

AI-generated tissue images: Study shows risk of deception
Real or AI-generated image? Experts take more time to decide, correct answers are (intuitively) given more quickly than incorrect ones.
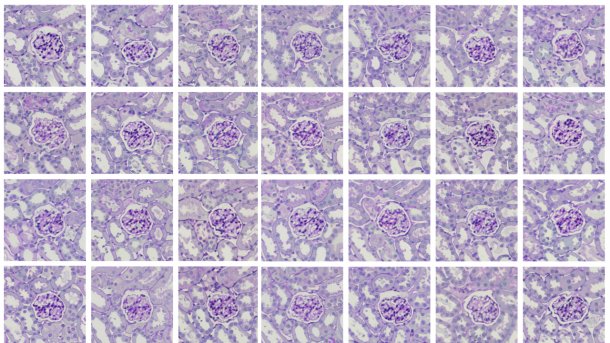
AI-generated tissue section images can also deceive experts.
(Image: Universitätsklinikum Jena)
When it comes to the question of whether an image is real or generated by AI, people (intuitively) make the correct classification much faster than the wrong one, but the assessment still presents them with challenges. This was the result of a study by the University of Jena entitled "Experts cannot reliably recognize AI-generated histological data". 800 participants were asked to classify real and artificial tissue section images.
Deep learning algorithms are increasingly being used in histopathology to help pathologists recognize and classify abnormalities such as cancer in tissue section samples. Medical diagnoses can be made faster and more precisely with the help of AI. Extensive data sets are required to train the AI models. In addition to real images, AI-generated synthetic images can also be used in pre-training to improve the recognition rate of models for certain types of cancer. However, research into whether AI should be trained on synthetic data (alone) is the subject of controversial debate among experts.
Fraud with manipulated or falsified data is on the rise, as it is not only with ChatGPT that fictitious AI measurement data can be quickly created.
"Experts" and laypeople in the test
A total of 800 students took part in the study. Of these, 526 participants were classified as "experts". The others were classified as laypersons. An "expert" was anyone who had ever seen histological images. In the first few years of medical studies, anatomy students learn about the fine structure (tissue and cells) of organs, and histology specimens are also examined under the microscope.
Videos by heise
To generate the artificial tissue section images for the study, DreamBooth was used to fine-tune the stable diffusion model. Two separate stable diffusion models were trained using real sectional images of stained tissue from mouse kidneys: One model with 3 images and the other model with 15 images.
Each model was then used to generate a batch of 100 artificial images. Four images were randomly selected from these two sets of 100 artificial images. These eight artificial images were mixed with the three real training images from one model and a selection of five of the 15 training images from the other model. The study participants were then presented with a total of 16 images one after the other and were asked to decide whether it was a real or an AI-generated image, or they gave no answer.
The non-expert group was able to classify the images correctly in 55 percent of cases. The expert group classified 70 percent correctly. AI images that came from the model, which had only been trained with three real images, were more often correctly identified as not real. No layperson managed to classify all images correctly. Only 10 participants from the expert group managed to do so.
Faster reactions with correct answers
Regardless of the picture shown, all participants usually made their decisions within the first 30 seconds. On average, however, the experts took more time for each individual decision than the non-experts.
It was remarkable that all participants – regardless of whether they were experts or laypersons – were significantly faster when they categorized a picture correctly than when they were wrong. "An observation that is consistent with current models of perception-based decision-making," says Dr. Jan Hartung, first author of the study.
With the further development of generative algorithms, it is becoming increasingly difficult for humans to recognize AI-generated content. Study leader Prof. Dr. Ralf Mrowka summarizes: "Our experiment shows that experience helps to recognize fake images, but that even then a significant proportion of artificial images are not reliably identified."
In order to prevent fraud in scientific publications, the authors of the study recommend, among other things, the introduction of technical standards to ensure the origin of the data. There should be an obligation to submit raw data. The use of automated tools to detect falsified images should also be considered.


(kbe)
