

SQL-Entwicklung für Process Mining auf SAP HANA
SAPs In-Memory-Datenbank HANA ist seit ihrer Vorstellung 2010 immer wieder im Fokus der Berichterstattung. Durch die Verlagerung der Daten von der Festplatte in den Hauptspeicher verspricht sie einen enormen Performance-Sprung. Diesem Anspruch soll anhand einer Process-Mining-Anwendung nachgegangen werden.
- Sebastian Walter

SAPs In-Memory-Datenbank HANA ist seit ihrer Vorstellung 2010 immer wieder im Fokus der Berichterstattung. Durch die Verlagerung der Daten von der Festplatte in den Hauptspeicher verspricht sie einen enormen Performance-Sprung. Diesem Anspruch soll anhand einer Process-Mining-Anwendung nachgegangen werden.
Seit den Anfängen der ERP-Systeme lag der Fokus auf dem Hinzufügen einzelner Zeilen zu einem Datensatz – auch Online Transaction Processing (OLTP) genannt. Die Masse an vorgehaltenen Unternehmensdaten, zusammen mit der verfügbaren Rechenleistung, ermöglicht heute eine Aggregation und Weiterverarbeitung dieser Transaktionsinformationen – zumeist als Online Analytical Processing (OLAP) bezeichnet. HANA ist eine Datenbank, die gerade bei OLAP-Anwendungsfällen neue Maßstäbe setzten will.
Neben der erhöhten Geschwindigkeit bietet die HANA-Datenbank eine Reihe weiterer Features, etwa die Spaltenorientierung von Tabellen oder die automatisierte Tabellen-Replikation aus SAP-Quellsystemen, die System Landscape Transformation (SLT). In der Summe ergibt sich eine Datenbank, die dem Wunsch nach zunehmend komplexeren Auswertungen und Analysen großer Datenmassen nachkommen soll.
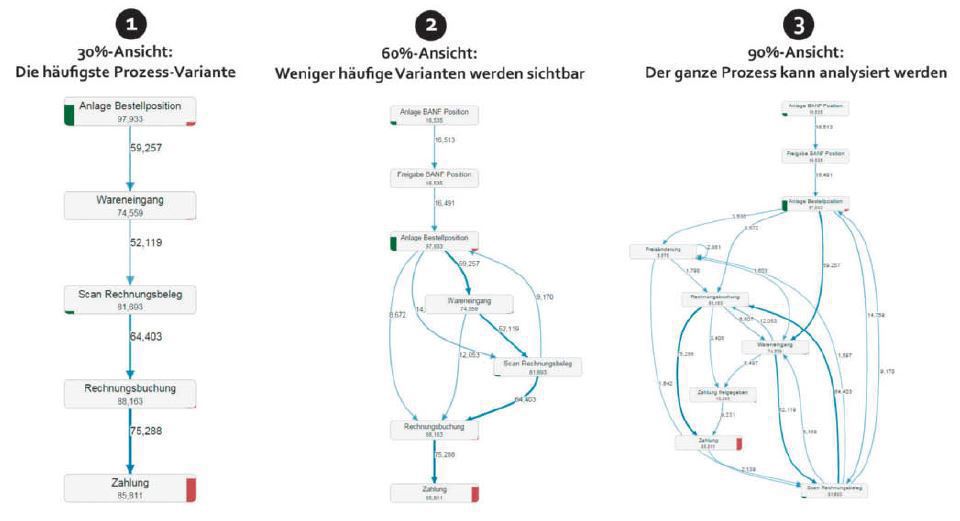
Ein besonders interessanter Anwendungsfall für die HANA-Datenbank ist Process Mining. Dessen Ziel ist es, Geschäftsprozesse in großen Datenmengen zu rekonstruieren und zu visualisieren. Jede Transaktion in einem IT-System hinterlässt Spuren: Logfiles, Tabelleneinträge, Belege et cetera. Die Idee von Process Mining ist es, diesen "digitalen Fußspuren" nachzugehen und sie zu sammeln. Aus der Gesamtheit der Informationsschnipsel wird dann der tatsächliche Ablauf der Geschäftsprozesse im Unternehmen rekonstruiert. Das Ergebnis wird in einem aus der klassischen Prozessanalyse bekannten Prozessgraphen dargestellt. Der Vorteil daran ist, dass dieser eben nicht auf subjektiven und unvollständigen Aussagen beruht, sondern rein datenbasiert erzeugt wird. Die so gewonnene Transparenz über die Geschäftsprozesse ist die Ausgangsbasis für vertiefende Auswertungen und bietet eine fundierte Basis für Prozessanpassungen.
Ein Anwendungsfall von Process Mining wäre etwa die Analyse des Beschaffungsprozesses eines global operierenden DAX-Konzerns. Hier interessieren beispielsweise folgende Fragestellungen: Wie oft werden Bestellfreigaben genutzt? Finden Wareneingänge bereits vor der Freigabe statt? Oder werden gar Bestellungen nachträglich (z. B. erst nach Eingang von Waren oder Rechnungen) angelegt? Wie lange sind dabei durchschnittliche Durchlaufzeiten? All diese Informationen sind prinzipiell in SAP- und anderen IT-Systemen vorhanden – sie sind für den Anwender aber erst durch Process Mining einfach zugänglich.
Transfer von MS SQL zu HANA SQL
Das dabei anfallende Datenvolumen ist enorm. Nutzer von Process Mining verfügen oftmals über eine komplexe IT-Infrastruktur, bestehend aus einer Vielzahl von SAP- und Drittsystemen. Es reicht auch nicht, einzelne Tabellen auszuwerten, – Informationen sind in Beziehung zueinander zu setzen und erfordern komplexe Joins. Einzelne Prozessspuren einem eindeutigen Geschäftsvorfall zuzuordnen und mit weiteren Informationen aus anderen SAP-Tabellen anzureichern, ist eine Mammutaufgabe für jede Datenbank. Bei HANA laufen jedoch Transformationen, die zuvor acht Stunden gebraucht haben, in wenigen Minuten durch. Hier hält die Datenbank durchaus, was SAP verspricht.
Am Beispiel Process Mining soll in diesem Artikel auf erste Erfahrungen mit der HANA-Datenbank eingegangen werden. Darunter fällt das Umstellen und Anpassen von SQL-Skripten von Microsofts SQL Server auf HANA sowie das Nutzen sogenannter Trigger auf SAPs Datenbank zur Erstellung eigener Change-Logs.
Process Mining benötigt eine gewisse Zieldatenstruktur. Abhängig von Quellsystem und Datenbank sind die Rohdaten aufzubereiten und entsprechend zu transformieren. Das geschieht mit teils recht umfangreichen SQL-Skripten. Der Wechsel des Dialekts von Microsofts SQL (MS-SQL) beziehungsweise PostgreSQL auf HANA SQL ist erfreulicherweise keine große Hürde: Allerdings gibt es einige Spezifika. So wird in HANA ein String etwa mit einem "||" verknüpft, statt eines "+" in MS-SQL.
SELECT 'Hello ' + 'world!' FROM DUMMY
GO
SELECT 'Hello ' || 'world!' FROM DUMMY ;
Ein weiteres Beispiel ist die Datumsfunktion DATEADD aus MS-SQL, die bei HANA in ADD_DAYS, ADD_MONTH, ADD_YEARS et cetera aufgeteilt wurde. Eine Referenzübersicht zwischen MS-SQL- und HANA-SQL-Befehlen findet sich unter dem Namen "Best Practices of SQL in the SAP HANA Database".
Die vielleicht größte Umstellung bei HANA ist die fehlende Unterscheidung von Groß- und Kleinbuchstaben bei nicht in Anführungszeichen gesetzten Namen von Tabellen, Spalten et cetera. Der folgende Code erzeugt unter MS-SQL die "Tabelle1" mit "Spalte1" und "Spalte2" – unter HANA wird mit dem gleichen Code aber "TABELLE1" mit "SPALTE1" und "SPALTE2" generiert.
CREATE TABLE Tabelle 1 (
Spalte1 NVARCHAR(10)
,Spalte2 NVARCHAR(10)
);
Selbiges gilt für die Auswahl. Das heißt, HANA ist indifferent zwischen dem Selektieren von "Tabelle1" und "TABELLE1" oder gar "TabELLE1". Um HANA zu einer Unterscheidung von Groß- und Kleinschreibung zu zwingen, sind Eigennamen zwangsläufig in Anführungszeichen zu setzen. Um also in HANA "Tabelle1" mit "Spalte1" und "Spalte2" zu erzeugen, wäre folgender Code notwendig:
CREATE TABLE "Tabelle 1" (
"Spalte1" NVARCHAR(10)
,"Spalte2" NVARCHAR(10)
);
Das zwingt entweder zu einer durchgehenden Nutzung von Anführungszeichen bei Eigennamen oder aber (weniger erstrebenswert) zur konsequenten Verwendung von Großbuchstaben. Bei der Migration von SQL-Skripten für HANA ist das eine häufige Fehlerquelle, da gegebenenfalls Anführungszeichen in MS-SQL nur dort benutzt wurden, wo sie unverzichtbar waren oder die Zielstruktur Kleinbuchstaben erwartet. Hier lohnt es sich – gerade für das parallele Bereitstellen von sowohl MS-SQL- als auch HANA-Skripten –, einen durchgehenden Standard zu definieren und einzuhalten.
