

Big Data: Fujitsu will Vorhersagen schneller berechnen
Ein neues Verfahren der Fujitsu Laboratories soll mithilfe des maschinellen Lernens aus großen Datenmengen schneller zuverlässige Prognosen erstellen können.
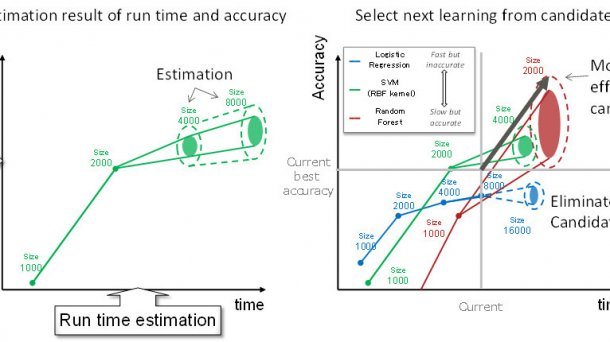
Anhand von Testläufen mit kleineren Datenmengen soll sich die für eine gute Vorhersagte geeignete Kombination aus Algorithmus und Konfigurationsparametern schneller bestimmen lassen.
(Bild: fujitsu.com)
- Christian Kirsch
Zwar lassen sich mit geeigneten Algorithmen aus großen Datenmengen zuverlässige Vorhersagen erstellen. Doch gibt es zahlreiche dieser Verfahren für verschiedene Zwecke, die sich hinsichtlich Genauigkeit und Laufzeit unterscheiden. Welcher Algorithmus die genaueste Prognose liefert, hängt sowohl von den vorliegenden Daten als auch von Konfigurationsparametern ab. Deshalb müsse man für ein effizientes Vorhersagemodell Kombinationen aus Algorithmen und Konfigurationen ausprobieren, schreibt Fujitsu in einer Mitteilung über eine neue Technik, die diesen Prozess wesentlich beschleunigen soll.
Das Fujitsu-Labor hat demnach zunächst zahlreiche Algorithmus-Konfigurations-Kombinationen verschiedene Daten- und Attributmengen verarbeiten lassen. Daraus entwickelte es ein Modell zur Schätzung der Laufzeit und Genauigkeit der Verfahren, das ständig durch Laufzeitmessungen verbessert wird.
Ausgehend von dieser Datenbasis könne man jetzt schneller eine optimale Kombination von Algorithmus und Konfigurationsdaten bestimmen. So wollen die Wissenschaftler die Zeit für das Erstellen eines Vorhersagemodells aus 50 Millionen Datensätzen ungenannter Größe von einer Woche auf zwei Stunden reduziert haben. Als Auswertungssoftware haben sie das freie Big-Data-Framework Spark aus dem Apache-Projekt benutzt.
Ausführlich wollen die Wissenschaftler ihr Verfahren auf der Tagung Information-Based Induction Sciences and Machine Learning (ISIMBL) vorstellen, die am 14. September 2015 in Japan beginnt.
(ck)
