

ARMv8: Skalierbare Vektorerweiterung mit 128 bis 2048 Bit
Mit der skalierbaren Vektorerweiterung SVE soll SIMD-Code für ARMv8 auf Prozessorkernen mit unterschiedlichen Vektorlängen laufen können - ohne Neukompilation.
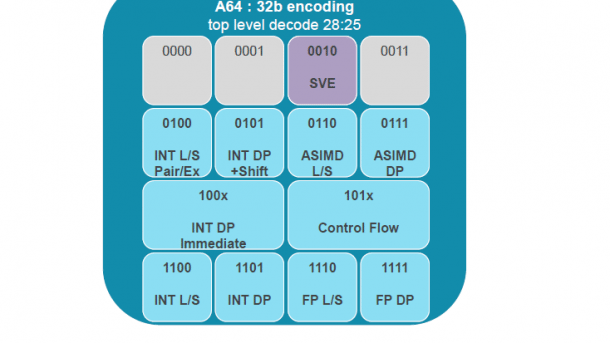
ARM und Fujitsu stellten auf der Hot-Chips-Konferenz die gemeinsam entwickelte skalierbare Vektorerweiterung SVE für HPC vor. Diese ist keine Erweiterung des vorhandenen AArch64 Advanced SIMD, sondern eine separate Architekturerweiterung mit neuem Instruktionssatz.
Die Scalable Vector Extension (SVE) verwendet die gleiche Befehlsstruktur für Vektorlängen von 128 Bit bis hin zu 2048 Bit. Man muss also nicht speziell für eine Vektorlänge kompilieren, sondern einmal kompiliert soll der Code mit allen Vektorlängen laufen. Das geht aber nur für einfache arithmetische und logische Operationen ohne direkten Zugriff auf einzelne Lanes. Somit ist SVE auch nur für HPC-Aufgaben vorgesehen, eignet sich nicht für DSP- und Media-Workloads.
Schneller als Neon
Durch die automatische Vektorisierung kann SVE mit Vektorlänge 128 bis zu dreimal so schnell sein wie Neon 128 (HACcmk aus der Coral-Benchmark-Suite). Bei Vektorlänge 512 steigt der Speedup gar auf bis zu Faktor 7,5.
SVE verwendet 32 skalierbare Register Z0 ... Z31 und bietet DP- und SP-Gleitkomma sowie 8, 16, 32 und 64 Bit Integer. Wie auch bei Intels AVX512 kann man einzelne Lanes maskieren (P0...P7). P8 bis P15 sind zum Manipulieren der Predikationen vorgesehen. Auch Scatter/Gather ist wie bei AVX512 vorgesehen.

(Bild: ARM)
Um in den engen Opcode-Raum von AArch64 zu passen, beschränkt sich das Encoding auf 28 Bits. Damit sind dann aber keine Dreiadressbefehle der Art: A= B op C mit Predikationen möglich, folglich sind die meisten Befehle, so wie bei Intel auch, "destruktiv", das heißt ein Quellregister wird überschrieben: A=A op B. Für nicht destruktive Operationen benötigt man dann ein Befehlspaar.
Die Open-Source-Community (LLVM, GCC, Binutils, Linux Kernel, HVM) soll in Kürze mit allem beliefert werden. Die finalen Spezifikationen sind Ende 2016/Anfang 2017 zu erwarten.
Mit ersten Chips mit SVE wirds indes noch dauern: Toshio Yoshida von Fujitsu sprach für den auf der ISC16 vorgestellten Post-K-Computer von 2020. (as)
