

Google veröffentlicht einen Parser für natürliche Sprache
SyntaxNet zerlegt Sätze in ihre grammatikalischen Bestandteile und bestimmt die syntaktischen Beziehungen der Wörter untereinander. Das Framework ist Open Source und als TensorFlow Model implementiert.

Ein Parser für natürliche Sprache ist eine Software, die Sätze in ihre grammatikalischen Bestandteile zerlegt. Diese Zerlegung ist notwendig, damit Computer Befehle verstehen oder Texte übersetzen können. Die digitalen Helfer wie Microsofts Cortana, Apples Siri und Google Now verwenden Parser, um Sätze wie "Stell den Wecker auf 5 Uhr!" richtig umzusetzen.
SyntaxNet ist ein solcher Parser, den Google als TensorFlow Model veröffentlicht hat. Entwickler können eigene Modelle erstellen, und SnytaxNet bringt einen vortrainierten Parser für die englische Sprache mit, den seine Macher Parsey McParseface genannt haben.
Syntaktische Beziehungen
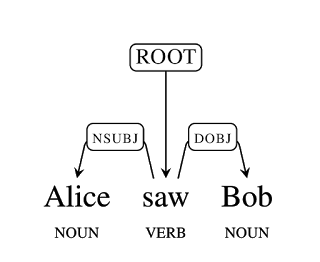
(Bild: Google)
Der Parser teilt den Wörtern eine syntaktische Funktion zu und untersucht die syntaktischen Beziehungen zwischen den Einzelteilen. Den englischen Beispielsatz aus dem Blog-Beitrag "Alice saw Bob" analysiert er folgendermaßen: "Alice" und "Bob" sind Substantive, und "saw" ist ein Verb. Letzteres ist gleichzeitig die Wurzel (ROOT), von der die restlichen Beziehungen ausgehen. Alice ist das zugehörige Subjekt (nsubj) und Bob das Objekt (dobj).
Längere Sätze werden leicht mehrdeutig. Beispielsweise ist im Satz "Alice sah Bob mit dem Fernglas" nicht erkennbar, wer von den beiden das Fernglas in der Hand hält. Rein syntaktisch ist auch der Satz "Peter schneidet das Brot mit Sonnenblumenkernen" mehrdeutig. Das menschliche Gehirn erkennt die richtige Bedeutung recht zuverlässig, aber für maschinelle Parser stellen sie eine Herausforderung dar.
SyntaxNet nutzt zur Entscheidung neuronale Netze und versucht die Abhängigkeiten richtig zuzuordnen. Damit "lernt" der Parser, dass es schwierig ist, Sonnenblumenkerne zum Schneiden einzusetzen, und sie somit wohl eher Bestandteil des Brots als ein Werkzeug sind. Die Analyse beschränkt sich jedoch auf den Satz selbst. Semantische Zusammenhänge berücksichtigt das Modell nicht. So lösen sich manche Mehrdeutigkeiten durch den Kontext auf: Wenn Alice im obigen Beispiel das Fernglas beim Verlassen des Hauses eingepackt hat, wird sie es vermutlich benutzen.
Trefferquote Mensch vs. Maschine
Laut dem Blog-Beitrag kommt Parsey McParseface auf eine Genauigkeit von gut 94 Prozent für Sätze aus dem Penn Treebank Project. Die menschliche Quote soll laut Linguisten bei 96 bis 97 Prozent liegen. Allerdings weist der Beitrag auch darauf hin, dass es sich bei den Testsätzen um wohlgeformte Texte handelt. Im Test mit Googles WebTreebank erreicht der Parser eine Genauigkeit von knapp 90 Prozent.
SyntaxNet steht auf GitHub quelloffen zum Herunterladen bereit. Dort befinden sich auch weitere Information zu dem Modell sowie Vergleichszahlen zur Erkennungsrate. (rme)
