Mit dem neuen Java haben sich in der Plattform einige Dinge verändert, die die Leistung von Anwendungen deutlich verbessern. Die zwei prominenten Vertreter sind das Fork/Join-Framework und die "New I/O APIs".
Die im ersten Teil der Artikelserie zu Java 7 vorgestellten Spracherweiterungen von Project Coin fallen sicherlich ebenfalls in die Kategorie Performance. Allerdings haben sich mit dem neuen Java in der Plattform einige Dinge verändert, die die Leistung von Anwendungen deutlich verbessern. Die zwei prominenten Vertreter sind das Fork/Join-Framework und die "New I/O APIs".
Waren Threads in Java zu Beginn lediglich eine Möglichkeit für das asynchrone Ausführen von Aufgaben, kam mit zunehmend mehr Kernen die Notwendigkeit auf zur Verteilung der Aufgaben unter Verwendung sogenannter Thread Pools und Scheduling-Mechanismen. Mit der heute verfügbaren Anzahl an Rechenkernen sind alle bis dahin in Java verfügbaren Mechanismen überholt. Auf Anwendungsebene implementierte Konzepte und geteilte Work Queues können heutige CPUs nicht mehr geeignet auslasten. Es war also ein neues Mittel zu finden, die rechenintensive Parallelität in Java zu erreichen. Grundsätzlich gab es dafür mehrere Ansätze, mit Java SE 7 hat sich die Community letztlich für den Fork/Join-Ansatz entschieden.
Als Teil der Bemühungen um Parallelität in Java entstand bereits 2002 der JSR 166 (Concurrency Utilities). Mit dem in Java 5 integrierten Paket java.util.concurrent.* kamen erste Hilfsklassen für die Arbeit mit Parallelität in die Java-Plattform. Dabei handelte es sich um die Umsetzung vergleichsweise etablierter und bekannter Konzepte, die mit wenigen einfachen Interfaces den Entwickler unterstützen sollten. In Java 6 kamen dann sogenannte Deques (Double-ended Queues) und navigierbare Collections (Concurrent Sorted Maps und Sets) hinzu. Grundsätzliches Problem blieb bis dahin aber, dass es sich lediglich um Hilfsklassen handelte. Entwickler, die sie zur Umsetzung von Algorithmen einsetzen wollten, mussten die Verwaltung von Threads noch selber übernehmen. Fork/Join schließt die Lücke und stellt eine Erweiterung zu den ExecutorServices dar. Der mit Java 5 eingeführte java.util.concurrent.Executor und die zugehörigen ExecutorServices können Arbeitspakete ausführen, welche das Runnable Interface implementieren. Das sogenannte Executor Framework bietet dabei Beispielimplementierungen und Methoden zur Steuerung des Lebenszyklus von Threads.
Die Geschichte des Modells beginnt 2000 mit dem von Doug Lea vorgestellten Konzept eines Fork/Join-Frameworks (PDF) für Java. Es handelt sich um die Implementierung eines Algorithmus nach dem Prinzip "Teile und herrsche" (divide and conquer). Die Algorithmen gehen nach dem folgenden Schema vor:
Ergebnis loese(Problem problem) { if (problem is klein) löse das Problem direkt else { teile das Problem in unabhängige Probleme auf erstelle einen neuen Untertask um beide Teilprobleme zu lösen (fork) verbinde beide Untertasks (join) erstelle ein Gesamtergebnis aus den Teilergebnissen } }
Neue Subtasks startet der "fork". "join" stellt sicher, dass das Programm nicht weiter ausgeführt wird, bis der erstellte Subtask beendet wurde. Algorithmen dieser Art arbeiten fast alle rekursiv und zerlegen das eigentliche Problem immer weiter in seine Einzelteile, bis nur noch der kleinste Teil zu lösen ist.
Weiterlesen nach der Anzeige
Schematische Darstellung von "Teile und herrsche" (Abb. 1)
Die Lösung des Problems wird in einer Klasse implementiert, die RecursiveTask (mit Teilergebnis) oder RecursiveAction (ohne Teilergebnis) erweitert. Genauer: Der Algorithmus ist in der compute()-Methode zu implementieren.
Als konkretes Beispiel eignet sich die Aufgabenstellung, den Datensatz (Country,City,AccentCity,Region,Population,Latitude,Longitude) einer Stadt aus einer weltweiten Datenbank herauszusuchen. Mit 2.797.246 Einträgen bietet sich hier die freie MaxMind-Karte an. Das Prinzip ist einfach: Der Entwickler ließt die Textdatei ein und fahndet per Regular Expression nach einem String-Ausdruck. Treffer fügt er einem HashSet<String> matches hinzu:
List<String> lines = Files.readAllLines(Paths.get(file), Charset.forName("iso-8859-1")); Set<String> matches = new HashSet<>(); ... Pattern pattern = Pattern.compile(".*Hannover.*"); if (pattern.matcher(input).matches()) { matches.add(input[i]); }
Bei einem einfachen Durchlauf benötigt ein i7-Prozessor mit acht Kernen im Schnitt 3,5 Sekunden. Verändert der Entwickler die Implementierung und wendet einen Fork/Join-Algorithmus an, vergehen mit im Schnitt 1,5 Sekunden in diesem Fall weniger als die Hälfte. Zur Umsetzung muss er die dafür notwendige [i]ScanTask-Klasse erstellen und die .compute()-Methode aus dem java.util.concurrent.RecursiveTask überschreiben. Die Zerteilung des Problems richtet sich in diesem Beispiel nach der Anzahl der verbleibenden zu untersuchenden Zeilen. So wird es weiter zerlegt, wenn noch mehr als 20.000 vorhanden sind. Pakete kleiner dieses auch Threshold oder Schwellwert genannten Werts werden direkt sequenziell mit dem oben gezeigten Codestück verarbeitet.
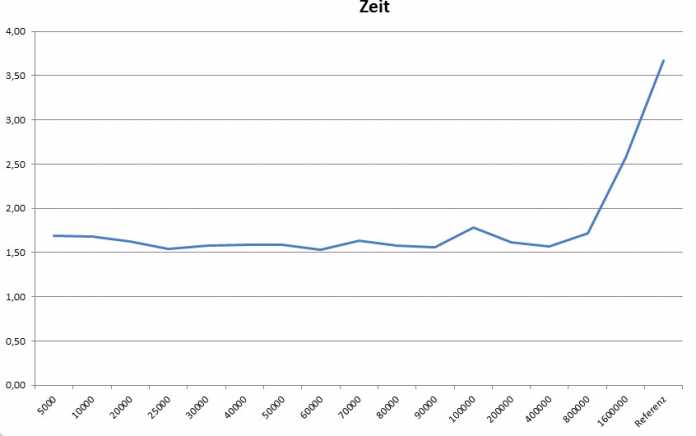
Dabei besteht die Kunst genau darin, den richtigen Schwellwert zu finden. Grundsätzlich bedeutet ein kleinerer Wert mehr Parallelität, damit verbunden aber auch höheren Aufwand für Koordination und Tasks. Deswegen führt kein Weg um das Profiling des Codes herum. Am Beispiel mehrerer Schwellwerte und gemittelter Laufzeiten für das Codebeispiel ergibt sich das in Abbildung Zwei gezeigte Bild.
Gemittelte Laufzeiten bei unterschiedlichem Schwellwert (Abb. 2)
Schön ist, dass sich der Code zur Bewältingung der Aufgabe unabhängig von der Ausführungsumgebung halten lässt. Grundsätzlich eignet sich das Fork/Join-Framework für rechenintensive Arbeiten mit minimaler I/O-Aktivität.