AMDs Next-Gen-Grafikchip Vega: Erste Details zur High-Speed-Architektur
Für die kommenden Vega-Grafikchips verbessert und erweitert AMD seine GCN-Architektur an entscheidenden Stellen. Zusätzlich soll der neue HBM2-Speicher genügend Transferrate und Fassungsvermögen für die Anwendungen von morgen liefern.
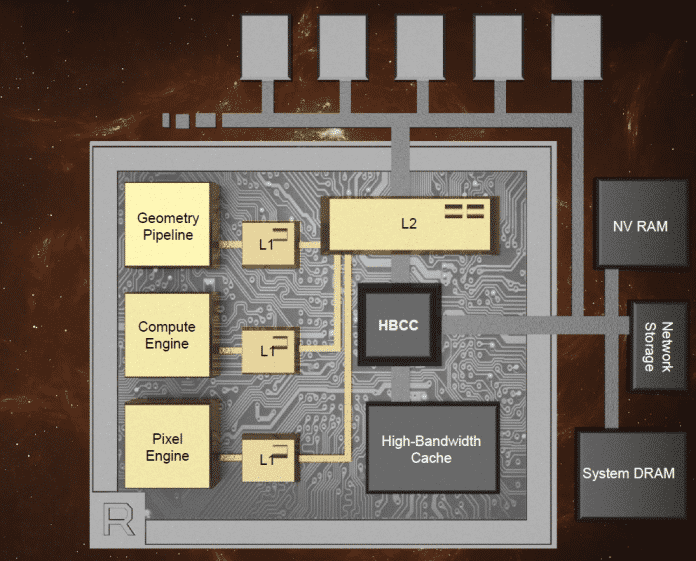
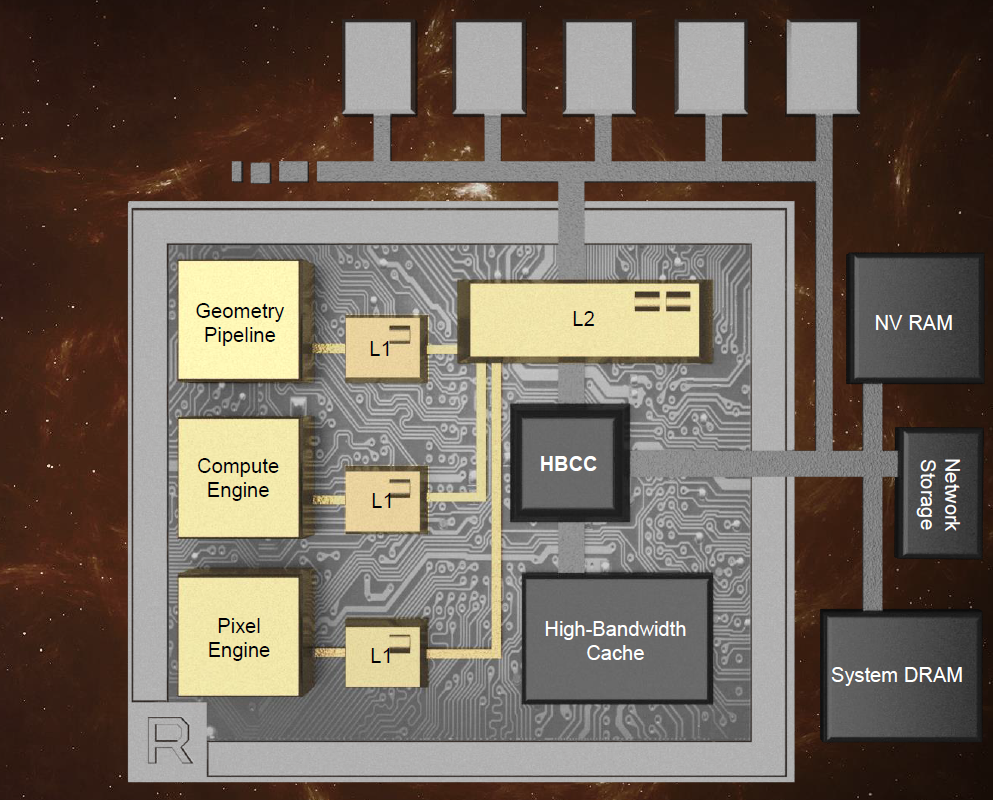
AMD hat Informationen über die kommende Grafikchip-Generation Vega bekanntgegeben. Vega-Grafikkarten sollen im ersten Halbjahr 2017 erscheinen und in der Lage sein, besonders große Datenmengen zu verarbeiten, die Bildqualität von Spielen und 3D-Anwendungen zu erhöhen und Supercomputing-Berechnungen schnell und effizient durchzuführen. Dafür hat AMD für Vega das Speicherinterface, die Geometrie-Pipeline, die Compute Engine und die Pixel Engine im Vergleich zu den bisherigen GCN-Grafikchips umgekrempelt.
Weiterlesen nach der Anzeige
High-Speed-Speicher
Für Vega hat AMD unter anderem die Geometrie-Pipeline, Compute Engine und Pixel Engine verbessert.
(Bild: c't/AMD)
AMD setzt bei Vega auf High Bandwidth Memory der zweiten Generation (HBM2). Im Unterschied zu HBM1, das etwa bei der Radeon-Fury-Serie zum Einsatz kam, bietet HBM2 theoretisch die doppelte Datentransferrate – also bis zu 1 TByte/s. Die tatsächliche Transferrate von Vega ist bis dato unbekannt und hängt auch davon ab, wie viele Speicher-Stacks AMD tatsächlich einsetzt – Gerüchten zufolge sollen es in der Consumer-Version zwei mit jeweils 8 GByte Fassungsvermögen sein, die mit 512 GByte/s arbeiten.
Einzelheiten über die Speicherhierarchie ihrer GPUs verraten weder AMD noch Nvidia. Mit welchen Bandbreiten, Latenzen und Assoziativitäten die Caches arbeiten und wie das mit der Virtualisierung und den Translation Lookaside Buffers (TLBs) aussieht – diese offenen Fragen versuchen Wissenschaftler mühevoll mit Microbenchmarks herauszutüfteln. Bislang liegen Ergebnisse für Nvidia Fermi, Kepler und Maxwell (mit zwei TLB-Leveln) vor.
HBM2-Speicher bietet hohe Transferraten, fasst viele Daten und spart Platz auf der Platine.
(Bild: c't/AMD)
AMD spricht bei Vega von einem revolutionären High Bandwidth Cache Controller (HBCC). Er soll im Zusammenspiel mit einem speziellen High Bandwidth Cache "adaptive feinkörnige Datenbewegungen" ermöglichen. Dazu gehört insbesondere das Paging auf externe Speicher, etwa Arbeitsspeicher, SSDs, NVRAM und Netzwerkspeicher. Anwendungen lässt sich dadurch ein besonders großer Videospeicher vorgaukeln. Der zur Verfügung stehende virtuelle Adressraum soll 512 TByte (48 Bit) betragen – so wie übrigens bei Nvidia Pascal auch.
Der HBCC dürfte mit nicht weiter spezifizierten TLBs zusammenarbeiten, die wie bei den CPUs üblich nicht schon bei der Allokation, sondern erst beim tatsächlichen Zugriff den physischen Speicher zuordnen. Häufig allozieren nämlich Spiele wesentlich mehr Videospeicher, als sie tatsächlich verwenden. Mit Vega lässt sich nun der Videospeicher effizienter nutzen.
Den Geometriedurchsatz soll bei Vega mehr als doppelt so hoch ausfallen im Vergleich zu bisherigen GCN-GPUs.
(Bild: c't/AMD)
Doppelt so hoher Polygon-Durchsatz
Durch die neue programmierbare Geometrie-Pipeline mit Primitive-Shader-Stages soll Vega einen doppelt so hohen Polygondurchsatz wie bisherige Radeon-GPUs erreichen. Das kommt insbesondere geometrielastigen Spielen zu Gute, wie derzeit etwa Deus Ex Mankind Divided. Durch verbesserte Verteiler (Intelligent Workgroup Distributor) will AMD die Geometrie-, Compute- und Pixel-Engines besser auslasten. Seine Pixel Engine hat AMD an einem wichtigen Punkt überarbeitet: So sind die Render Backends nun direkt mit dem L2-Cache verbunden (statt wie bisher über den Speicher-Controller), wodurch die GPU besonders bei Deferred-Shading-Anwendungen eine höhere Leistung entfalten soll.
Ferner soll Vega ein verbessertes Load Balancing aufweisen. Das ist ein vielschichtiger Begriff, der insbesondere im Zusammenspiel von mehreren GPUs mit OpenGL, Vulkan oder DirectX 12 (Multi-Adapter) interessant ist – auch mit heterogener Lastverteilung zwischen GPU und CPU. OpenCL 2.0 bietet mit den Pipes die Möglichkeit, mehrere Kernel auf einer GPU zu balancieren, ähnlich wie Hyper-Q oder Cuda-proxy bei Nvidia.
Durch den höheren Polygondurchsatz sollen vor allem geometrielastige Spiele wie Deus Ex Mankind Divided mit Vega-GPUs schneller laufen. Die Wireframe-Ansicht zeigt ... (Bild: c't/AMD)
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes YouTube-Video (Google Ireland Limited) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden.
Damit können personenbezogene Daten an Drittplattformen (Google Ireland Limited) übermittelt werden.
Mehr dazu in unserer
Datenschutzerklärung.
Die neuen Next-Gen Compute Units führen doppelt so viele fp16-Operationen (Half Precision) pro Takt aus wie fp32 (Single Precision) und eignen sich daher besonders gut für Deep-Learning-Anwendungen.
(Bild: c't/AMD)
Next-Gen Compute Units
Die Organisation von Shader-Rechenkernen in Arbeitsgruppen behält AMD bei, nennt sie aber nun Next-Gen Compute Units (NCU) statt mir Compute Units (CU). Die erste Grafikkarte mit Vega-10-GPU soll 64 NCUs mit jeweils 64 Shader-Rechenkernen enthalten. Diese sollen nun auch besonders hohe Taktfrequenzen mitmachen (ähnlich wie Nvidia sie bei Pascal-GPUs fährt) und das mit mehr Instruktionen pro Takt (IPC).
Vor allem soll jede einzelne Vega-NCU doppelt so viele fp16-Operationen pro Takt ausführen (wie Nvidias High-End-GPU GP100) wie fp32, nämlich 256 statt 128. So will AMD bei der lukrativen Deep-Learning-Industrie mitspielen, in der Nvidia schon seit einigen Jahren aktiv ist. Auch 8-Bit-Integer kommt hier in Mode, davon beherrscht Vega dann 512 pro Takt und NCU.
Die früheren AMD-GPU-Generationen seit Hawaii kannten fp16 zwar als platzsparendes Datenformat, konnten Berechnungen aber nur mit der gleichen Performance wie Single Precision ausführen. Wie es mit der Performance bei doppelter Genauigkeit aussieht – da muss man sich überraschen lassen, denn die soll in noch unbekannten Bereichen konfigurierbar sein.