

Weg mit den Schleifen!
Seite 2: Suche nach Ersatz
Auf das Erkennen der Probleme folgt die Frage, wie die Alternativen aussehen und ob sie Abhilfe schaffen.
Alternative #1: Rekursion
Manche Aufgaben sind für iterative Lösungen einfach schlecht geeignet. Ein typisches Beispiel ist der Quicksort-Algorithmus. Folgendes Listing (in Pseudocode) von Wikibooks zeigt eine Umsetzung mit mehreren verschachtelten Schleifen:
function QuickSort(Array, Left, Right)
var
L2, R2, PivotValue
begin
Stack.Push(Left, Right); // pushes Left, and then Right, on to a stack
while not Stack.Empty do
begin
Stack.Pop(Left, Right); // pops 2 values, storing them in Right and then Left
repeat
PivotValue := Array[(Left + Right) div 2];
L2 := Left;
R2 := Right;
repeat
while Array[L2] < PivotValue do // scan left partition
L2 := L2 + 1;
while Array[R2] > PivotValue do // scan right partition
R2 := R2 - 1;
if L2 <= R2 then
begin
if L2 != R2 then
Swap(Array[L2], Array[R2]); // swaps the data at L2 and R2
L2 := L2 + 1;
R2 := R2 - 1;
end;
until L2 >= R2;
if R2 - Left > Right - L2 then // is left side piece larger?
begin
if Left < R2 then
Stack.Push(Left, R2);
Left := L2;
end;
else
begin
if L2 < Right then // if left side isn't, right side is larger
Stack.Push(L2, Right);
Right := R2;
end;
until Left >= Right;
end;
end;
Eine exakte Erklärung des Codes wäre äußerst umständlich. Dagegen ist die rekursive Variante anhand eines Beispiels recht schnell erklärt: Quicksort soll die Zahlenreihe [3, 2, 6, 5, 4, 1] sortieren. Je nach Programmiersprache kann die Reihe als Liste oder Array gespeichert sein. Abbildung 2 zeigt das Prinzip, wie das Program vorgeht.
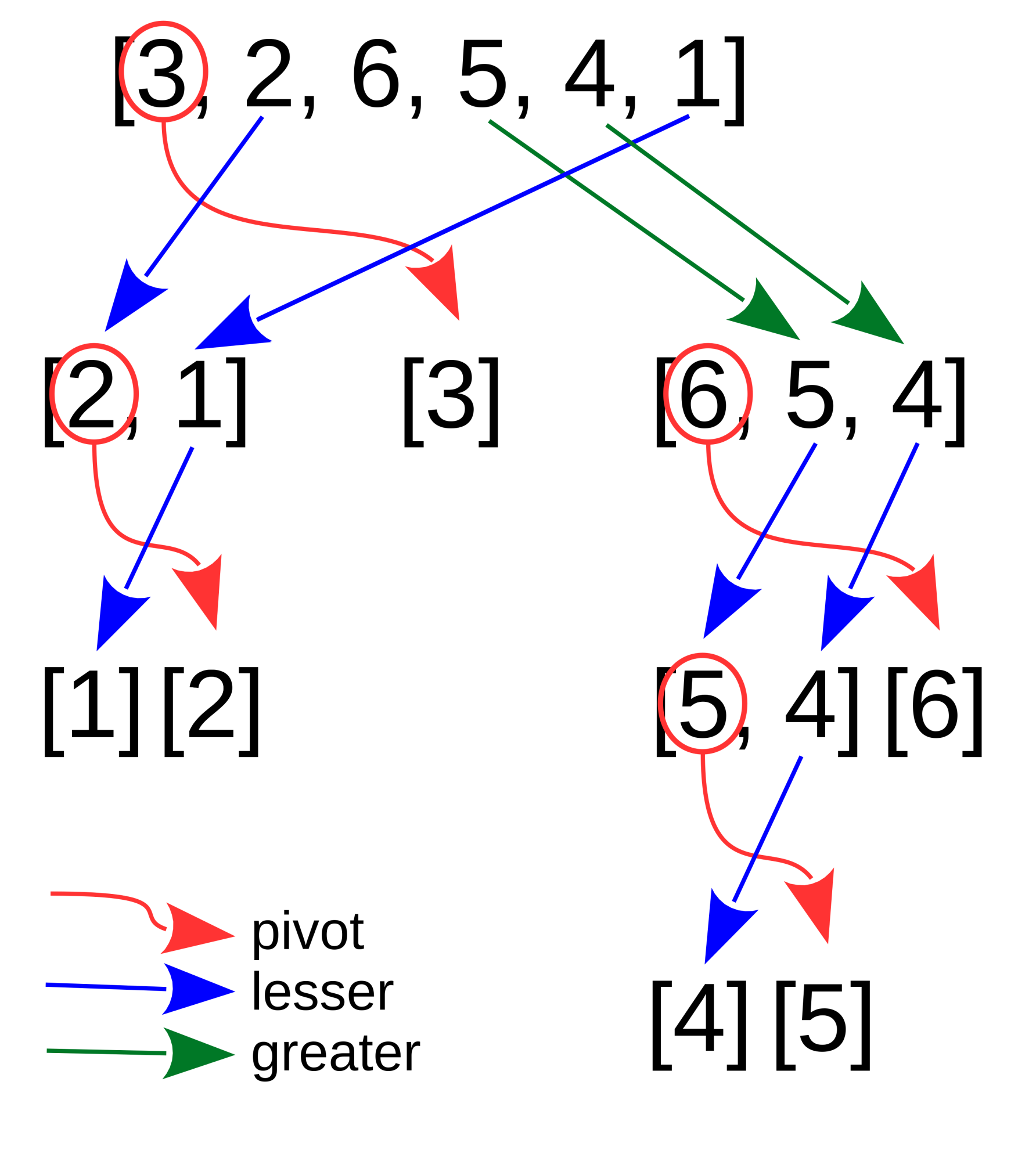
Der Algorithmus wählt das erste Element als sogenannten Pivot (im Beispiel die 3). Das ist eine Art frei gewählter Mittelpunkt. Dann werden alle Zahlen, die kleiner als 3 sind, links von der 3 eingeordnet und alle Zahlen, die größer sind, rechts davon. Damit ist die Reihenfolge der drei Gruppen korrekt:
- links [2, 1]
- dann die 3 als Pivot und
- rechts [5, 4, 6].
Der Rekursionsschritt besteht darin das gleiche Konzept auf die Untergruppen anzuwenden. Bei der linken Gruppe [2, 1] wird wieder das erste Element und damit die 2 zum Pivot. Der Algorithmus sortiert die 1 nach links, weil sie kleiner als die 2 ist. Die rechte Gruppe [6, 5, 4] definiert die 6 als Pivot. Die Zahlen 5 und 4 landen links davon. So geht es weiter, bis nur noch leere Untergruppen übrig sind, die keiner weiteren Sortierung bedürfen.
Dieses Konzept ist in rekursivem Haskell-Code praktisch auf einen Blick zu erkennen, wie folgendes Besipiel vom Haskell-Wiki zeigt:
qsort [] = []
qsort (p:xs) = (qsort lesser) ++ [p] ++ (qsort greater)
where
lesser = filter (< p) xs
greater = filter (>= p) xs
Zum vollständigen Verständnis ist zugegebenermaßen eine gewisse Vertrautheit mit Haskell Voraussetzung, aber auch für nicht Haskell-Entwickler erschließt sich die Funktionsweise des Codes recht schnell.
Die erste Zeile stellt die Abbruchbedingung der Rekursion da. Eine leere Liste ist bereits sortiert. Erhält die Funktion qsort die leere Liste als Eingabe, gibt sie auch wieder eine leere Liste zurück. Im anderen Fall splittet die Funktion die Eingabe auf. p:xs bedeutet: splitte die Liste in das erste Element p (für Pivot) und xs den Rest der Liste.
Die Rückgabe der Funktion lautet (qsort lesser) ++ [p] ++ (qsort greater). Also alle Werte kleiner als p (lesser) verkettet mit p und anschließend allen Werten größer als p (greater). where erklärt, was unter greater und lesser genau zu verstehen ist und greift dabei auf filter zurück.
Damit entspricht der Haskell-Code genau dem Konzept des Algorithmus – ohne überflüssige Mechanik. Das folgende Listing zeigt die gleiche Implementierung in JavaScript:
const qsort = list => {
if (list.length === 0) return [];
const [p, ...xs] = list;
const lesser = xs.filter(x => x < p);
const greater = xs.filter(x => x >= p);
return [...qsort(lesser), p, ...qsort(greater)];
}
Hier ist zum Vergleich noch der Hauptteil der sogenannten "in-place"-Variante in Java (Quelle: Stackoverflow):
public static void recursiveQsort(int[] arr,
Integer start,
Integer end) {
if (end - start < 2) return;
int p = start + ((end - start) / 2);
p = partition(arr, p, start, end);
recursvieQsort(arr, start, p);
recursvieQsort(arr, p+1, end);
}
Alle rekursiven Varianten sind unabhängig von der Programmiersprache kürzer und gleichzeitig leichter zu lesen als die anfangs gezeigte iterative Fassung.
Tatsächlich gibt es zahlreiche Problemstellungen, die sich rekursiv leichter lösen lassen als iterativ. Dazu zählen
- viele komplexe Listenoperationen wie Quicksort,
- mehrdimensionale Operationen wie das klassische sogenannte Flood Fill,
- viele graphenbasierte Algorithmen
- speziell baumbasierte Algorithmen
Folgendermaßen schneidet Rekursion bezüglich der vier Schleifen-Probleme ab:
Das +/-1 Probleme kann es leider abhängig von der Art der Rekursion nach wie vor geben.
Hinsichtlich der Endlosschleifen verschlechtert sich die Situation eher. Rekursions-Abbruchbedingungen sind oft schwer zu formulieren und erhöhen die Wahrscheinlichkeit einer Endlosrekursion. Der Stack von Programmiersprachen ist begrenzt. Dadurch läuft die Rekursion nicht wirklich endlos, sondern endet nach kurzer Zeit mit einen "Stack-Overflow"-Fehler. Das verlagert das Problem jedoch lediglich, statt es zu beheben.
Statusbehaftung: Rekursionen können im Gegensatz zu Schleifen statuslos sein – eine klare Verbesserung. Treten in der Rekursionsfunktion Nebenwirkungen auf (z. B. das Ändern von Instanzvariablen) hat man allerdings nichts gewonnen. Die gezeigte In-Place-Variante von QuickSort ist so eine statusbehaftete Rekursion.
Hidden Indent: Da die Rekursion, die Regeln selbst beschreibt, ohne eine Schleifenmechanik zu benötigen, tritt das Problem nicht auf.
Rekursion kann eine gute Alternative sein, falls sich die Aufgabe dafür eignet und die Implementierung auf Nebenwirkungen verzichtet.
Alternative #2: Fun mit Higher-Order Functions
Higher-Order Functions (Funktionen höherer Ordnung) nehmen andere Funktionen als Parameter entgegen, geben neue Funktionen zurück oder beides. Typische Vertreter, die als Schleifenersatz in Frage kommen, sind map, filter und reduce.
Abbildung 3 zeigt eine einfach Aufgabe: Eine Funktion soll eine Reihe von Zahlen jeweils quadrieren.

Die Umsetzung mit Schleifen sieht folgendermaßen aus:
let a = [1, 2, 3, 4];
let r = [];
for (let j = 0; j < a.length; ++j) {
r[j] = a[j] * a[j];
}
Die Lösung mit map ist deutlich einfacher:
let r = [1, 2, 3, 4].map(x => x * x)
map nimmt die Funktion x => x * x entgegen. Sie ist quasi die Berechnungsvorschrift, die für jedes einzelne Element gilt. Die übergebene Funktion wird meist als Callback oder Lambda bezeichnet. Dann führt map den Callback für jedes Element aus und sammelt die Ergebnisse wieder ein. Die Funktion "mapped" (ordnet zu) sozusagen das ursprüngliche Array auf ein Ergebnisarray. Zu jedem ursprünglichen Element gibt es genau ein Ergebniselement.
Die Vorteile der Variante sind leicht erkennbar. map benötigt keinen Index und keine Bedingung. Die Mechanik haben die Entwickler der Bibliothek oder des Compilers bereits übernommen. Der Code sieht in unterschiedlichen Sprachen folgendermaßen aus:
// map in Haskell
map (^2) [1, 2, 3, 4]
// map in Ruby
[1, 2, 3, 4].map {|x| x ** 2}
// map in Java
Arrays.asList(1,2,3,4).stream()
.map(x -> x * x)
.toArray(Integer[]::new)
// map in PHP
function sqr($x) { return $x ** 2; }
array_map("sqr", [1, 2, 3, 4]);
Die Java-Variante mag dabei auf den ersten Blick etwas umständlich erscheinen. Tatsächlich ist die Umwandlung in einen Stream (.stream) aber nur einmal am Anfang und die Rückwandlung (.toArray) nur einmal am Ende einer längeren Operationskette nötig. Dazwischen lassen sich beliebig viele Higher-Order-Funktionen auf den Stream anwenden.
Arrays zusammenschrumpfen mit Reduce
Mit reduce lässt sich eine Liste oder ein Array auf einen einzelnen Wert reduzieren. Um beispielsweise alle Elemente in einem Array zu summieren, ist reduce eine gute Funktion (Abb. 4).

Zunächst wieder die Schleifenvariante:
let a = [1, 2, 3];
let r = 0;
for (let j = 0; j < a.length; ++j) {
r += a[j];
}
Die Higher-Order-Variante fällt kürzer und lesbarer aus:
const add = (a,b) => a + b
let r = [1, 2, 3].reduce(add)
reduce nimmt add als Callback entgegen und nutzt die Funktion um alle Elemente aufzuaddieren – ohne Index, Bedingung und Elementzugriff. Damit existieren weniger potenzielle Fehlerquellen, und die Intention ist auf einen Blick erkennbar: "Reduziere das Array durch die Addition". Die Java-Variante verwendet praktischerweise sum und kombiniert damit sozusagen reduce und add:
int myArray[] = { 1, 2, 3 };
int sum = Arrays.stream(myArray).sum();
Neben map, reduce und filter existieren viele analog verwendbare Funktionen, darunter some, every, find, zip und groupBy. Zusammen bilden sie eine Art Vokabular. Anhand des Funktionsnamens ist auf einen Blick erkennbar, ob der Code reduziert, gruppiert oder filtert.
Die Situation bei den Programmiersprachen ist gut: In funktionalen Sprachen wie Haskell, Elm und Clojure gehören die Higher-Order-Funktionen zum Kernumfang. Mainstream-Sprachen bieten ebenfalls gute Unterstützung. Beispielsweise kennt JavaScript einige Funktionen seit ECMAScript5 und erlaubt das Nachrüsten über Bibliotheken wie Ramda oder LoDash. Java hat Higher-Order-Funktionen für Streams mit Version 8 in die Standardbibliothek eingeführt, und für C# gibt es die LINQ-Erweiterung, die einen großen Funktionsumfang bietet.
Folgendermaßen schneidet Rekursion bezüglich der vier Schleifen-Probleme ab:
+/-1 Probleme gibt es nicht mehr, da kein Index existiert, der solche Fehler überhaupt ermöglichen könnte.
Endlosschleifen sind nicht möglich. Die Funktionen verarbeiten jedes Element und beenden im Anschluss den Vorgang.
Statusbehaftung kann es theoretisch geben, wenn der Callback Nebenwirkungen aufweist. In der Praxis ist das aber selten und alles andere als üblich.
Hidden Intent: Da die Mechanik komplett in der Implementierung der Higher-Order-Funktion steckt, ist die Absicht fast immer deutlich erkennbar. Oft ist es hilfreich, den Callback vorher zu definieren und zu benennen. Passende Namen wie add oder even tragen erheblich zur Lesbarkeit bei.
Somit scheinen High-Order-Funktionen zur Listenverarbeitung nahezu alle Schleifenprobleme zu lösen. Allerdings sind sie leider nicht das Allheilmittel. Die Anwendung ist situationsspezifisch und hilft nur bei Listen, Arrays, Streams oder ähnlichen Strukturen. Eine Schleife, die nicht auf einer Liste operiert, lässt sich nicht durch eine Funktion wie map ersetzen.
Alternative #3: Listgenerator-Funktionen
Wer keine Liste zur Verfügung hat, muss sich eben eine bauen.
Ein klassisches Beispiel für eine Situation, in der keine Liste zur Verfügung steht, kommt aus dem Bereich der ASCII-Grafik. Solche Grafiken wie der berühmte ROFL-copter (Abb. 5) lassen sich programmatisch erzeugen. Eine einfache Funktion in ASCII-Grafik-Bibliotheken ist lineOf. Sie erhält einen Integer als Argument, der die Länge einer zu zeichnenden Linie angibt (Abb. 6).

Die Schleifen-Implementierung sieht folgendermaßen aus:
let r = [];
for (let j = 1; j <= 5; ++j) {
r[j] += '-';
}
let s = r.join('');
Die einzige Information aus dem Schleifenkopf, die etwas über die Intention aussagt, ist die Zahl 5. Die Funktion soll fünf Mal ein Minuszeichen produzieren. Praktischerweise existiert eine passende Higher-Order-Funktion, die in den meisten Sprachen oder Funktionsbibliotheken times. heißt. Sie nimmt einen Callback entgegen und eine Anzahl, wie oft der Callback ausgeführt werden soll.
let s = times(_ => '-', 5).join();
Der Callback _ => '-' verwirft den Parameter _ und gibt bei jedem Aufruf ein Minuszeichen - zurück. times[/] ruft den Callback 5 mal (5 times) auf und generiert das Array [i]['-', '-', '-', '-', '-']. join fügt das Array zum String "-----" zusammen.
Im Gegensatz zur Schleife ist die Angriffsfläche für Bugs gering. Die Intention fünf Mal etwas zu erzeugen ist sofort zu erkennen, statt sich in einem Wust aus Symbolik zu verstecken.
Verwandte Funktionen sind range, unfold, upTo, downTo und repeat. Die folgenden Listings zeigen weitere Anwendungen:
//Summe von 3..6 (JavaScript + Ramda-Bibliothek)
sum(range(3, 6))
# gib 5 mal 'Hello!' aus (Ruby)
5.times {puts 'Hello!'}
# eine Linie von 5 Minus-Zeichen (Ruby)
(1..5).map {'-'}.join
Ruby realisiert das Äquivalent der range-Funktion mit dem Operator ...
Folgendermaßen schneidet der Ansatz bezüglich der vier Schleifen-Probleme ab:
+1/-1-Fehler sind nicht auszuschließen. Das liegt in der Natur der Problemstellung. Bei nummerischen Argumenten für times oder range können leicht Fehler unterlaufen.
Endlosschleifen können nicht entstehen, denn der Laufbereich ist durch die Parameter klar abgesteckt.
Die Statusbehaftung verhält sich genau wie bei anderen Higher-Order-Funktionen. Solange die Callbacks frei von Nebenwirkungen sind, gibt es keinen Grund, einen Debugger auszupacken.
Hidden Intent: Die Absicht eines Listengenerators ist klar zu erkennen, wie obiges Beispiel verdeutlicht.
