

Böse Wikipedia-Postings sollen Filter befeuern
Diskussionseinträge mit persönlichen Angriffen dienen einem Projekt von Wikimedia Foundation und der Google-Mutter Alphabet als Ausgangsbasis für eine neue Anti-Hatespeech-Software.
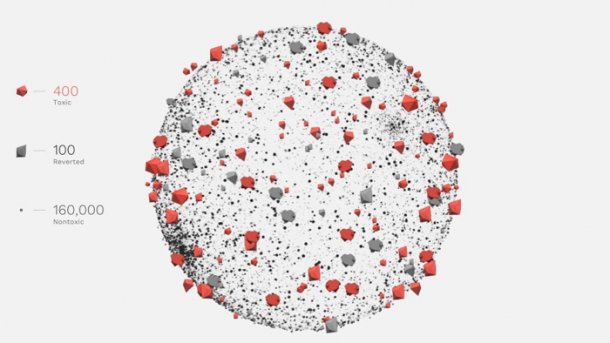
Hasspostings und Trollereien automatisch erkennen lernen soll ein gemeinsams Softwarevorhaben der Wikimedia Foundation und der Alphabet-Einheit Jigsaw, berichtet Technology Review in seiner Online-Ausgabe ("Mit Daten gegen Trolle"). Das Projekt basiert auf einem gigantischen Datensatz aus insgesamt mehr als 115.000 Nachrichten, die auf den Wikipedia-Diskussionsseiten gepostet wurden. Im Rahmen eines Crowdsourcings mussten menschliche Prüfer untersuchten, ob diese persönliche Angriffe enthielten, wie sie die Wikipedia-Gemeinschaftsstandards definieren.
Die Forscher konnten die so gewonnenen Daten dann verwenden, um Algorithmen aus dem Bereich des maschinellen Lernens zu füttern. Die sind mittlerweile fast so gut wie menschliche Crowdworker, behaupten Wikimedia Foundation und Jigsaw. Die Software wurde bereits auf die komplette Sammlung aus über 63 Millionen Postings losgelassen, die die Wikipedia-Redakteure in den letzten Jahren erstellt haben. Dabei ergab sich, dass nur bei einem von zehn persönlichen Angriffen auch ein Moderator eingriff.
Jigsaw und Wikimedia Foundation sind nicht die ersten, die Hassbotschaften im Internet untersuchen – und auch Softwareansätze gibt es bereits eine ganze Reihe. Doch die "Nastygramm"-Sammlung, die mittels Crowdsourcing erstellt wurde, ist in ihrem Umfang und ihrer Breite bislang einzigartig, wie der Datenforscher Ellery Wulczyn von der Wikimedia Foundation sagt. Und genau solche Informationen brauche es, um die Algorithmen zu inspirieren.
Wulczyn schätzt, dass die Sammlung persönlicher Angriffe und negativer Kommentare aus der Wikipedia zwischen 10 und 100 Mal größer ist als bisher verfügbare Datenbestände. Und je mehr Daten vorhanden sind, desto genauer lassen sich Algorithmen trainieren und Filter verbessern.
Mehr dazu bei Technology Review Online:
(bsc)
