflow – das Machine Learning Toolkit für Kubernetes
Kubeflow ist eine Plattform, mit der sich Machine-Learning-Anwendungen entwickeln und ausführen lassen. Wie Kubernetes stammt auch Kubeflow ursprünglich von Google. Es liegt derzeit in Version 0.3 vor. Kubeflow bietet zum einen eine Sammlung unterschiedlicher Tools und bringt diese in eine sinnvolle Verbindung miteinander. Zum anderen hilft es durch Erweiterungen bei der Installation und Bedienung. Dadurch unterstützt Kubeflow nicht nur die Entwicklung von Machine-Learning-Anwendungen, sondern auch das Ausrollen der Modelle in Produktion und weitere iterative Schritte der Entwicklung.
Zu den Hauptfunktionen von Kubeflow gehört die Möglichkeit, Jupyter Notebooks über JupyterHub zu verwalten. So können mehrere User zeitgleich an unterschiedlichen interaktiven Jupyter Notebooks arbeiten. Vor allem zur Datenanalyse und für das Prototyping sind Jupyter Notebooks sehr hilfreich. Vorkonfiguriert sind verschiedene Python Images mit und ohne GPU-Unterstützung und vorinstalliertem TensorFlow in unterschiedlichen Versionen. Zusätzlich enthalten alle Images die Kubernetes CLI, die es ermöglicht, Kubernetes-Objekte direkt aus dem Notebook heraus zu erzeugen. Auch beide oben beschriebenen Workflow Engines, Argo und Pachyderm, sind in der Version 0.3 bereits integriert und lassen sich installieren. Darüber hinaus finden sich weitere, hier nicht besprochene Tools, die beim Entwickeln von Machine-Learning-Anwendungen zum Einsatz kommen können – darunter die auf MPI basierende TensorFlow-Erweiterung Horovod oder Seldon core, das beim Ausrollen von Modellen hilft.
Kubeflow bringt nicht nur verschiedene Tools zusammen, sondern bietet auch andere implementierte Komponenten. Hierzu gehören sogenannte Operatoren. Diese basieren auf CRDs und helfen beim Starten eines verteilten Trainings mit einigen bekannten Deep-Learning-Frameworks wie TensorFlow, Caffe2, PyTorch oder MXNet. Dabei wird die Verteilung der Prozesse, die meist Framework-eigen sind, vom Benutzer abstrahiert, sodass dieser sich auf die Implementierung der Netze konzentrieren kann. Kubeflow verfolgt den Ansatz einer einheitlichen Schnittstelle für die Frameworks. Eine andere Komponente ist das zentrale Dashboard, das alle aktiven Kubeflow-Komponenten anzeigt und die Navigation zu diesen erleichtert.
Vorteile und Nachteile von Kubeflow
- (+) Sammlung von Tools, die nach der Installation sinnvoll zusammenarbeiten.
- (+) Zentraler Punkt als Anlaufstelle, um alle Komponenten zu verwenden.
- (+) Abstrahiert unterschiedliche Frameworks und bietet einheitliche Operatoren.
- (+) Data Scientists können sich auf die Implementierung der Modelle konzentrieren und dann automatisch per CI/CD-Pipelines in Produktion ausrollen.
- (–) Umfangreiche Plattform, die je nach verwendeter Komponenten entsprechend viel Ressourcen belegt.
Fazit
Ist es sinnvoll, Data Science auf Kubernetes zu betreiben? Clustersysteme sind bei der Entwicklung von Machine-Learning-Anwendungen längst üblich geworden, daher ist es sinnvoll, ein entsprechendes Verwaltungssystem einzusetzen. Kubernetes hilft nicht nur dabei, einige der Probleme in den Griff zu bekommen, die durch den Clusterbetrieb entstehen, sondern auch bei Herausforderungen, die spezifisch für Machine Learning sind. Schon der Einsatz von Kubernetes allein kann also dazu beitragen, Machine-Learning-Anwendungen effizienter zu entwickeln.
Mit ergänzenden Tools lässt sich Kubernetes um zusätzliche Funktionen erweitern. Darüber hinaus schaffen speziell für Kubernetes entwickelte Tools eine breitere Basis für die Entwicklung von Machine-Learning-Anwendungen. Mit Technologien wie Kubeflow entsteht so eine mächtige Plattform auf Basis von Kubernetes, die Entwickler nicht nur bei sämtlichen Schritten auf dem Weg zu einer neuen Machine-Learning-Anwendung unterstützt, sondern auch bei deren Betrieb und etwaigen künftigen Iterationen der Weiterentwicklung.
Sebastian Jäger
hat Informatik an der Hochschule Karlsruhe – Technik und Wirtschaft studiert. In seiner Bachelor Thesis beschäftigte er sich mit dem performanten Trainieren von Neuronalen Netzen auf Basis von Kubernetes. Derzeit studiert er im Masterstudiengang Data Science an der Beuth Hochschule für Technik Berlin. Seine Interessen liegen in den Bereichen des Maschinellen Lernens und Big-Data, in denen er sehr gerne mit neuen Technologien experimentiert.
(map)
