

AMD Epyc im Exascale-Supercomputer Cray "Perlmutter"
Ab 2020 will das US-Forschungslabor NERSC in Berkeley einen heterogenen Superrechner mit Cray-Shasta-Technik in Betrieb nehmen.
(Bild: NERSC)
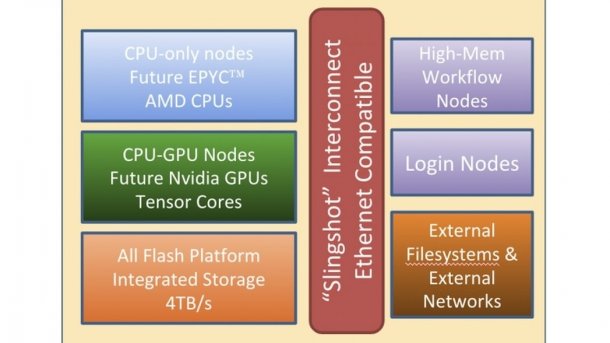
Mit rund 146 Millionen US-Dollar ist es der größte Auftrag in der Geschichte der Firma Cray: 2020 soll sie am National Energy Research Scientific Computing (NERSC) Center in Berkeley den Supercomputer NERSC-9 alias Perlmutter installieren. Dabei handelt es sich um einen heterogenen Rechner mit der neuen Cray-"Shasta"-Technik, zu der vor allem die ebenfalls neue "Slingshot"-Netzwerktechnik gehört.
Ein Teil der Rechenknoten wird mit dann aktuellen AMD-Serverprozessoren bestückt, also den 2019 erwarteten "Rome"-Typen (7 nm/Zen 2) oder deren Nachfolger Milan. Andere Perlmutter-Knoten arbeiten mit CPU-GPU-Gespannen, bei denen Nvidia Tesla eine Rolle spielt. Nick Wright vom NERSC erklärte gegenüber TheNextPlatform, es sei noch nicht genau klar, welche Komponenten zum Einsatz kämen.
Geplant ist die drei- bis vierfache Rechenleistung des aktuell schnellsten NERSC-Systems Cori (NERSC-8), also 100 Petaflops oder mehr. NERSC-9 wurde auf den Nachnamen des Nobelpreisträgers Saul Perlmutter getauft, der am Lawrence Berkeley National Laboratory (LBNL) arbeitet, zu dem das NERSC gehört.
Cray Shasta
Die neue Shasta-Plattform ist laut Cray aber schon für deutlich größere Systeme ausgelegt, soll sich also für kommende Exaflops- oder wenigstens Exascale-Supercomputer eignen. Bei Shasta bündelt Cray mehrere Besonderheiten. Wichtigste Zutat ist der Slingshot-Interconnect, den der heutige Cray-CTO Steve Scott im Blog erklärt. Scott hatte Cray 2011 vor dem Verkauf der Interconnect-Sparte an Intel verlassen und kehrte 2014 nach Stationen bei Nvidia und Google zurück.
Slinghsot soll bis zu 250.000 Rechenknoten mit nur drei "Hops" über Switches vernetzen können. Slingshot verwendet weiter die "Dragonfly"-Architektur. Slingshot soll zudem auch Ethernet-Protokolle direkt abwickeln.
Der "Rosetta"-Chip für Slingshot-Switches hat 64 Ports mit je 200 GBit/s, also eine aggregierte Datentransferrate von 12,8 TBit/s. Ein 200-GBit/s-Link kombiniert vier Lanes mit je 50 GBit/s, die ähnliche Signale verwenden wie HDR Infiniband.
PCI Express 4.0 (PCIe 4.0) dürfte für Slingshot wichtig werden, was AMD Epyc ab Rome und IBM Power9 können, Intel Xeon-SP aber wohl selbst mit Cascade Lake nicht. Möglicherweise lässt sich für Intel-Knoten aber der in den "F"-Xeons eingebaute Omni-Path-Adapter nutzen.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (Google Ireland Limited) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Shasta ist außerdem für sehr hohe Prozessorleistung ausgelegt, unter anderem mit der Möglichkeit für direkte Flüssigkeitskühlung, sowie für unterschiedliche Mikroarchitekturen. Prozessoren mit x86- oder ARM-Technik sollen ebenso laufen wie GPU- und FPGA-Beschleuniger, verschiedene Architekturen lassen sich auch mischen.
Rechenaufgaben
Für NERSC-9/Perlmutter läuft bereits ein NERSC Exascale Science Application Program (NESAP): Wissenschaftler können sich mit ihren Projekten um Rechenleistung beziehungsweise frühen Zugriff auf den Superrechner bewerben. Das NERSC hebt drei Bereiche hervor, nämlich NESAP for Simulations (N4S), NESAP for Data (N4D) und NESAP for Learning (N4L), gemeint sind Machine Learning und Deep Learning.
(Bild: NERSC)
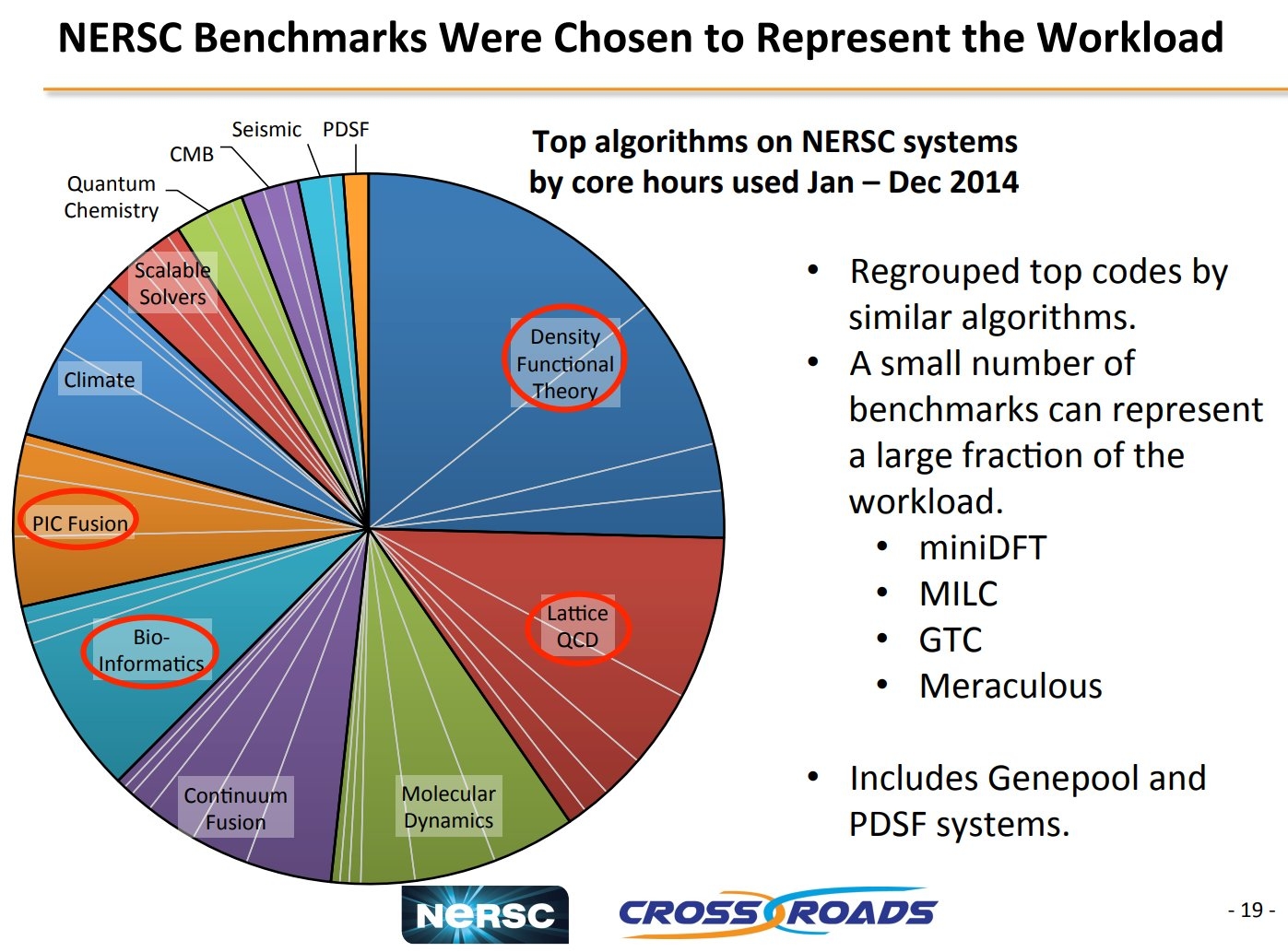
Laut einem PDF aus dem Jahr 2016 hatte der Apex-Verbund aus LBNL/NERSC, Sandia National Lab (SNL) und Los Alamos National Lab (LANL) ACES damals noch andere Pläne für NERSC-9. Intels Abkündigung des Xeon Phi und Verzögerungen der 10-nm-Xeons dürften zu Änderungen gezwungen haben. Eine Grafik aus diesem Dokument zeigt, welche Algorithmen 2014 besonders viel Rechenzeit auf NERSC-Systemen belegten. (ciw)
