

Scheduling wie die Großen: Corona für Hadoop
Hadoops MapReduce-Scheduling konnte den Anforderungen der Facebook-Entwickler nicht mehr gerecht werden. Also implementierten sie einen eigenen Algorithmus, der nun der Öffentlichkeit zur Verfügung steht.
- Julia Schmidt
(Bild: Facebook-Engineering)
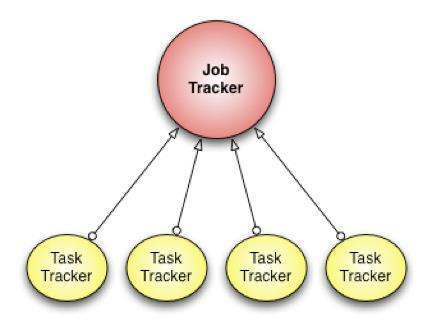
Um mit ihren mehreren Petabyte großen Datenbanken besser zurechtzukommen (das größte Cluster umfasst etwa 100 PByte), haben die Entwickler des sozialen Netzes Facebook einen eigenen Scheduling-Algorithmus für Hadoop entwickelt. Corona bearbeitet seit Mitte des Jahres alle Hive-Anfragen (Hadoops Data-Warehouse-System) und hat so die Stelle des MapReduce-Scheduling eingenommen, mit dem Hadoop normalerweise arbeitet.
(Bild: Facebook-Engineering)
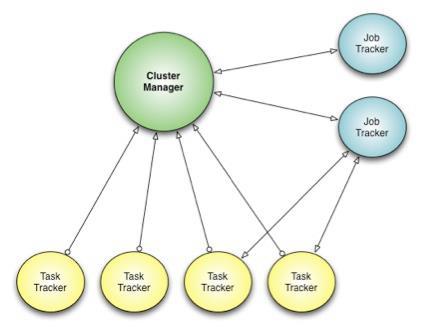
Im Gegensatz zum MapReduce-Ansatz wird mit Corona das Ressourcen-Management von der Job-Koordination getrennt. Ein Cluster-Manager hat die Aufgabe, Knoten im Cluster zu finden und deren freie Ressourcen zu ermitteln. Für jeden Job wird darüber hinaus ein Job-Tracker erstellt, der entweder im selben Prozess wie der Client oder als einzelner Prozess im Cluster laufen kann.
Ein weiterer Unterschied zum MapReduce-Scheduling-Framework ist das Verwenden eines Push-orientierten Scheduling, statt des Pull-Ansatzes: Nachdem der Job-Tracker Ressourcen-Anfragen erhalten hat, gibt er die entsprechenden Ressourcenbewilligungen zurück an der Tracker, der dann Tasks erstellt und diese zum Ausführen an den Task-Tracker weiterleitet. Da das Scheduling keinem bestimmten Rhythmus unterliegt, wird so die Latenz reduziert.
Innerhalb von drei Monaten wurden das gesamte Facebook-Produktionssystem von MapReduce-Scheduling auf Corona umgestellt, was dem Cluster, laut Entwicklern, unter anderem bessere Skalierbarkeit, weniger Latenz und besseres Ressourcenmanagement einbrachte. Die kommende MapReduce-Version, welche auch unter dem Namen YARN bekannt ist, kann als Alternative zu Corona gesehen werden. Allerdings konnte das Team aufgrund der Anforderungen nicht auf MapReduce 2.0 warten.
Der Corona-Quellcode ist im Hadoop-Github-Repository zu finden. (jul)
